15 手写数字识别-小数据集
Posted zengyf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了15 手写数字识别-小数据集相关的知识,希望对你有一定的参考价值。
作业补交:
https://www.cnblogs.com/zengyf/p/13054699.html
https://www.cnblogs.com/zengyf/p/13054744.html
https://www.cnblogs.com/zengyf/p/13055110.html
https://www.cnblogs.com/zengyf/p/13055257.html
https://www.cnblogs.com/zengyf/p/13055261.html
https://www.cnblogs.com/zengyf/p/13055266.html
https://www.cnblogs.com/zengyf/p/13055551.html
https://www.cnblogs.com/zengyf/p/13055600.html
原因:电脑未带回家。
1.手写数字数据集
- from sklearn.datasets import load_digits
- digits = load_digits()
digits = load_digits() X_data = digits.data.astype(np.float32) Y_data = digits.target.astype(np.float32).reshape(-1, 1)
2.图片数据预处理
- x:归一化MinMaxScaler()
- y:独热编码OneHotEncoder()或to_categorical
- 训练集测试集划分
- 张量结构
# 将属性缩放到一个指定的最大和最小值(通常是1-0之间)
scaler = MinMaxScaler()
X_data = scaler.fit_transform(X_data)
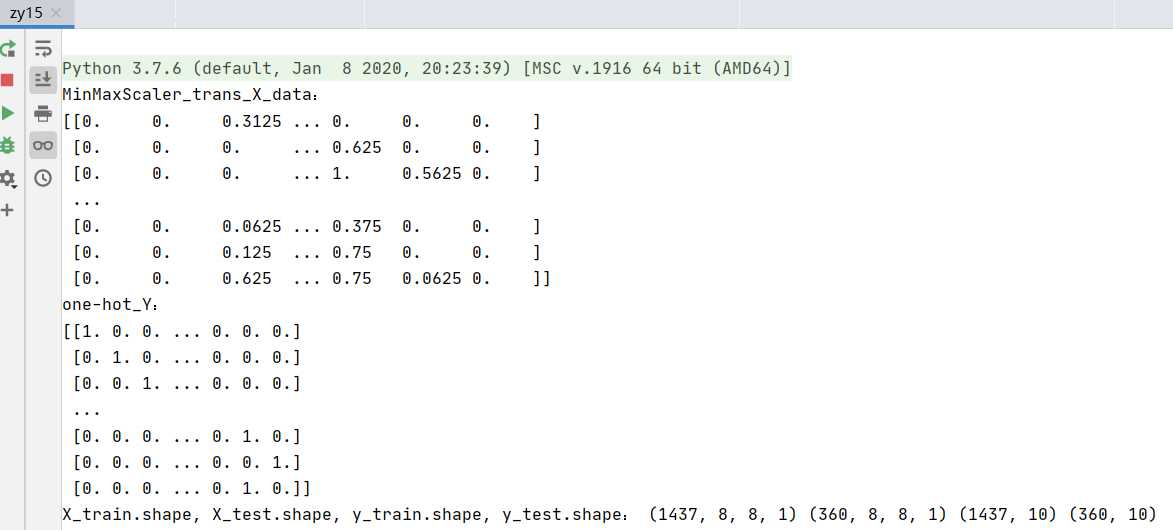
print("MinMaxScaler_trans_X_data:")
print(X_data)
Y = OneHotEncoder().fit_transform(Y_data).todense()# 进行one-hot编码
print("one-hot_Y:")
print(Y)
# 转换为图片的格式
X = X_data.reshape(-1, 8, 8, 1)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=0, stratify=Y)
print(‘X_train.shape, X_test.shape, y_train.shape, y_test.shape:‘, X_train.shape, X_test.shape, y_train.shape, y_test.shape)
运行图:
3.设计卷积神经网络结构
- 绘制模型结构图,并说明设计依据。
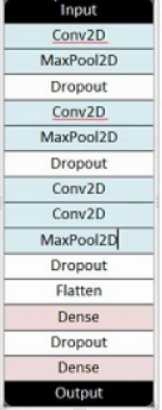
-
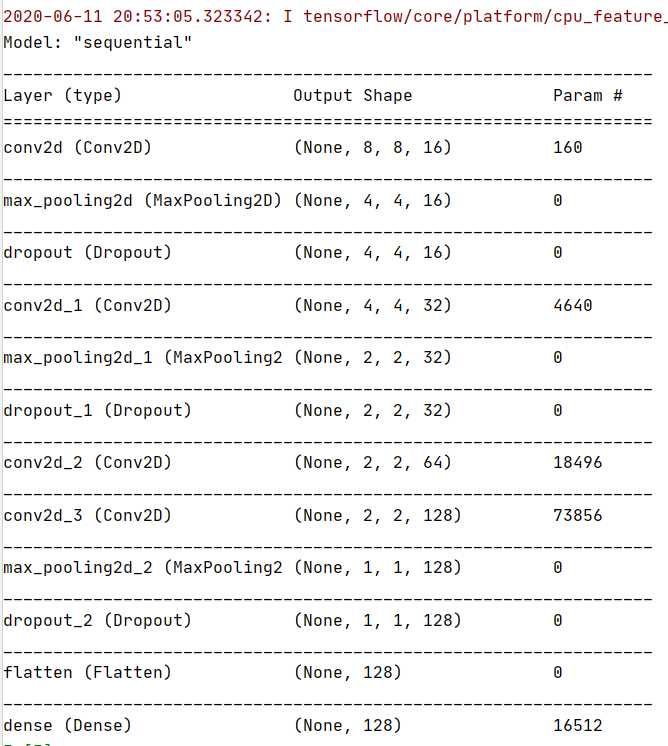
model = Sequential() ks = (3, 3) # 卷积核的大小 input_shape = X_train.shape[1:] model.add(Conv2D(filters=16, kernel_size=ks, padding=‘same‘, input_shape=input_shape, activation=‘relu‘))# 一层卷积,padding=‘same‘,tensorflow会对输入自动补0 model.add(MaxPool2D(pool_size=(2, 2)))# 池化层1 model.add(Dropout(0.25))# 防止过拟合,随机丢掉连接 