NLP-08textRNN
Posted yifanrensheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP-08textRNN相关的知识,希望对你有一定的参考价值。
目录
- textRNN简介
- textRNN网络结构
- 总结
一句话简介:textRNN指的是利用RNN循环神经网络解决文本分类问题,通常使用LSTM和GRU这种变形的RNN,而且使用双向,两层架构居多。
? ?
一、textRNN简介
这里的文本可以一个句子,文档(短文本,若干句子)或篇章(长文本),因此每段文本的长度都不尽相同。在对文本进行分类时,我们一般会指定一个固定的输入序列/文本长度:该长度可以是最长文本/序列的长度,此时其他所有文本/序列都要进行填充以达到该长度;该长度也可以是训练集中所有文本/序列长度的均值,此时对于过长的文本/序列需要进行截断,过短的文本则进行填充。
总之,要使得训练集中所有的文本/序列长度相同,该长度除之前提到的设置外,也可以是其他任意合理的数值。在测试时,也需要对测试集中的文本/序列做同样的处理。根据RNN的原理,TestRNN也类似:
- 训练集中所有文本/序列的长度统一为n,我们需要对文本进行分词,并使用词嵌入得到每个词固定维度的向量表示。
- 对于每一个输入文本/序列,我们可以在RNN的每一个时间步长上输入文本中一个单词的向量表示,计算当前时间步长上的隐藏状态,然后用于当前时间步骤的输出以及传递给下一个时间步长并和下一个单词的词向量一起作为RNN单元输入
- 再计算下一个时间步长上RNN的隐藏状态
- 以此重复…直到处理完输入文本中的每一个单词,由于输入文本的长度为n,所以要经历n个时间步长。
基于RNN的文本分类模型非常灵活,有多种多样的结构。接下来,我们主要介绍两种典型的结构。
二、textRNN网络结构
2.1 structure 1
流程:embedding—>BiLSTM—>concat final output/average all output—–>softmax layer
结构图如下图所示:
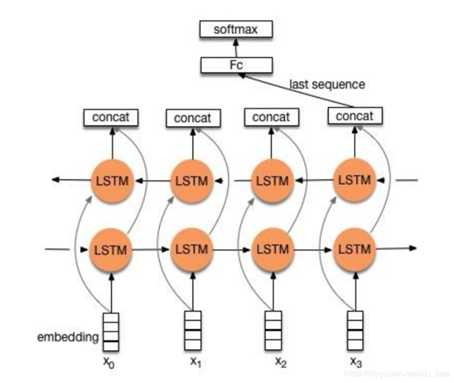
两种形式:
- 一般取前向/反向LSTM在最后一个时间步长上隐藏状态,然后进行拼接,在经过一个softmax层(输出层使用softmax激活函数)进行一个多分类;
- 取前向/反向LSTM在每一个时间步长上的隐藏状态,对每一个时间步长上的两个隐藏状态进行拼接,然后对所有时间步长上拼接后的隐藏状态取均值,再经过一个softmax层(输出层使用softmax激活函数)进行一个多分类(2分类的话使用sigmoid激活函数)。
上述结构也可以添加dropout/L2正则化或BatchNormalization 来防止过拟合以及加速模型训练。
2.2 structure 2
流程:embedding–>BiLSTM—->(dropout)–>concat ouput—>UniLSTM—>(droput)–>softmax layer
结构图如下图所示:
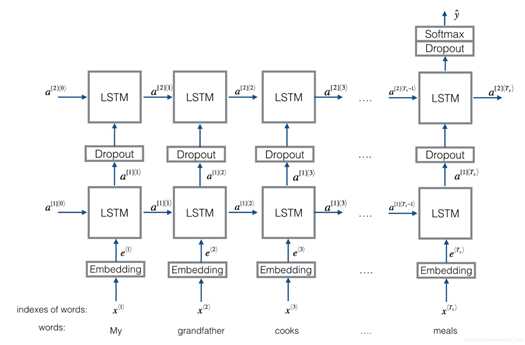
与之前结构不同的是,在双向LSTM(上图不太准确,底层应该是一个双向LSTM)的基础上又堆叠了一个单向的LSTM。把双向LSTM在每一个时间步长上的两个隐藏状态进行拼接,作为上层单向LSTM每一个时间步长上的一个输入,最后取上层单向LSTM最后一个时间步长上的隐藏状态,再经过一个softmax层(输出层使用softamx激活函数,2分类的话则使用sigmoid)进行一个多分类。
三、总结
TextRNN的结构非常灵活,可以任意改变。比如把LSTM单元替换为GRU单元,把双向改为单向,添加dropout或BatchNormalization以及再多堆叠一层等等。TextRNN在文本分类任务上的效果非常好,与TextCNN不相上下,但RNN不能串行运算,训练速度相对偏慢,一般2层就已经足够多了。
参考文献
【1】论文 :
A Bi-LSTM-RNN Model for Relation Classification Using Low-Cost Sequence Features: https://arxiv.org/abs/1608.07720
Recurrent Neural Network for Text Classification with Multi-Task Learning: https://arxiv.org/abs/1605.05101
【2】代码参考:https://www.cnblogs.com/Luv-GEM/p/10836454.html
以上是关于NLP-08textRNN的主要内容,如果未能解决你的问题,请参考以下文章