爬取诗词名句网数据并做简单数据分析
Posted nmsghgnv
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬取诗词名句网数据并做简单数据分析相关的知识,希望对你有一定的参考价值。
爬取诗词总量为二十九万两千六百零二条数据
一、爬虫编写
目标网站:诗词名句网
环境
window10;
python3.7;
scrapy框架;
mysql数据库;
数据库设计
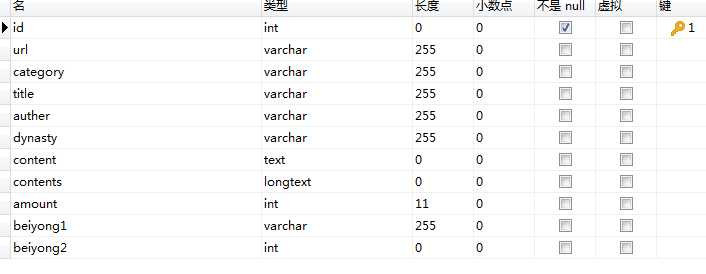
根据要爬取的字段定义,爬取内容为诗词链接,简介,标题,作者,朝代,内容,注释,作者发表的文章数量,图片url
如图
1.创建项目和爬虫文件
scrapy startproject scmjw
cd scmjw
scrapy genspider scmj www.xxx.com
2.定义爬取字段
items.py
import scrapy class ScmjwItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() table = ‘scmjw‘ url = scrapy.Field() category = scrapy.Field() title = scrapy.Field() auther = scrapy.Field() dynasty = scrapy.Field() content = scrapy.Field() contents = scrapy.Field() amount = scrapy.Field() beiyong1 = scrapy.Field()
3.编写爬虫规则
scmj.py
# -*- coding: utf-8 -*- import scrapy from scmjw.items import ScmjwItem class ScmjSpider(scrapy.Spider): name = ‘scmj‘ # allowed_domains = [‘www.shicimingju.com‘] start_urls = [‘http://www.shicimingju.com‘] def parse(self, response): list_urls = response.xpath(‘//div[@id="top_left_menu"]/ul/li‘) for list_url in list_urls: main_list = ‘http://www.shicimingju.com‘ + list_url.xpath(‘./a/@href‘).extract_first() if ‘shicimark‘ in main_list: print(main_list) yield scrapy.Request(url=main_list,callback=self.get_list) if ‘category‘ in main_list: print(main_list) yield scrapy.Request(url=main_list,callback=self.get_list_cate) """爬取分类类别""" def get_list(self,response): div_lists = response.xpath(‘//div[@class="mark_card"]‘) for d in div_lists: item = ScmjwItem() next_url = ‘http://www.shicimingju.com‘ + d.xpath(‘./a/@href‘).extract_first() images = d.xpath(‘./a/img/@src‘).extract_first() item[‘beiyong1‘] = images yield scrapy.Request(url=next_url,callback=self.get_cate,meta={‘item‘:item}) def get_cate(self,response): item = response.meta[‘item‘] next_urls = response.xpath(‘//a[contains(text(), "《") and contains(text(), "》")]‘) item[‘amount‘] = response.xpath(‘//div[@class="card"]/h1/text()‘).re_first(‘d+‘) for n in next_urls: next_url = ‘http://www.shicimingju.com‘ + n.xpath(‘./@href‘).extract_first() yield