model.add(Conv2D(filters=32, kernel_size=ks, padding=‘same‘, activation=‘relu‘))# 二层卷积 model.add(MaxPool2D(pool_size=(2, 2)))# 池化层2 model.add(Dropout(0.25)) model.add(Conv2D(filters=64, kernel_size=ks, padding=‘same‘, activation=‘relu‘))# 三层卷积 model.add(Conv2D(filters=128, kernel_size=ks, padding=‘same‘, activation=‘relu‘))# 四层卷积 model.add(MaxPool2D(pool_size=(2, 2)))# 池化层3 model.add(Dropout(0.25)) model.add(Flatten())# 平坦层 model.add(Dense(128, activation=‘relu‘))# 全连接层 model.add(Dropout(0.25)) model.add(Dense(10, activation=‘softmax‘))# 激活函数softmax model.summary()
运行图:

4.模型训练
- model.compile(loss=‘categorical_crossentropy‘, optimizer=‘adam‘, metrics=[‘accuracy‘])
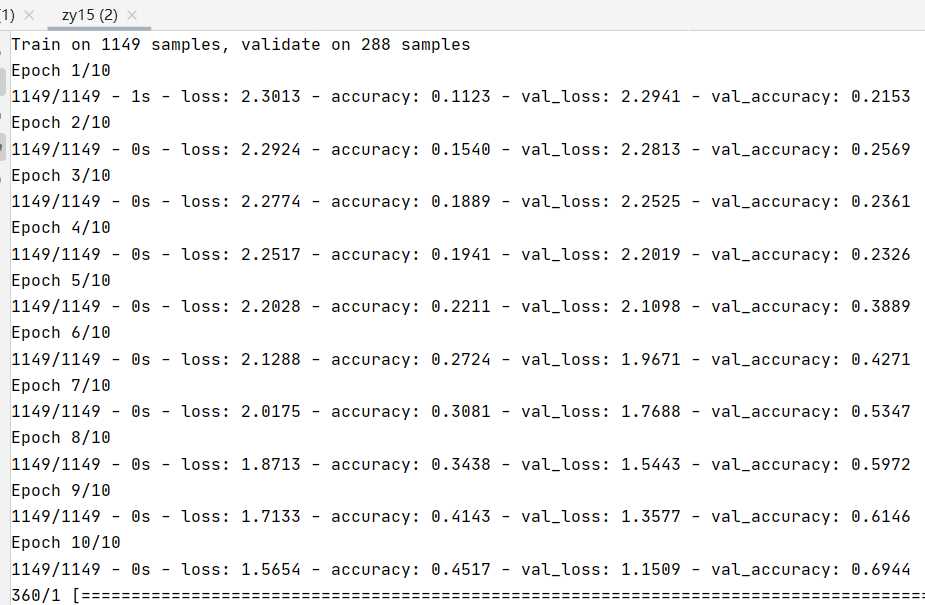
- train_histor:y = model.fit(x=X_train,y=y_train,validation_split=0.2, batch_size=300,epochs=10,verbose=2)
-
# 训练 model.compile(loss=‘categorical_crossentropy‘, optimizer=‘adam‘, metrics=[‘accuracy‘]) train_history = model.fit(x=X_train, y=y_train, validation_split=0.2, batch_size=300, epochs=10, verbose=2) score = model.evaluate(X_test,y_test) score
运行图:
5.模型评价
- model.evaluate()
- 交叉表与交叉矩阵
- pandas.crosstab
- seaborn.heatmap
-
# 模型评价
score = model.evaluate(X_test, y_test)
print(‘score:‘, score)
# 预测值
y_pred = model.predict_classes(X_test)
print(‘y_pred:‘, y_pred[:10])
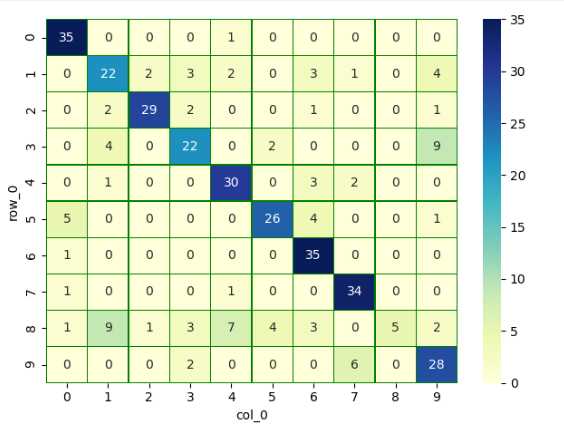
# 交叉表与交叉矩阵
y_test1 = np.argmax(y_test, axis=1).reshape(-1)
y_true = np.array(y_test1)[0]
# 交叉表查看预测数据与原数据对比
pd.crosstab(y_true, y_pred, rownames=[‘true‘], colnames=[‘predict‘])# 交叉矩阵
y_test1 = y_test1.tolist()[0]
a = pd.crosstab(np.array(y_test1), y_pred)
df = pd.DataFrame(a)
sns.heatmap(df, annot=True, cmap="YlGnBu", linewidths=0.2, linecolor=‘G‘)
plt.show()运行图:
以上是关于15 手写数字识别-小数据集的主要内容,如果未能解决你的问题,请参考以下文章