手写数字识别-小数据集
Posted cong1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手写数字识别-小数据集相关的知识,希望对你有一定的参考价值。
1.手写数字数据集
- from sklearn.datasets import load_digits
- digits = load_digits()
(1)导入数据包
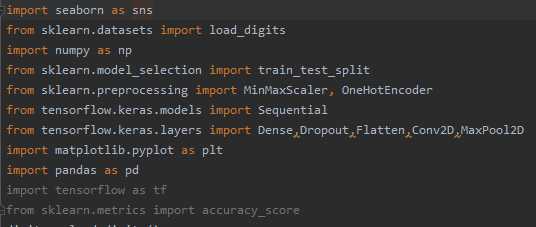
(2)读取数据
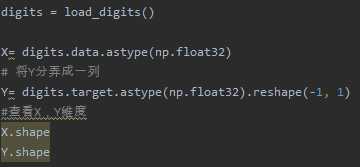
2.图片数据预处理
- x:归一化MinMaxScaler()
- y:独热编码OneHotEncoder()或to_categorical
- 训练集测试集划分
- 张量结构
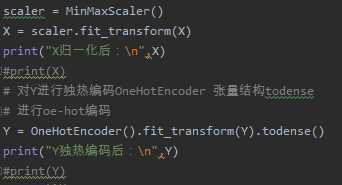
(1)x:归一化MinMaxScaler(),y:独热编码OneHotEncoder()
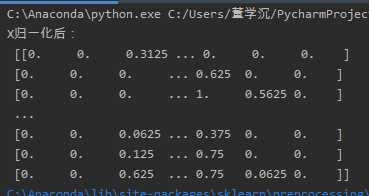
结果如图:

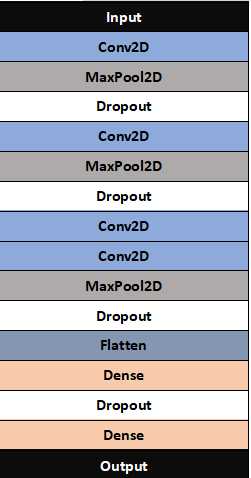
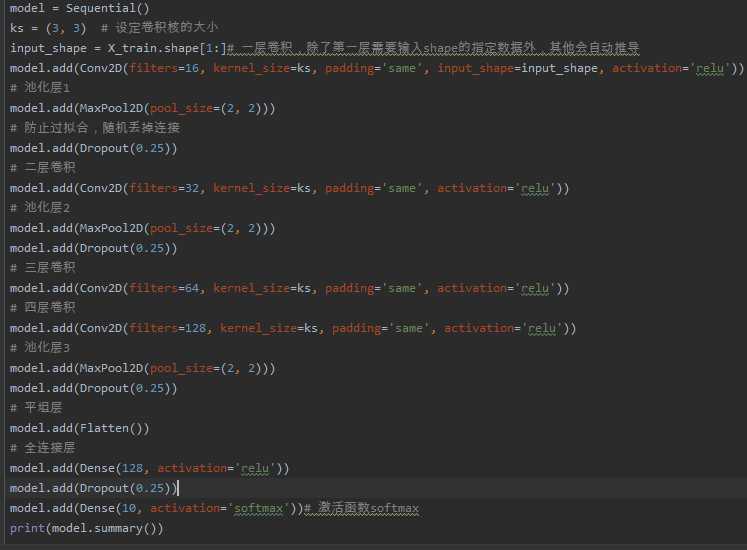
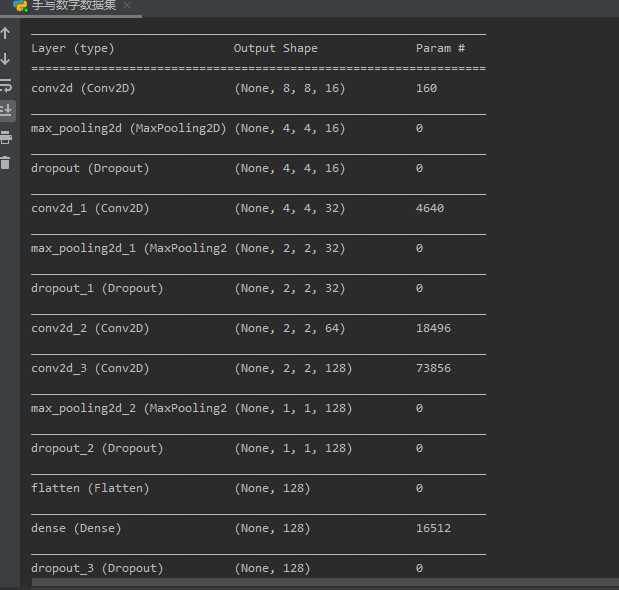
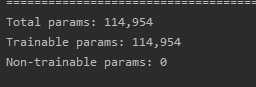
3.设计卷积神经网络结构
- 绘制模型结构图,并说明设计依据。
模型结构如图:
设计理念依据:
(1)传递一个input_shape的关键字参数给第一层,input_shape是一个tuple类型的数据,其中也可以填入None,如果填入None则表示此位置可能是任何正整数。数据的batch大小不应包含在其中
(2)传递一个batch_input_shape的关键字参数给第一层,该参数包含数据的batch大小。该参数在指定固定大小batch时比较有用,例如在stateful RNNs中。事实上,Keras在内部会通过添加一个None将input_shape转化为batch_input_shape
(3)有些2D层,如Dense,支持通过指定其输入维度input_dim来隐含的指定输入数据shape。一些3D的时域层支持通过参数input_dim和input_length来指定输入shape。
(4)优化器optimizer:该参数可指定为已预定义的优化器名
(5)损失函数loss:该参数为模型试图最小化的目标函数
(6)由于图像尺寸较小,故卷积核尺寸设置为3×3,三个卷积-池化层的卷积核数量分别设置为16、32、64。
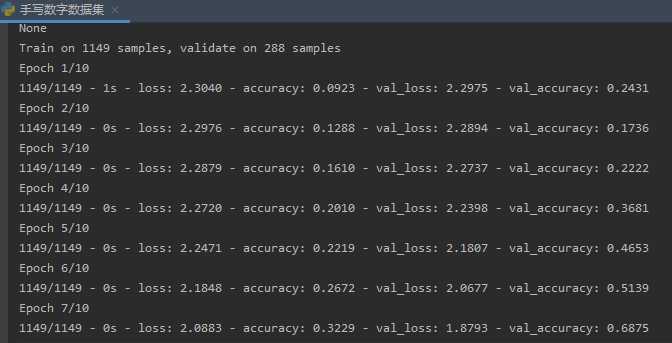