scrapy.Request(url=next_url,callback=self.get_detail,meta={‘item‘:item}) self_urls = response.xpath(‘//a[contains(text(), "下一页")]/@href‘).extract_first() if self_urls: self_url = ‘http://www.shicimingju.com‘ + self_urls yield scrapy.Request(url=self_url, callback=self.get_cate, meta={‘item‘: item}) def get_detail(self,response): item = response.meta[‘item‘] item[‘url‘] = response.request.url item[‘category‘] = response.xpath(‘//div[@class="shici-mark"]/a/text()‘).extract_first() item[‘title‘] = response.xpath(‘//div[@id="item_div"]/h1/text()‘).extract_first() item[‘auther‘] = response.xpath(‘//div[@class="niandai_zuozhe"]/a/text()‘).extract_first() item[‘dynasty‘] = response.xpath(‘//div[@class="niandai_zuozhe"]/text()‘).extract_first() contents = response.xpath(‘//div[@class="item_content"]//text()‘).extract() content = ‘‘ for c in contents: content += c.strip() + ‘ ‘ item[‘content‘] = content shangxi_contents = response.xpath(‘//div[@class="shangxi_content"]//text()‘).extract() contents = ‘‘ for s in shangxi_contents: contents += s.strip() item[‘contents‘] = contents yield item """爬取作者类别""" def get_list_cate(self,response): div_lists = response.xpath(‘//div[@class="card zuozhe_card"]‘) for d in div_lists: next_url = ‘http://www.shicimingju.com‘ + d.xpath(‘./div[@class="zuozhe_list_item"]/h3/a/@href‘).extract_first() yield scrapy.Request(url=next_url,callback=self.get_zuozhe) self_urls = response.xpath(‘//a[contains(text(), "下一页")]/@href‘).extract_first() if self_urls: self_url = ‘http://www.shicimingju.com‘ + self_urls yield scrapy.Request(url=self_url, callback=self.get_list_cate) def get_zuozhe(self,response): item = ScmjwItem() item[‘amount‘] = response.xpath(‘//div[@class="card shici_card"]/h1/text()‘).re_first(‘d+‘) next_urls = response.xpath(‘//div[@class="shici_list_main"]‘) for n in next_urls: next_url = ‘http://www.shicimingju.com‘ + n.xpath(‘./h3/a/@href‘).extract_first() yield scrapy.Request(url=next_url,callback=self.get_z_detail,meta={‘item‘:item}) self_urls = response.xpath(‘//a[contains(text(), "下一页")]/@href‘).extract_first() if