redis入门到精通系列:redis的高可用--主从复制详解
Posted edda
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis入门到精通系列:redis的高可用--主从复制详解相关的知识,希望对你有一定的参考价值。
(一)主从复制介绍
前面所讲的关于redis的操作都属于单机操作,单机操作虽然操作简单,但是处理能力有限,无法高可用。所谓高可用性,就是指当一台服务器宕机的时候,有备用的服务器能顶替上,在单机操作上这是无法实现的,因此就出现了主从复制。
我们把一台服务器看作是主服务器(master),把另外多台服务器看作是从服务器(slave),主从复制就是将master中的数据即时有效的复制到slave中。

一个master可以拥有多个slave,一个slave只对应于一个master
master负责执行写数据,将出现变化的数据自动同步到slave
有了主从复制之后,就可以实现高可用了,当一台slave宕机后,还有多台slave存在;当master宕机后,由于slave的数据和master是一样的,就可以推选一台slave为新的master,都能做到高可用。
负载均衡:由slave分担master负载,并根据具体的需求可以改变slave的数量
故障恢复:当master出现问题时,可以由slave来代替master,实现快速恢复
(二)主从复制工作流程

2.1 建立连接阶段
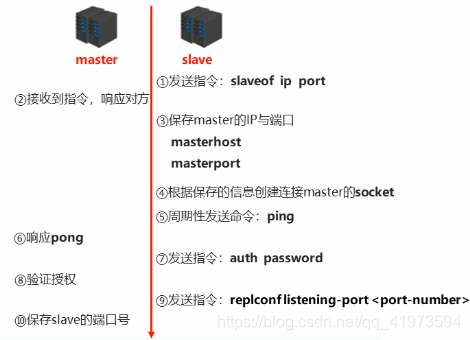
为了实现上述过程,我分别在两个端口开启redis服务,6379代表master,6380代表slave
复制两份redis的配置文件,重命名为redis6379.conf和redis6380.conf,分别修改配置文件中的port为6379和6380。在cmd下开启两个服务:
 再开启两个客户端分别连接两个redis服务,6379是master,6380是slave
再开启两个客户端分别连接两个redis服务,6379是master,6380是slave
- redis-cli -p 6379
- redis-cli -p 6380
slaveof <masterip> <masterport>![]()
此时主从连接已经完成,我在master设置一个name,在slave中可以直接获取
![]()

主从连接除了可以用命令连接之外,还可以在配置文件中进行配置,在redis6380.conf中增加这一句
slaveof 127.0.0.1 6379slaveof no one2.2 数据同步阶段
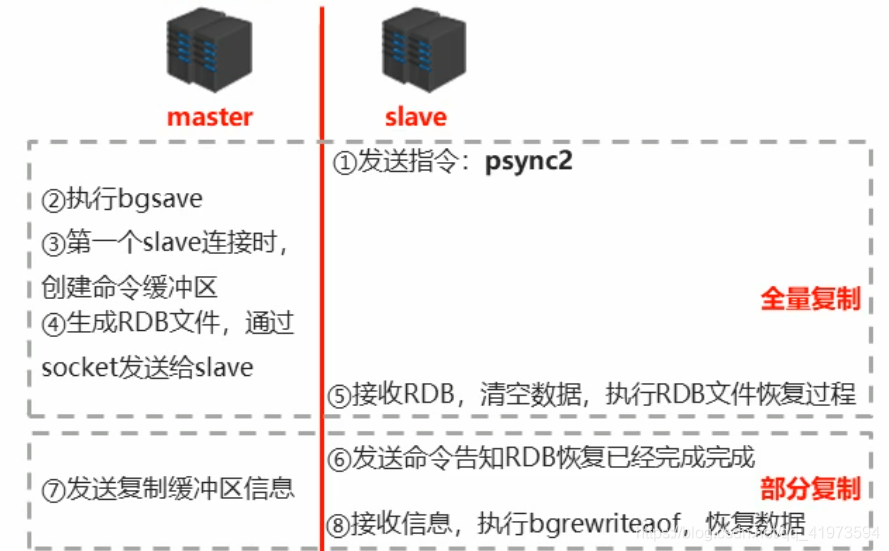
数据同步又分为全量复制和部分复制两块,其中全量复制就是你启动同步指令之后进行的RDB操作,把master中的数据通过RDB发送给slave。由于RDB采用bgsave指令,所以在全量复制期间master所做的操作会进入一个缓冲区,当全量复制结束后就需要通过部分复制来恢复缓冲区中的操作,这里采用AOF。
通过上面的介绍我们知道了当在进行全量复制时所进行的操作会放入缓存区,但是如果缓存区设置过小就会导致master阻塞,通过下面方式可以设置缓存区大小:
repl-backlog-size 1mbslave-server-stable-data yes|no2.3 命令传播阶段
命令传播阶段就是当master数据库状态发生变化,就会通过命令传播阶段同步给slave
服务器的运行id、主服务器的复制积压缓冲区、主从服务器的复制偏移量
服务器运行id是每台服务器每次运行的身份识别码,由40个字符组成,用于在服务器之间传输时识别身份。
复制积压缓冲区又称为复制缓冲区,是一个先进先出的队列。当master数据库发生变化时,master会将要传播给slave的命令保存在复制缓冲区中,slave分别从复制缓冲区接收信息。
因为命令传播阶段首先由master把数据放入缓冲区中,因此master需要一个复制偏移量记录发送给slave的指令对应的位置。而slave要把缓冲区中的数据同步到自己这里,因此也需要一个复制偏移量记录接收到的位置,如果因为意外断网,等网络再次连接之后就可以直接从复制偏移量的位置继续复制。
2.4 心跳机制
进入命令传播阶段后,master和slave需要通过心跳机制保持双方连接
通过ping指令查询slave是否在线,可由repl-ping-slave-period设置周期,默认10秒
replconf ack {offset}作用:汇报slave自己的复制偏移量;判断master是否在线
当slave多数都掉线或者slave延迟过高时,可以强制关闭master的写功能,停止数据同步:
- min-slaves-to-write 2 当连接的slave小于等于2台时停止数据同步
- min-slaves-max-lag 10 当连接的slave延迟大于10秒,停止数据同步
以上是关于redis入门到精通系列:redis的高可用--主从复制详解的主要内容,如果未能解决你的问题,请参考以下文章