PyTorch深度学习2简单函数使用
Posted jjjpython1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch深度学习2简单函数使用相关的知识,希望对你有一定的参考价值。
这个包八百多,慢慢等,可我寻思着我这pytorch不是装过了么,他又给我来一遍是几个意思
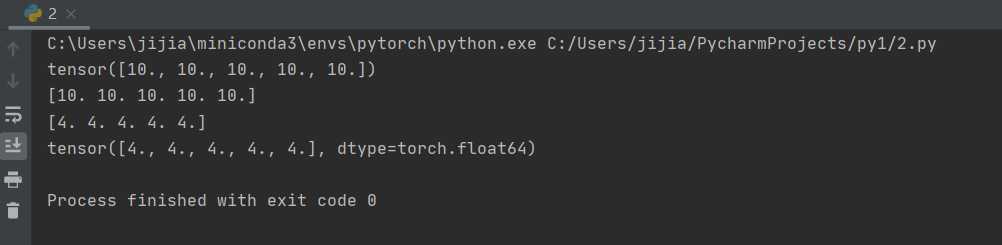
下面是简单的矩阵函数
from __future__ import print_function
import torch
x = torch.Tensor(5, 3) # 构造一个未初始化的5*3的矩阵
x = torch.rand(5, 3) # 构造一个随机初始化的矩阵
x.size()
#NOTE: torch.Size 事实上是一个tuple, 所以其支持相关的操作*
y = torch.rand(5, 3)
#此处 将两个同形矩阵相加有两种语法结构
x + y # 语法一
torch.add(x, y) # 语法二 真就矩阵加法呗
# 另外输出tensor也有两种写法
result = torch.Tensor(5, 3) # 语法一
torch.add(x, y, out=result) # 语法二
y.add_(x) # 将y与x相加
# 特别注明:任何可以改变tensor内容的操作都会在方法名后加一个下划线‘_‘
# 例如:x.copy_(y), x.t_(), 这俩都会改变x的值。
#另外python中的切片操作也是资次的。
x[:,1] #这一操作会输出x矩阵的第二列的所有值
print(x)#print python唯一指定输出
print(y)
print(x.size())
print(x+y)
真就python yes呗 语法简单到闻着伤心 见者落泪

结果没毛病
PyTorch中的神经网络
接下来介绍pytorch中的神经网络部分。PyTorch中所有的神经网络都来自于autograd包
首先我们来简要的看一下,之后我们将训练我们第一个的神经网络。
Autograd: 自动求导
autograd 包提供Tensor所有操作的自动求导方法。
这是一个运行时定义的框架,这意味着你的反向传播是根据你代码运行的方式来定义的,因此每一轮迭代都可以各不相同。
以这些例子来讲,让我们用更简单的术语来看看这些特性。
autograd.Variable 这是这个包中最核心的类。 它包装了一个Tensor,并且几乎支持所有的定义在其上的操作。一旦完成了你的运算,你可以调用 .backward()来自动计算出所有的梯度。
你可以通过属性 .data 来访问原始的tensor,而关于这一Variable的梯度则集中于 .grad 属性中
如果你想要进行求导计算,你可以在Variable上调用.backward()。 如果Variable是一个标量(例如它包含一个单元素数据),你无需对backward()指定任何参数,然而如果它有更多的元素,你需要指定一个和tensor的形状想匹配的grad_output参数。
注 creator已经变成了grad_fn 也就是函数梯度
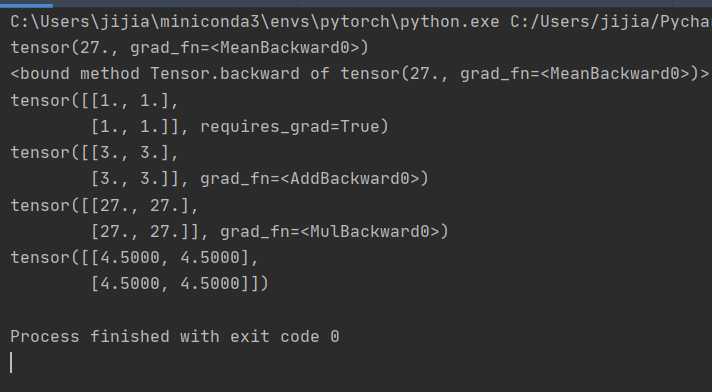
from __future__ import print_function
import torch
from torch.autograd import Variable
x = Variable(torch.ones(2, 2), requires_grad = True)
y = x + 2
y.grad_fn
# y 是作为一个操作的结果创建的因此y有一个grad_fn
z = y * y * 3
out = z.mean()
print(out)
# 现在我们来使用反向传播
out.backward()
print(out.backward)
# out.backward()和操作out.backward(torch.Tensor([1.0]))是等价的
# 在此处输出 d(out)/dx
#手动计算一下 y=x+2 z=out=3x*x + 12x + 12 求导得 dz=6x+12 x=1 z=18 2*2矩阵 结果是18* 1/4 = 4.5 没错
x.grad
print(x)
print(y)
print(z)
print(x.grad)
差点把矩阵系数忘了乘进去了
神经网络
使用 torch.nn 包可以进行神经网络的构建。
现在你对autograd有了初步的了解,而nn建立在autograd的基础上来进行模型的定义和微分。
nn.Module中包含着神经网络的层,同时forward(input)方法能够将output进行返回。
举个例子,来看一下这个数字图像分类的神经网络。
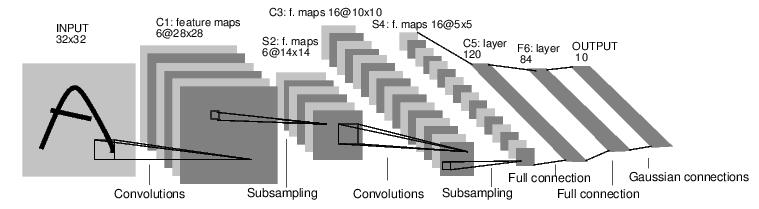
这是一个简单的前馈神经网络。 从前面获取到输入的结果,从一层传递到另一层,最后输出最后结果。
一个典型的神经网络的训练过程是这样的:
- 定义一个有着可学习的参数(或者权重)的神经网络
- 对着一个输入的数据集进行迭代:
- 用神经网络对输入进行处理
- 计算代价值 (对输出值的修正到底有多少)
- 将梯度传播回神经网络的参数中
- 更新网络中的权重
- 通常使用简单的更新规则: weight = weight + learning_rate * gradient
让我们来定义一个神经网络:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5) # 1 input image channel, 6 output channels, 5x5 square convolution kernel
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120) # an affine operation: y = Wx + b
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv2(x)), 2) # If the size is a square you can only specify a single number
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
net = Net()
net
‘‘‘神经网络的输出结果是这样的
Net (
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear (400 -> 120)
(fc2): Linear (120 -> 84)
(fc3): Linear (84 -> 10)
)
‘‘‘
今天就到这了 几个简单函数得学校和使用 一级神经网络的开头以上是关于PyTorch深度学习2简单函数使用的主要内容,如果未能解决你的问题,请参考以下文章