self_urls: self_url = ‘http://www.shicimingju.com‘ + self_urls yield scrapy.Request(url=self_url, callback=self.get_zuozhe) def get_z_detail(self,response): item = response.meta[‘item‘] item[‘url‘] = response.request.url item[‘category‘] = response.xpath(‘//div[@class="shici-mark"]/a/text()‘).extract_first() item[‘title‘] = response.xpath(‘//div[@id="item_div"]/h1/text()‘).extract_first() item[‘auther‘] = response.xpath(‘//div[@class="niandai_zuozhe"]/a/text()‘).extract_first() item[‘dynasty‘] = response.xpath(‘//div[@class="niandai_zuozhe"]/text()‘).extract_first() contents = response.xpath(‘//div[@class="item_content"]//text()‘).extract() content = ‘‘ for c in contents: content += c.strip() + ‘ ‘ item[‘content‘] = content shangxi_contents = response.xpath(‘//div[@class="shangxi_content"]//text()‘).extract() contents = ‘‘ for s in shangxi_contents: contents += s.strip() item[‘contents‘] = contents by1 = response.xpath(‘//div[@id="item_div"]/img/@src‘).extract_first() if by1: item[‘beiyong1‘] = by1 else: item[‘beiyong1‘] = ‘‘ yield item
4.pipline.py中编写写入数据库和下载图片到本地规则
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html import pymysql from scrapy import Request from scrapy.exceptions import DropItem from scrapy.pipelines.images import ImagesPipeline class ScmjwPipeline: def process_item(self, item, spider): return item class MysqlPipeline: def __init__(self,host,database,user,password): self.host = host self.database = database self.user = user self.password = password def open_spider(self,spider): self.conn = pymysql.connect(self.host,self.user,self.password,self.database,charset=‘utf8‘) self.cursor = self.conn.cursor() # self.old_url = set() # search_sql = "select url from scmjw" # self.cursor.execute(search_sql) # for i in self.cursor.fetchall(): # self.old_url.add(i[0]) def process_item(self,item,spider): # if item[‘url‘] in self.old_url: # print(‘数据已入库‘,item[‘title‘]) # raise DropItem print(‘数据下载中‘,item[‘title‘]) data = dict(item) keys = ‘, ‘.join(data.keys()) values = ‘, ‘.join([‘% s‘] * len(data)) sql = ‘insert into % s (% s) values (% s)‘ % (item.table, keys, values) self.cursor.execute(sql, tuple(data.values())) self.conn.commit() return item def close_spider(self,spider): self.cursor.close() self.conn.close() @classmethod def from_crawler(cls,crawler): return cls( host=crawler.settings.get(‘MYSQL_HOST‘), database=crawler.settings.get(‘MYSQL_DATABASE‘), user=crawler.settings.get(‘MYSQL_USER‘), password=crawler.settings.get(‘MYSQL_PASSWORD‘), ) class ImagePipeline(ImagesPipeline): def file_path(self, request, response=None, info=None): url = request.url file_name = url.split(‘?‘)[0].split(‘/‘)[-1] return file_name def item_completed(self, results, item, info): image_paths = [x[‘path‘] for ok, x in results if ok] if not image_paths: raise DropItem(‘Image Downloaded Failed‘) return item def get_media_requests(self, item, info): if item[‘beiyong1‘]: yield Request(item[‘beiyong1‘])
5.settings.py中设置,空值日志输出,数据库信息,开启相应管道文件等
# -*- coding: utf-8 -*- # Scrapy settings for scmjw project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://docs.scrapy.org/en/latest/topics/settings.html # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html # https://docs.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = ‘scmjw‘ SPIDER_MODULES = [‘scmjw.spiders‘] NEWSPIDER_MODULE = ‘scmjw.spiders‘ # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = ‘scmjw (+http://www.yourdomain.com)‘ # Obey robots.txt rules ROBOTSTXT_OBEY = False LOG_LEVEL = ‘ERROR‘ LOG_FILE = ‘log.txt‘ IMAGES_STORE = ‘./image‘ MYSQL_HOST = ‘localhost‘ MYSQL_DATABASE = ‘lf_01‘ MYSQL_USER = ‘root‘ MYSQL_PASSWORD = ‘root‘ # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, # ‘Accept-Language‘: ‘en‘, #} # Enable or disable spider middlewares # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # ‘scmjw.middlewares.ScmjwSpiderMiddleware‘: 543, #} # Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { # ‘scmjw.middlewares.ScmjwDownloaderMiddleware‘: 543, ‘scmjw.middlewares.QuChongMiddleware‘: 542, } # Enable or disable extensions # See https://docs.