使用NLP检测和对抗AI生成的假新闻
Posted panchuangai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用NLP检测和对抗AI生成的假新闻相关的知识,希望对你有一定的参考价值。
作者|MOHD SANAD ZAKI RIZVI
编译|VK
来源|Analytics Vidhya
概述
- 由AI生成的假新闻(神经假新闻)对于我们的社会可能是一个巨大的问题
- 本文讨论了不同的自然语言处理方法,以开发出对神经假新闻的强大防御,包括使用GPT-2检测器模型和Grover(AllenNLP)
- 每位数据科学专业人员都应了解什么是神经假新闻以及如何应对它
介绍
假新闻是当今社会关注的主要问题。它与数据驱动时代的兴起并驾齐驱,这并非巧合!
假新闻是如此广泛,以至于世界领先的字典都试图以自己的方式与之抗争。
- Dictionary.com将misinformation‘列为2018年度最佳词汇
- 牛津词典几年前选择“post-truth”作为年度最佳词汇

那么机器学习在其中扮演了什么角色呢?我相信你一定听说过一种机器学习技术,它甚至可以生成模仿名人的假视频。类似地,自然语言处理(NLP)技术也被用来生成假文章,这一概念被称为“神经假新闻”。
过去几年,我一直在自然语言处理(NLP)领域工作,虽然我喜欢取得突破性进展的速度,但我也对这些NLP框架被用来创建和传播虚假信息的方式深感担忧。
高级的预训练NLP模型,如BERT,GPT-2,XLNet等,很容易被任何人下载。这就加大了他们被利用来传播宣传和社会混乱的风险。
在这篇文章中,我将对神经假新闻做一个全面的研究——从定义它是什么,到理解识别这种错误信息的某些方法。我们还将详细了解这些最先进的语言模型本身的内部工作原理。
目录
-
什么是神经假新闻?
-
大型语言模型如何被滥用来产生神经假新闻?
-
如何检测神经假新闻?
-
事实核查
-
使用GLTR(HarvardNLP)进行统计分析
-
利用模型检测神经假新闻
- GPT-2探测器
- Grover 模型
-
-
当前检测技术的局限性及未来研究方向
什么是神经假新闻?
我相信你最近听说过“假新闻”这个词。它几乎在每个社交媒体平台上都广泛使用。近年来,它已成为社会和政治威胁的代名词。但什么是假新闻?
以下是维基百科的定义:
“假新闻(又称垃圾新闻、假新闻或骗局新闻)是指通过传统新闻媒体(印刷和广播)或在线社交媒体故意造谣传播的新闻形式。”
假新闻是指任何事实上错误的、歪曲事实的、病毒性传播(或可能传播给目标受众)的新闻。它既可以通过常规新闻媒体传播,也可以在Facebook、Twitter、WhatsApp等社交媒体平台上传播。
假新闻,如“登月是假的”难以区分的原因是,它仔细模仿了真实新闻通常遵循的“风格”和“模式”。这就是为什么未经训练的人眼很难分辨。
另外,有趣的是,假新闻已经存在了很长很长时间(实际上,贯穿我们的历史)。
神经假新闻
神经假新闻是利用神经网络模型生成的任何假新闻。或者更正式地定义它:
神经假新闻是一种有针对性的宣传,它紧密模仿由神经网络生成的真实新闻的风格。
下面是OpenAI的GPT-2模型生成的神经假新闻的一个例子:

“system prompt”是一个人给模型的输入,“model completion”是GPT-2模型生成的文本。
你凭直觉猜到后一部分是机器写的吗?请注意,该模型能够多么令人难以置信地将提示进行扩展,形成一个完整故事,这看起来乍一看令人信服。
现在,如果我告诉你GPT-2模型可以免费供任何人下载和运行呢?这正是研究界关注的问题,也是我决定写这篇文章的原因。
大型语言模型如何被滥用来产生神经假新闻?
语言建模是一种NLP技术,模型通过从句子本身理解上下文来学习预测句子中的下一个单词或缺失的单词。以谷歌搜索为例:
这是一个正在运行的语言模型的例子。通过让模型预测一个句子中的下一个单词或一个丢失的单词,我们让模型学习语言本身的复杂性。
这个模型能够理解语法是如何工作的,不同的写作风格,等等。这就是为什么这个模型能够生成一段对未经训练的人来说可信的文本。当同样的模式被用来产生有针对性的宣传来迷惑人们时,问题就出现了。
下面是一些非常强大的最先进的语言模型,它们非常擅长生成文本。
1.谷歌的BERT
BERT是一个由Google设计的语言模型,它打破了最先进的记录。该框架是最近各种研究实验室和公司大力训练和研究大型语言模型的原因。
BERT和Facebook、XLM、XLNet、DistilBERT等公司的RoBERTa在文本生成方面表现非常出色。
2.OpenAI的GPT-2模型
来自OpenAI的GPT、GPT-2和GPT-Large等一系列语言模型,因其文本生成能力而在媒体上引起轰动。这些是我们绝对应该知道的一些语言模型。
3.Grover
Grover是AllenNLP提出的一个有趣的新语言模型,它不仅能够生成文本,而且能够识别其他模型生成的伪文本。
我们将在文章的后面进一步了解Grover。
如何检测神经假新闻?
我们怎样才能发现或找出一条新闻是假的?目前,处理神经假新闻的方法主要有三种,都取得了很好的效果。
I.事实核查
检查一条在网上传播的新闻是假的还是真的,最基本的方式是什么?我们可以简单地谷歌它,参考值得信赖的新闻网站,并事实检查他们是否有相同或类似的故事。

尽管这一步让人感觉像是常识,但它实际上是确保一条新闻真实性的最有效方法之一。
但这一步只处理一种虚假新闻:来自单一来源的新闻。如果我们想处理那些已经走红并被我们周围的媒体大量报道的新闻呢?
这通常是一种由神经网络生成的新闻,因为新闻在“风格”和“结构”上与真实新闻非常相似。
让我们学习一些处理“机器生成”文本的方法。
II.使用GLTR(HarvardNLP)进行统计分析
GLTR是由HarvardNLP和MIT-IBM Watson实验室的专家们设计的一个工具。
GLTR用于识别机器生成文本的主要方法是通过对给定文本进行的统计分析和可视化。
下面是GLTR接口:

GLTR检测生成的文本的中心思想是使用最初用于生成该文本片段的相同(或类似)模型。
原因很简单,一个语言模型直接生成的单词来自于它从训练数据中学习到的概率分布。
下面是一个示例,请注意语言模型如何生成一个概率分布,作为对所有可能单词具有不同概率的输出:
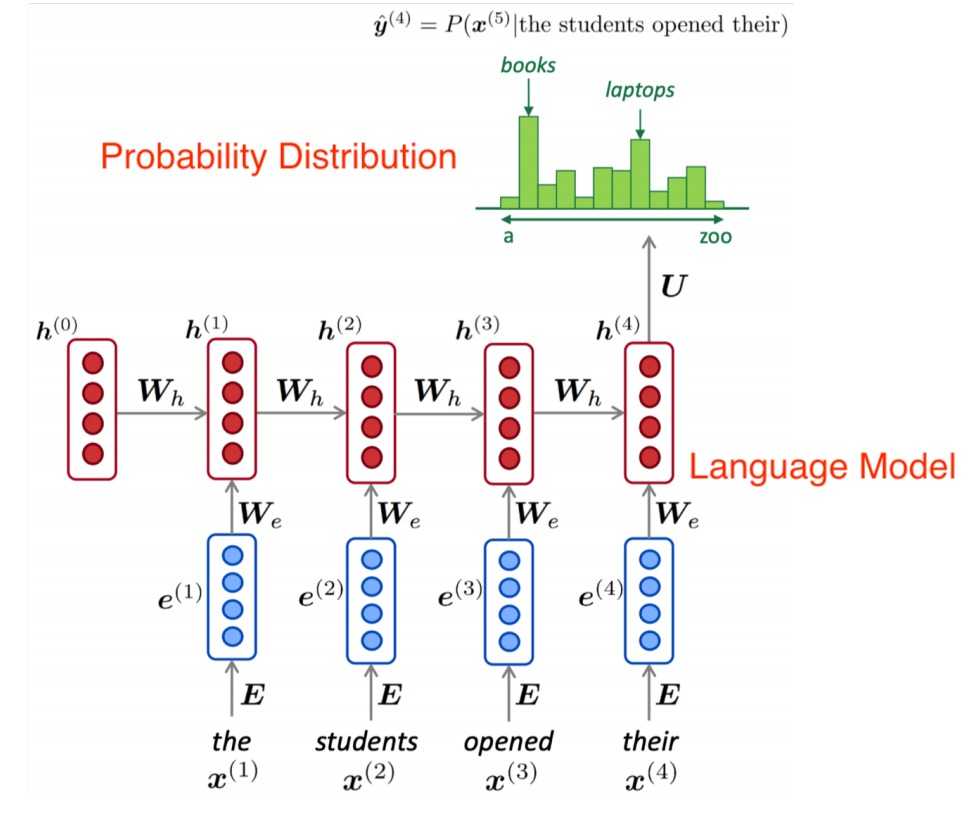
由于我们已经知道从给定的概率分布中抽取单词的技术,如最大抽样、k-max抽样、波束搜索、核抽样等,我们可以很容易地交叉检查给定文本中的单词是否遵循特定的分布。
如果是的话,而且在给定的文本中有多个这样的单词,那么这基本上可以确认它是机器生成的。
让我们用一个例子运行GLTR来理解这个概念!
安装GLTR
在使用GLTR之前,我们需要在系统上安装它。首先克隆项目的GitHub存储库:
git clone https://github.com/HendrikStrobelt/detecting-fake-text.git
克隆存储库后,将cd放入其中并执行pip安装:
cd detecting-fake-text && pip install -r requirements.txt
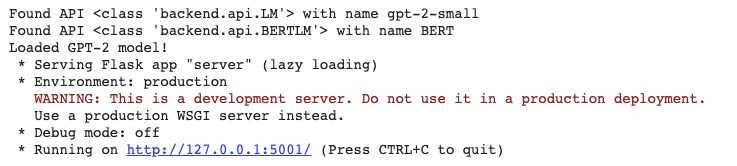
接下来,下载预先训练好的语言模型。可以通过运行服务器来完成此操作:
python server.py
GLTR目前支持两种模型:BERT和GPT-2。你可以在两者之间进行选择;如果未提供任何选项,则使用GPT-2:
python server.py --model BERT
这将开始在你的机器上下载相应的预训练模型。如果你的网速很慢,给它点时间。
当一切就绪时,服务器将从端口5001启动,你可以直接转到http://localhost:5001访问它:
GLTR是如何工作的?
假设我们有下面这段文字。我们要检查它是否由GPT-2这样的语言模型生成:
How much wood would a woodchuck chuck if a woodchuck could chuck wood?
GLTR将接受这个输入并分析GPT-2对每个输入位置的预测。
请记住,语言模型的输出是该模型知道的所有单词的排名,因此,我们根据GPT-2的排名将能够迅速查看输入文本中每个单词。
如果我们根据每个单词在前10名中是否是绿色、前100名中是否是黄色和前1000名中是否是红色对其进行颜色编码,我们将得到以下输出:

现在,我们可以直观地看到,根据GPT-2,每个单词的可能性有多大。根据模型,绿色和黄色是很有可能的,而红色是意料之外的词,这意味着它们很可能是由人类书写的。这正是你将在GLTR接口上看到的!
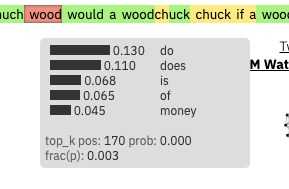
如果你需要更多的信息,你可以把鼠标悬停在“wood”这个词上。你会看到一个小盒子,上面有这个位置的前5个预测词及其概率:
我鼓励你尝试不同的文本,可以是人类产生的或者机器产生的。GLTR工具本身也已经提供了一些示例:

你会注意到,当你移到真正的文本时,红色和紫色的单词数量,即不太可能或罕见的预测,会增加。
此外,GLTR还显示了三种不同的直方图,其中包含整个文本的聚合信息(请查看下面的图片以供参考):
-
第一个显示每个类别(前10个、前100个和前1000个)在文本中出现的单词数
-
第二个例子说明了前一个预测词和后一个预测词的概率之比
-
第三个直方图显示了预测熵的分布。低不确定性意味着模型对每个预测都非常有信心,而高不确定性意味着低信心
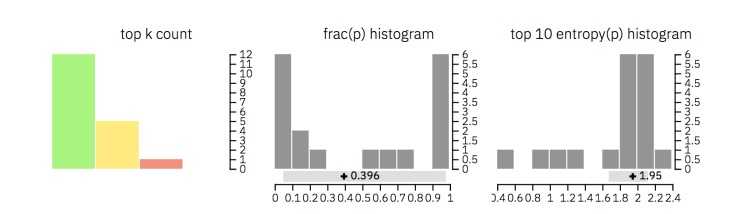
以下是这些直方图的帮助:
-
前两个柱状图有助于理解输入文本中的单词是否从分布的顶部取样(对于机器生成的文本,基本上就是从分布顶部采样)
-
最后一个直方图说明单词的上下文是否为检测系统所熟知(对于机器生成的文本,基本上就是熟知)
GLTR模型将这些多重可视化和概率分布知识结合起来,可以作为一种有效的法医学工具来理解和识别机器生成的文本。
以下是对GLTR的报道:
“在一项人类受试者研究中,我们发现GLTR提供的注释方案在不经过任何训练的情况下将人类对假文本的检测率从54%提高到72%。”–Gehrmann等人
你可以在最初的研究论文中阅读更多关于GLTR的内容:https://arxiv.org/pdf/1906.04043.pdf。
利用模型检测神经假新闻
GLTR是相当令人印象深刻的,因为它使用概率分布和可视化的简单知识来检测神经假新闻。但如果我们能做得更好呢
如果我们能训练一个大的模型来预测一段文字是否是神经假新闻呢?
好吧,这正是我们在这一节要学的
GPT-2 探测器
GPT-2检测器模型是一个RoBERTa(BERT的变种)模型,它经过微调以预测给定的文本是否是使用GPT-2生成的(作为一个简单的分类问题)。
RoBERTa是Facebook人工智能研究开发的一个大型语言模型,是对Google的BERT的改进。这就是为什么这两个框架有很大的相似之处。
这里需要注意的一点是,尽管RoBERTa的模型结构与GPT-2的模型结构非常不同,因为前者是一个屏蔽语言模型(如BERT),与GPT-2不同,前者在本质上不是生成的。GPT-2在识别由它生成的神经假新闻方面仍然显示了大约95%的准确性。
这个模型的另一个优点是,与我们在本文中讨论的其他方法相比,它的预测速度非常快。
让我们看看它!
安装GPT-2探测器模型
这个探测器模型的安装步骤非常简单,就像GLTR一样。
我们首先需要克隆存储库:
git clone https://github.com/openai/gpt-2-output-dataset.git
然后
cd gpt-2-output-dataset/ && pip install -r requirements.txt
接下来,我们需要下载预训练好的语言模型。通过运行以下命令执行此操作:
wget https://storage.googleapis.com/gpt-2/detector-models/v1/detector-base.pt
这一步可能需要一些时间。完成后,你可以启动探测器:
python -m detector.server detector-base.pt --port 8000
一切就绪后,服务器将从端口8000启动,你可以直接转到http://localhost:8000访问它!