4.模型训练

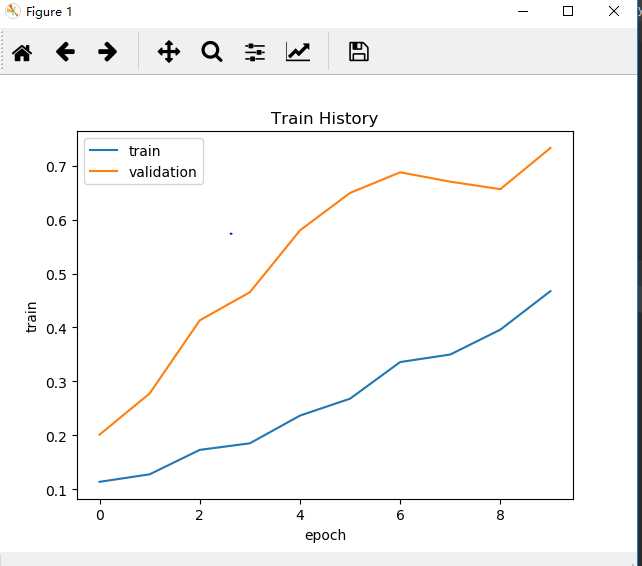
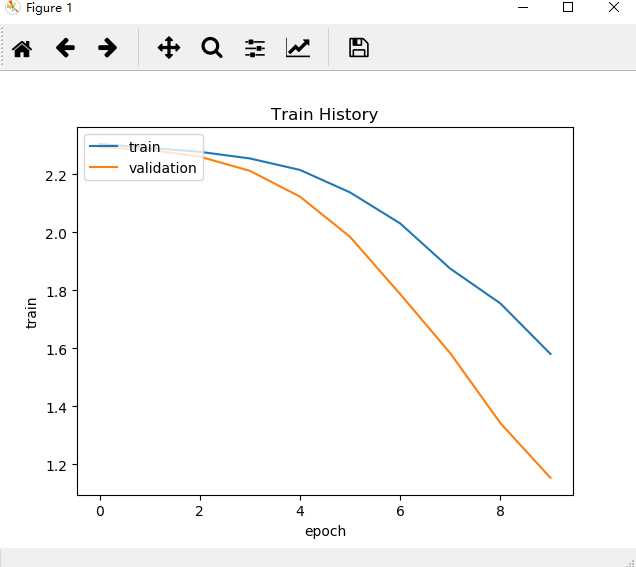
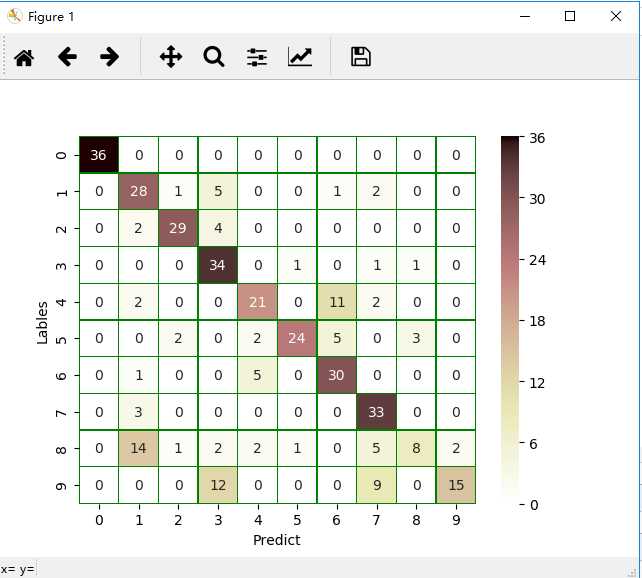
5.模型评价
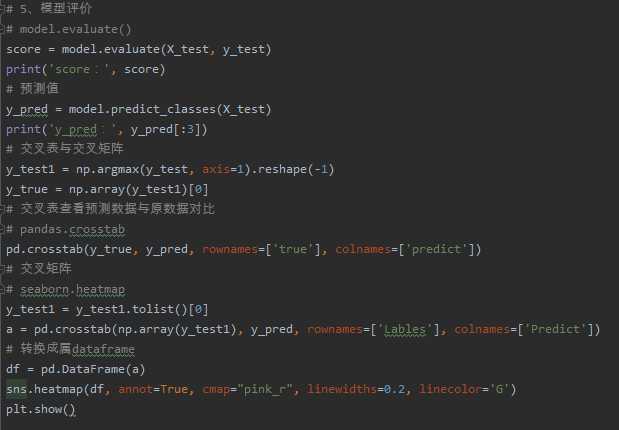
- model.evaluate()
- 交叉表与交叉矩阵
- pandas.crosstab
- seaborn.heatmap

以上是关于手写数字识别-小数据集的主要内容,如果未能解决你的问题,请参考以下文章