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # ‘scrapy.extensions.telnet.TelnetConsole‘: None, #} # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { ‘scmjw.pipelines.ScmjwPipeline‘: 300, ‘scmjw.pipelines.MysqlPipeline‘: 301, ‘scmjw.pipelines.ImagePipeline‘: 302, } # Enable and configure the AutoThrottle extension (disabled by default) # See https://docs.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = ‘httpcache‘ #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage‘
6.middleware.py文件中使用下载中间件去重,防止重复下载
# -*- coding: utf-8 -*- # Define here the models for your spider middleware # # See documentation in: # https://docs.scrapy.org/en/latest/topics/spider-middleware.html from scrapy import signals import pymysql from scrapy.exceptions import IgnoreRequest class QuChongMiddleware: def __init__(self,host,database,user,password): self.conn = pymysql.connect(host, user, password, database, charset=‘utf8‘) self.cursor = self.conn.cursor() self.old_url = set() search_sql = "select url from scmjw" self.cursor.execute(search_sql) for i in self.cursor.fetchall(): self.old_url.add(i[0]) def process_request(self,request,spider): if request.url in self.old_url: print(‘中间件判断,数据库已存在‘) raise IgnoreRequest() @classmethod def from_crawler(cls,crawler): return cls( host=crawler.settings.get(‘MYSQL_HOST‘), database=crawler.settings.get(‘MYSQL_DATABASE‘), user=crawler.settings.get(‘MYSQL_USER‘), password=crawler.settings.get(‘MYSQL_PASSWORD‘), ) class ScmjwSpiderMiddleware: # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the spider middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_spider_input(self, response, spider): # Called for each response that goes through the spider # middleware and into the spider. # Should return None or raise an exception. return None def process_spider_output(self, response, result, spider): # Called with the results returned from the Spider, after # it has processed the response. # Must return an iterable of Request, dict or Item objects. for i in result: yield i def process_spider_exception(self, response, exception, spider): # Called when a spider or