有了这个,你就可以尝试GPT-2探测器模型了!
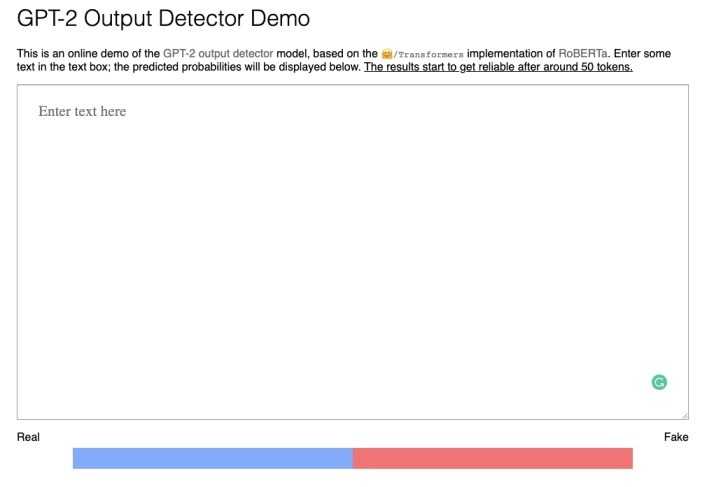
识别神经假新闻
探测器模型的接口非常简单。我们只需复制粘贴一段文本,它就会告诉我们它是“真的”还是“假的”,这取决于它是否由机器(GPT-2模型)生成。
以下是我使用Transformers 2.0库从GPT-2生成的文本:

如你所见,尽管文本看起来很有说服力和连贯性,但模型直接将其归类为“假的”,准确率为99.97%。
这是一个非常有趣的工具使用,我建议你去尝试不同的例子,生成和未生成的文本,看看它如何执行!
在我的例子中,我通常注意到这个模型只能很好地识别GPT-2模型生成的文本。这与Grover完全不同,Grover是我们将在下一节中学习的另一个框架。Grover可以识别由各种语言模型生成的文本。
你可以在Facebook的博客上阅读更多关于RoBERTa的架构和训练方法。如果你对如何实现检测器模型感到好奇,可以在GitHub上检查代码。
Grover
Grover是我在本文讨论的所有选项中最喜欢的工具。与GLTR和GPT-2检测器模型仅限于特定模型不同,它能够将一段文本识别为由大量多种语言模型生成的伪文本。
作者认为,检测一段文本作为神经假新闻的最佳方法是使用一个模型,该模型本身就是一个能够生成此类文本的生成器。用他们自己的话说:
“生成器最熟悉自己的习惯、怪癖和特性,也最熟悉类似人工智能模型的特性,特别是那些接受过类似数据训练的人工智能模型。”–Zellers等人
乍一看听起来有违直觉,不是吗?为了建立一个能够检测出神经假新闻的模型,他们继续开发了一个模型,这个模型一开始就非常擅长生成这样的假新闻!
听起来很疯狂,但背后有自己的一个科学逻辑。
Grove是怎么工作的?
问题定义
Grover将检测神经假新闻的任务定义为一个具有两个模型的对抗游戏:
-
设置中有两个模型用于生成和检测文本
-
对抗模型的目标是产生虚假的新闻,这些新闻可以是病毒性传播的,或者对人类和验证模型都有足够的说服力
-
验证器对给定文本是真是假进行分类:

- 验证者的训练数据包括无限的真实新闻,但只有一些来自特定对手的假新闻
- 这样做是为了复制真实世界的场景,在真实世界中,对手提供的虚假新闻数量与真实新闻相比要少得多
这两种模式的双重目标意味着,攻击者和捍卫者之间在“竞争”,既产生虚假新闻,又同时发现虚假新闻。随着验证模型的改进,对抗模型也在改进。
神经假新闻的条件生成
神经假新闻的最明显特征之一是它通常是“有针对性的”内容,例如点击诱饵或宣传,大多数语言模型(例如BERT等)都不允许我们创建这种受控文本。
Grover支持“受控”文本生成。这仅仅意味着除了模型的输入文本之外,我们可以在生成阶段提供额外的参数。这些参数将引导模型生成特定的文本。
但这些参数是什么?考虑一下新闻文章——有助于定义新闻文章的结构参数是什么?以下是Grover的作者认为生成文章所必需的一些参数:
-
领域:文章发布的地方,它间接地影响样式
-
日期:出版日期
-
作者:作者姓名
-
标题:文章的标题,这影响到文章的生成
-
正文:文章的正文
结合所有这些参数,我们可以通过联合概率分布对一篇文章进行建模:

现在,我将不再深入讨论如何实现这一点的基础数学,因为这超出了本文的范围。但是,为了让你了解整个生成过程的样子,这里有一个示意图:
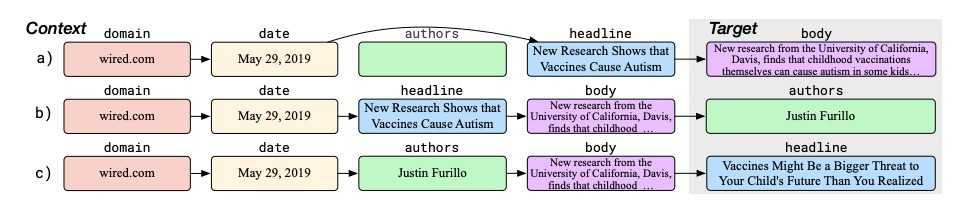
下面是流程:
-
在a行中,正文由部分上下文生成(缺少作者字段)
-
在b行中,模型生成作者
-
在c行中,该模型重新生成提供的标题,使之更为真实
架构和数据集
Grover使用与GPT2相同的架构:
-
有三种型号。最小的模型Grover-Base有12层,1.24亿个参数,与GPT和BERT-Base相当
-
下一个模型Grover Large有24个层和3.55亿个参数,与BERT Large相当
-
最大的模型Grover Mega有48层和15亿个参数,与GPT2相当
用来训练Grover的RealNews数据集是Grover的作者自己创建的。数据集和创建它的代码是开源的,因此你可以下载并按原样使用它,也可以按照Grover的规范生成自己的数据集。
安装Grover
你可以按照安装说明安装Grover,并在自己的机器上运行它的生成器和检测器工具。请记住,该模型的大小是巨大的(压缩后还有46.2G!)所以在你的系统上安装它可能是一个挑战。
这就是为什么我们会使用在线检测器和生成器工具。
使用Grover进行生成和检测
你可以通过以下链接访问该工具:
https://grover.allenai.org/
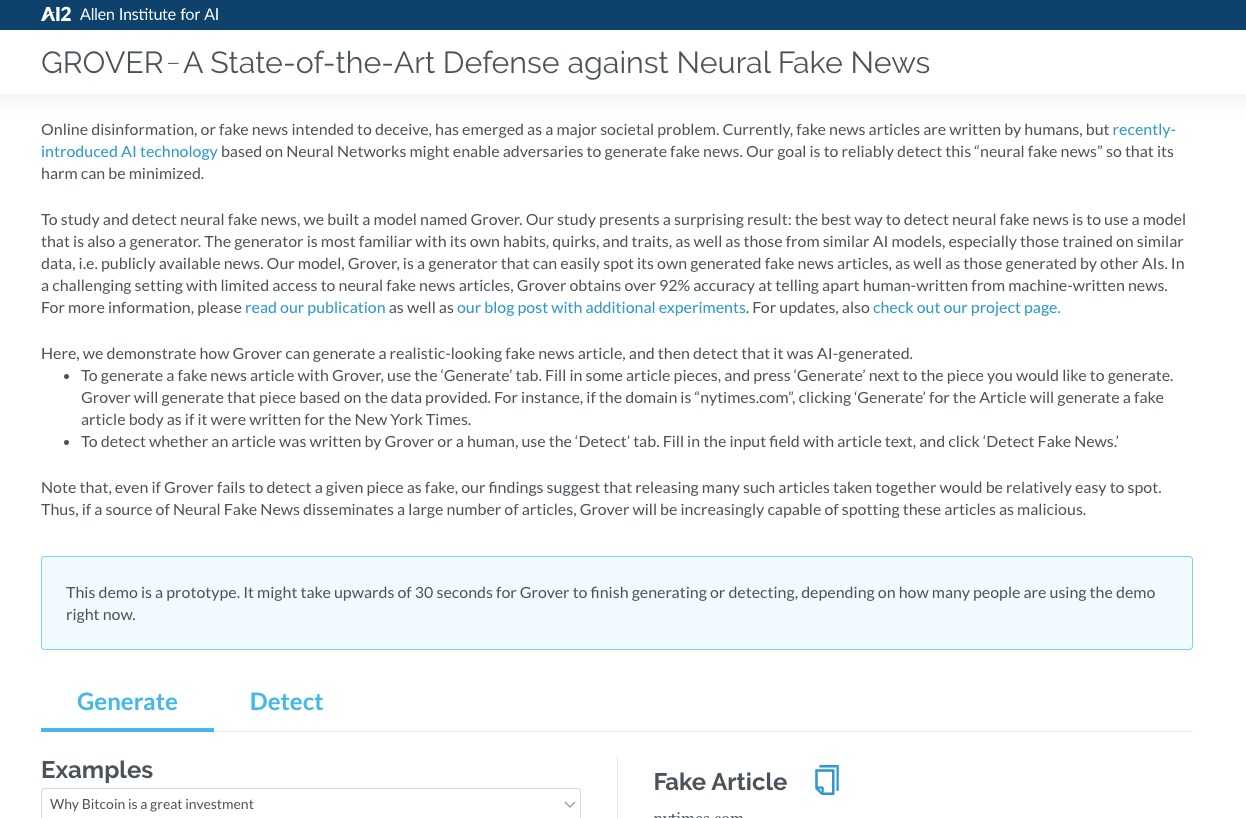
你可以玩一下Generate选项,看看Grover生成神经假新闻的能力有多强。因为我们有兴趣检查Grover的检测能力,所以让我们转到“检测”选项卡(或转到以下链接):
https://grover.allenai.org/detect
案例研究1:
我们要测试的文本与前面看到的GPT-2生成的文本相同:
当你点击“检测假新闻”按钮时,你会注意到Grover很容易将其识别为机器生成的:

案例研究2:
我们要测试的下一篇文章来自纽约时报:
你会发现格罗弗确实能认出它是一个人写的:

案例研究3:
这些都是简单的例子。如果我给它一段技术性的文字怎么办?像技术博客里的解释
对于我自己提供的文本,Grover失败了,因为它没有接受过此类技术文章的训练:
但是GPT-2探测器模型却起作用了,因为它是在各种各样的网页上被训练的(800万!)。

这只是为了表明没有一个工具是完美的。
案例研究4:
她是我们要做的最后一个实验。我们将测试机器生成的新闻,这些新闻不是“假的”,只是自动生成新闻的一个例子。本文摘自华盛顿邮报:
有趣的是,GPT-2探测器模型说它根本不是机器生成的新闻:

但同时,Grover能够识别出它是机器编写的文本,概率略低(但它还是能找出答案!):

现在,不管你是否认为这是“假”新闻,事实是它是由机器生成的。如何对这类文本进行分类将取决于你的目标是什么以及你的项目试图实现什么。
简而言之,检测神经假新闻的最佳方法是综合运用所有这些工具并得出比较结论。
当前虚假新闻检测技术的局限性及未来研究方向
很明显,目前的检测技术还不完善,还有发展的空间。麻省理工学院计算机科学与人工智能实验室(CSAIL)最近对现有的神经假新闻检测方法进行了研究,他们的一些发现令人大开眼界。
现有神经假新闻检测技术的局限性
研究的主要结论是,GLTR、Grover等方法用于神经假新闻检测的现有方法是不完全的。
这是因为仅仅发现一条文本是否是“机器生成”是不够的,可能有一条合法的新闻是通过诸如自动完成、文本摘要等工具机器生成的。
例如,著名的写作应用程序Grammarly使用某种形式的GPT-2来帮助纠正文本中的语法错误。
这类案例的另一个例子是本文前一节的案例研究4,其中一个程序被《华盛顿邮报》用来生成体育新闻。
反之,也可能存在被攻击者轻微破坏/修改的人工文本,根据现有方法,这些文本将被归类为非神经假新闻。
下面是一个例子,总结了探测器模型的上述困境:
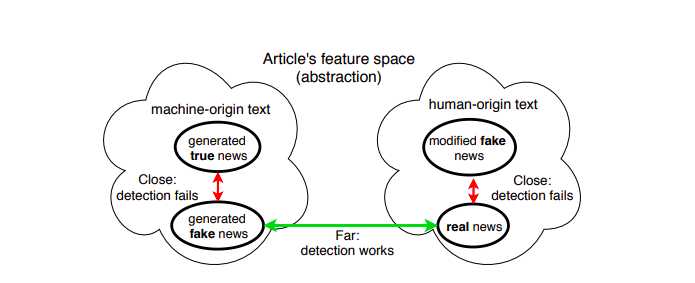
从上图中可以清楚地看到,由于生成的神经假新闻和真实新闻的特征空间非常远,所以模型很容易对哪一个是假的进行分类。
此外,当模型必须在真实生成的新闻和神经假新闻之间进行分类时(如我们之前看到的案例研究4),由于两者的特征空间非常接近,因此模型无法检测。
当模型必须区分生成的人工新闻和经过一点修改而变成假的新闻时,也会看到同样的行为。
我不想详细介绍,但作者进行了多次实验得出这些结论,你可以阅读他们的论文了解更多:https://arxiv.org/pdf/1908.09805.pdf。
这些结果使作者得出结论,为了定义/检测神经假新闻,我们必须考虑真实性,而不是来源(来源,无论是机器写的还是人类写的)。