process_spider_input() method # (from other spider middleware) raises an exception. # Should return either None or an iterable of Request, dict # or Item objects. pass def process_start_requests(self, start_requests, spider): # Called with the start requests of the spider, and works # similarly to the process_spider_output() method, except # that it doesn’t have a response associated. # Must return only requests (not items). for r in start_requests: yield r def spider_opened(self, spider): spider.logger.info(‘Spider opened: %s‘ % spider.name) class ScmjwDownloaderMiddleware: # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass def spider_opened(self, spider): spider.logger.info(‘Spider opened: %s‘ % spider.name)
7.在根目录下创建start.py文件用于启动爬虫
from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) process.crawl(‘scmj‘) process.start()
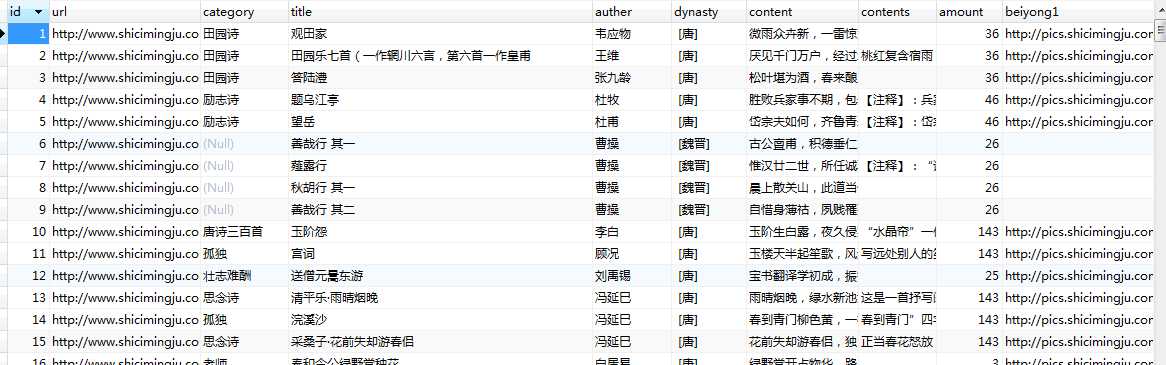
8.爬取结果概览
二、简单对数据进行分析
使用的第三方库为
numpy,pandas,matplotlib
1.代码如下
import pandas as pd import numpy as np from sqlalchemy import create_engine from matplotlib import pyplot as plt import warnings ‘‘‘ 明确分析目标 1.诗词分类前十及占比 2.写诗词数量最多的作者前十分类及占比 3.诗词数量最多的朝代及占比 4.有注释的诗词 5.有图片的诗词 ‘‘‘ ‘‘‘设置正常显示中文和‘-’号‘‘‘ # 设置正常显示中文 plt.rcParams[‘font.sans-serif‘] = ‘SimHei‘ # 设置正常显示‘-’号 plt.rcParams[‘axes.unicode_minus‘] = False # 去除顶部轴 plt.rcParams[‘axes.spines.top‘] = False # 去除右部轴 plt.rcParams[‘axes.spines.right‘] = False # 屏蔽warning警告 warnings.filterwarnings("ignore") class Scmj: def __init__(self): self.conn = create_engine("mysql+pymysql://root:root@127.0.0.1:3306/lf_01?charset=utf8mb4") self.df = pd.read_sql(‘select * from scmjw‘,self.conn) self.conn.dispose() # print(self.df.head()) print(self.df.info()) # print(self.df.describe()) ‘‘‘获取一些描述性信息‘‘‘ def get_ty(self): # 数据总量 self.scmj_all = self.df.shape[0] print(‘数据总量为:‘,self.scmj_all) ‘‘‘诗词分类前十及占比‘‘‘ def category_top10(self): category = self.df.groupby(‘category‘) category_top10 = category.count()[‘id‘].sort_values(ascending=False)[:10] print(‘分类前十: ‘,category_top10) # 折线图 pic = plt.figure(figsize=(12,12),dpi=100) pic.add_subplot(2,2,1) plt.title(‘诗词分类前十折线图‘) plt.xlabel(‘诗词分类‘) plt.ylabel(‘数量‘) plt.xticks(rotation=90) plt.yticks([i for i in range(0,200,10)]) plt.plot(category_top10) # 条形图 pic.add_subplot(2,2,2) plt.title(‘诗词分类前十条形图‘) plt.xlabel(‘诗词分类‘) plt.ylabel(‘数量‘) x = range(10) plt.bar(x,height=category_top10.values,width=0.7) for i in range(len(category_top10)): # print(category_top10.values[i]) plt.text(i,category_top10.values[i],‘{}首‘.format(category_top10.values[i]),va=‘bottom‘,ha=‘center‘) plt.xticks(x,category_top10.index,rotation=90) # 饼图 pic.add_subplot(2,2,3) plt.title(‘诗词分类前十饼图‘) plt.pie(category_top10,autopct=‘%1.1f%%‘,labels=category_top10.index,explode=[0.01 for i in range(10)]) # 箱线图 pic.add_subplot(2,2,4) plt.title(‘诗词分类前十箱线图‘) plt.boxplot(category_top10) plt.savefig(‘./诗词分类前十统计图.png‘) plt.show() ‘‘‘写诗词数量最多的作者前十及占比‘‘‘ def auther_top10(self): auther_top10 = self.df[‘auther‘].value_counts().iloc[:10] print(‘写诗词数量前十作者‘,auther_top10) fig = plt.figure(figsize=(12,12),dpi=100) # 折线图 fig.add_subplot(2,2,1) plt.title(‘折线图‘) plt.xlabel(‘作者‘) plt.ylabel(‘写作数量‘) for i,j in zip(auther_top10.index,auther_top10.values): plt.text(i,j,j,ha=‘center‘, va=‘bottom‘,) plt.plot(auther_top10) # 条形图 fig.add_subplot(2,2,2) x = range(len(auther_top10)) plt.title(‘条形图‘) plt.xlabel(‘作者‘) plt.ylabel(‘写作数量‘) plt.xticks(x,auther_top10.index) plt.bar(x=x,height=auther_top10.values,width=0.7) for i in range(len(auther_top10)): plt.text(i,auther_top10.values[i],auther_top10.values[i],va=‘bottom‘,ha=‘center‘) # 饼图 fig.add_subplot(2,2,3) plt.title(‘饼图‘) plt.pie(auther_top10.values,autopct=‘%1.1f%%‘,labels=auther_top10.index,explode=[0.01 for i in range(len(auther_top10))]) # 散点图 fig.add_subplot(2,2,4) plt.title(‘散点图‘) plt.xlabel(‘作者‘) plt.ylabel(‘写作数量‘) plt.scatter(x=auther_top10.index,y=auther_top10.values) plt.savefig(‘写诗词数量前十作者统计图.png‘) plt.show() ‘‘‘诗词数量最多的朝代及占比‘‘‘ def dynasty_top10(self): df1 = self.df clean_d = df1[‘dynasty‘].fillna(np.nan) clean_d[clean_d == ‘ [] ‘] = np.nan df1[‘dynasty‘] = clean_d # df1[df1[‘dynasty‘] == ‘ [] ‘] = None df1.dropna(subset=[‘dynasty‘]) dynasty = df1[‘dynasty‘].value_counts()[:10] fig = plt.figure(dpi=100,figsize=(12,12)) # 折线图 fig.add_subplot(2, 2, 1) plt.title(‘折线图‘) plt.xlabel(‘朝代‘) plt.ylabel(‘写作数量‘) for i,j in zip(dynasty.index,dynasty.values): plt.text(i,j,j,ha=‘center‘,va=‘bottom‘) plt.plot(dynasty) # 条形图 fig.add_subplot(2,2,2) plt.title(‘条形图‘) plt.xlabel(‘朝代‘) plt.ylabel(‘写作数量‘) plt.bar(x=dynasty.index,height=dynasty.values,width=0.8) for i,j in zip(dynasty.index,dynasty.values): plt.text(i,j,j,va=‘bottom‘,ha=‘center‘) # 饼图 fig.add_subplot(2,2,3) plt.title(‘饼图‘) plt.pie(x=dynasty,autopct=‘%1.1f%%‘,labels=dynasty.index,explode=[0.01 for i in range(len(dynasty))]) # 散点图 fig.add_subplot(2,2,4) plt.title(‘散点图‘) plt.xlabel(‘朝代‘) plt.ylabel(‘写作数量‘) plt.scatter(x=dynasty.index,y=dynasty.values) for i,j in zip(dynasty.index,dynasty.values): plt.text(i,j,j,ha=‘center‘,va=‘center‘) plt.savefig(‘./诗词数量最多的朝代前十及占比.png‘) plt.show() ‘‘‘有注释&图片的诗词‘‘‘ def contents_images(self): df1 = self.df df1[df1[‘contents‘] == ‘‘] = None contents = df1.dropna(subset=[‘contents‘]).shape[0] print(‘有注释的诗词数量为:‘,contents) df2 = self.df df2[df2[‘beiyong1‘] == ‘‘] = None images = df2.dropna(subset=[‘beiyong1‘]).shape[0] print(‘有图片的诗词数量为:‘,images) ‘‘‘饼图‘‘‘ explode = [0.01,0.01] fig = plt.figure(figsize=(8,8),dpi=100) fig.add_subplot(1,2,1) plt.title(‘有注释的诗词占比‘) x = [self.scmj_all,contents] labels = [‘无注释‘,‘有注释‘] plt.pie(x=x,autopct=‘%1.1f%%‘,labels=labels,explode=explode) fig.add_subplot(1,2,2) plt.title(‘有图片的诗词占比‘) x = [self.scmj_all,images] labels = [‘无图片‘,‘有图片‘] plt.pie(x=x,autopct=‘%1.1f%%‘,labels=labels,explode=explode) plt.savefig(‘./图片&诗词占比.png‘) plt.show() def run(self): self.get_ty() self.category_top10() self.auther_top10() self.dynasty_top10() self.contents_images() def __del__(self): pass if __name__ == ‘__main__‘: S = Scmj() S.run()
2.分析结果概览
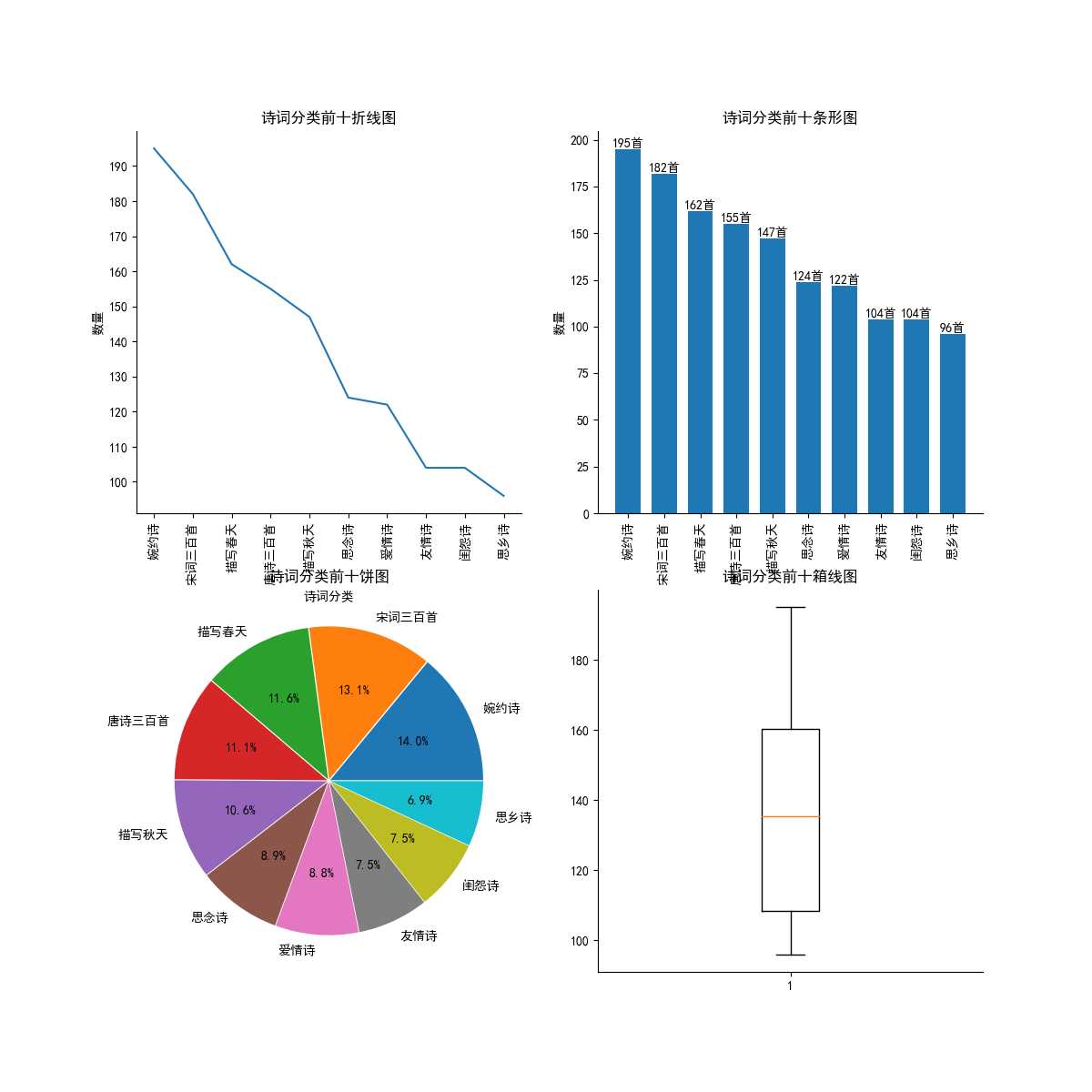
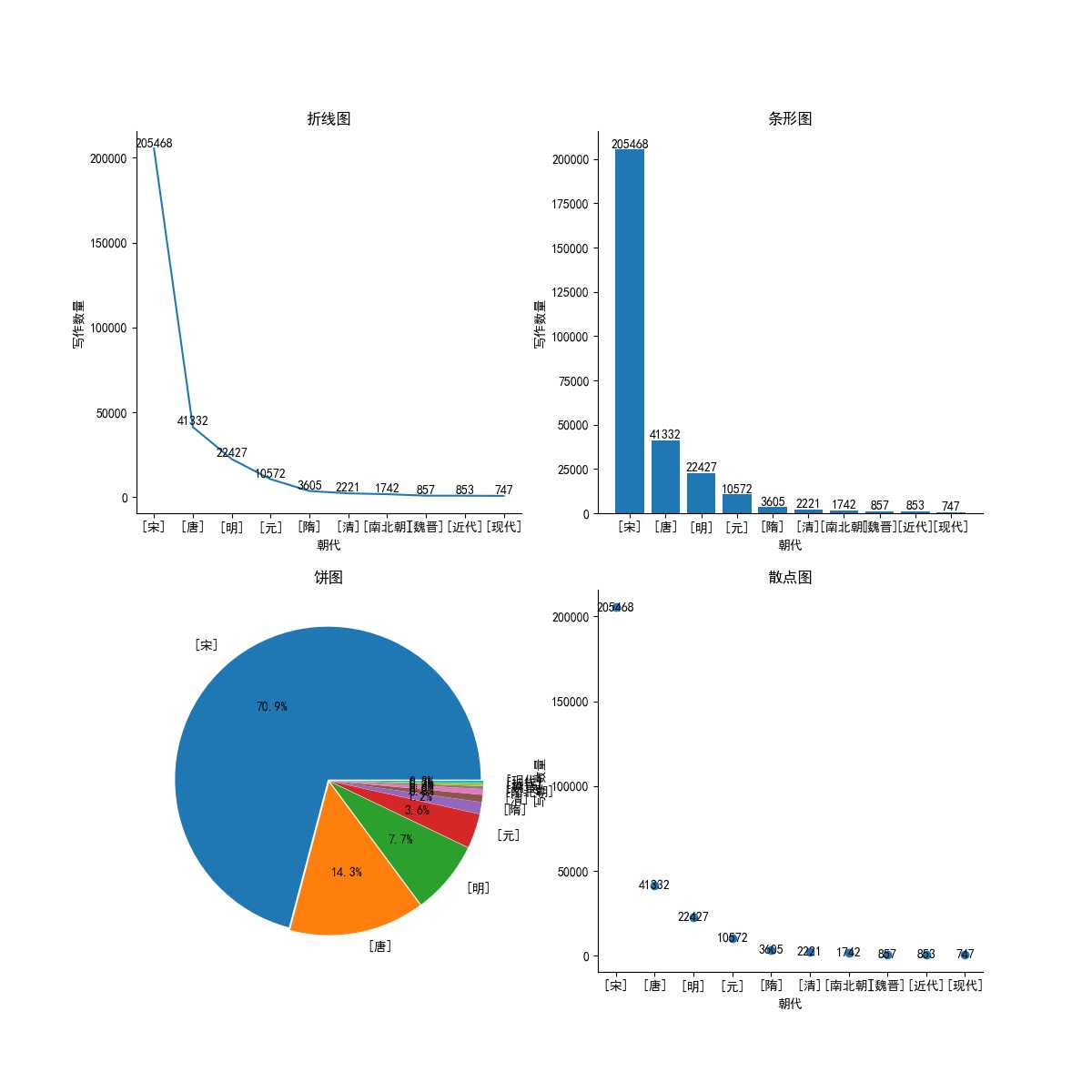
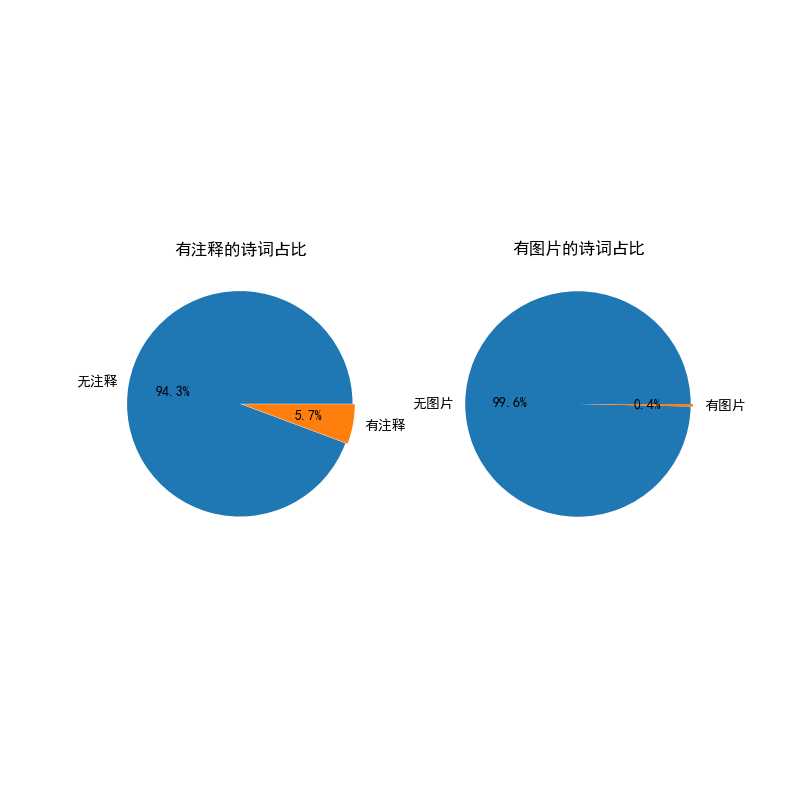
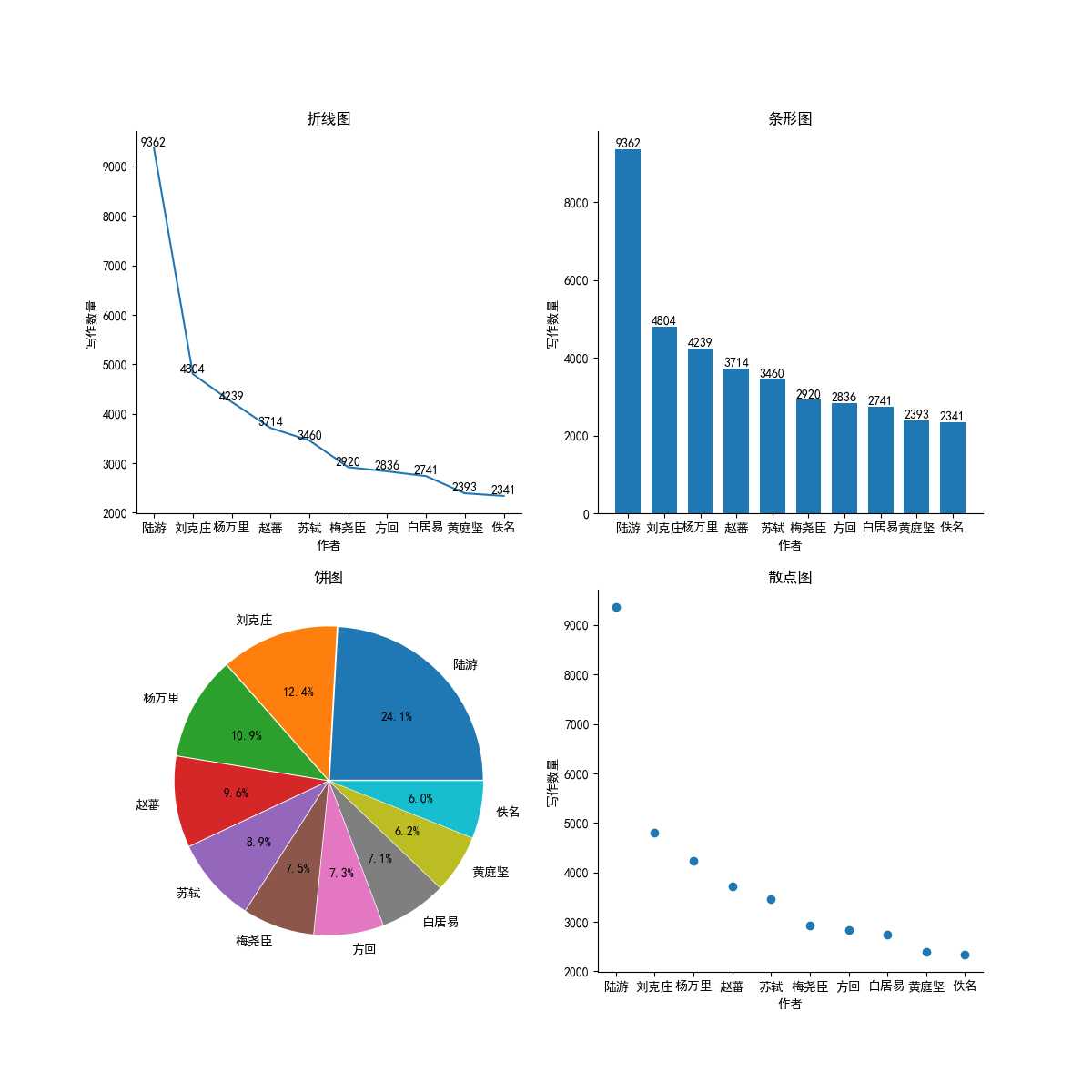
代码已托管github,地址为 https://github.com/terroristhouse/scmjw.git
以上是关于爬取诗词名句网数据并做简单数据分析的主要内容,如果未能解决你的问题,请参考以下文章