我认为这是一个让我们大开眼界的结论。
未来的研究方向是什么
处理神经假新闻问题的一个步骤是,剑桥大学和亚马逊去年发布了FEVER,这是世界上最大的事实核查数据集,可用于训练神经网络检测假新闻。

尽管由麻省理工学院的同一个研究小组(Schuster等人)分析FEVER时,他们发现FEVER数据集存在某些偏差,使得神经网络更容易通过文本中的模式来检测假文本。当他们纠正了数据集中的一些偏差时,他们发现模型的准确性如预期的那样急剧下降。
然后,他们将GitHub上对称的修正后的数据集热开源,作为其他研究人员测试其模型的基准,我认为这对正在积极尝试解决神经假新闻问题的整个研究界来说是一个好的举措。
如果你有兴趣找到更多关于他们的方法和实验的信息,请阅读他们的原始论文:https://arxiv.org/pdf/1908.05267.pdf。
因此,创建大规模无偏数据集,我认为是未来研究如何处理神经假新闻方向的良好第一步,因为随着数据集的增加,研究人员和组织建立模型以改进现有基准的兴趣也会增加。这和我们过去几年在NLP(GLUE, SQUAD)和CV(ImageNet)中看到的一样。
除此之外,当我考虑到我们所遇到的大多数研究时,这里有一些我们可以进一步探索的方向:
-
我个人认为,像Grover和GLTR这样的工具是检测神经假新闻的良好起点,它们为我们如何创造性地利用现有知识构建能够检测假新闻的系统树立了榜样。因此,我们需要在这个方向上进行进一步的研究,改进现有的工具,并不仅针对数据集,而且在现实环境中更有效地验证它们。
-
FEVER数据集的发布是一个值得欢迎的举动,它将有助于我们在各种环境中探索和构建更多这样的带有假新闻的数据集,因为这将直接推动进一步的研究。
-
通过模型发现文本的准确性是一个具有挑战性的问题,但是我们需要以某种方式构造它,以便更容易创建有助于训练能够根据文本的真实性对其进行身份验证的模型的数据集。因此,这方面的进一步研究是值得欢迎的。
-
正如Grover和GLTR的作者正确地提到的那样,我们需要通过在未来发布大型语言模型(如GPT-2、Grover等)来继续研究社区的开放性,因为只有当我们知道对手有多强大时,我们才能建立强大的防御。
原文链接:https://www.analyticsvidhya.com/blog/2019/12/detect-fight-neural-fake-news-nlp/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
以上是关于使用NLP检测和对抗AI生成的假新闻的主要内容,如果未能解决你的问题,请参考以下文章