大型Electron应用本地数据库技术选型
Posted liulun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大型Electron应用本地数据库技术选型相关的知识,希望对你有一定的参考价值。
开发一个大型Electron的应用,或许需要在客户端存储大量的数据,比如聊天应用或邮件客户端
可选的客户端数据库方案看似很多,但一一对比下来,最优解只有一个
接下来我们就一起来经历一下这个技术选型的过程:
排除:把数据以Json的形式存储在文件中
以这种方式存储一些用户的配置信息是完全没问题的(用户名、家庭住址、是否开启免打扰模式等)
但要用这种方式存储大量解构化的数据,就非常不科学了
主要原因是:
用这种方案操作数据是需要把文件中的所有数据都加载到客户端电脑的内存中去的
由于没有索引机制,关联查询、条件查询等操作效率不高,
更新了某项数据之后,要持久化更新操作,又要重写整个文件。
PS:
如果你的应用操作的数据量不多,
你可以选择类似lowdb(https://github.com/typicode/lowdb)这样的工具,
在一定程度上环节这些困难
排除:LocalStorage、SessionStorage、WebSql、Cookies
Cookies存储容量太小,只能存4kb的内容,而且每次与服务端交互,同域下的Cookie还会被携带到服务端,也没有关联查询、条件查询的机制
LocalStorage存储容量也很小,大概不会超过10M,它是以键值对形式保存数据的,同样也没有关联查询、条件查询的机制
SessionStorage最大的问题是,每次关闭应用程序,它里面的内容会被清空,想持久化存储数据,就不用考虑它了
WebSql诸般特性都挺好,无奈这个技术已经被W3C委员会否决了,不知道哪天Electron也不支持了,到时就傻眼了
分析
现在可选的成熟方案几乎只剩下SQLite和IndexedDB了,
SQLite是一个轻型的、嵌入式的SQL 数据库引擎,其特点是自给自足的、无服务器、零配置的、支持事务。它是在世界上最广泛部署的 SQL 数据库引擎。
IndexedDB是Chromium内置的一个基于javascript的面向对象的数据库,在Electron应用内它存储的容量限制与用户的磁盘容量有关,是用户磁盘大小的1/3
市面上选这两个方案的商业产品各都有很多
那么到底哪个好呢?
接下去我们就做一个性能的对比
SQLite和IndexedDB性能对比
测试环境
CPU:I9 9900K 3.6GHZ
内存:32G
OS:Win10
环境搭建
SQLite环境
访问SQLite数据使用的是knexjs操作库,它是一个sql生成器,支持Promise API,链式操作非常好用,推荐使用
在Electron应用内安装SQLite,比较特殊,需要使用如下安装指令:
npm install sqlite3 --build-from-source --runtime=electron --target=9.0.0 --dist-url=https://atom.io/download/electron
注意:--target后面的内容与你使用的Electron的版本要一致
SQLite的数据库表结构
CREATE TABLE [message]( [id] INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL UNIQUE, [msg_from] VARCHAR(80), [msg_to] VARCHAR(80), [msg] TEXT, [create_time] DATETIME);
这里主要模拟了一个IM应用的消息表
SQLite的测试代码如下
let { app } = require(‘electron‘);
let messages = require(‘./messages‘)
let path = require(‘path‘);
let filename = path.join(app.getPath(‘userData‘), ‘db.db‘);
let db = require(‘knex‘)({
client: ‘sqlite3‘,
useNullAsDefault: true,
connection: { filename },
timezone: ‘UTC‘,
dateStrings: true
});
let start = async () => {
let startTime = Date.now();
for (let i = 0; i < 10; i++) {
let index = i % 2;
await db(‘message‘).insert(messages[index]);
}
//let arr = await db(‘message‘).whereBetween(‘id‘,[1600,9600]);
//await db(‘message‘).whereBetween(‘id‘,[0,10000]).del();
//await db(‘message‘).update({msg:`天接云涛连晓雾。!!!`}).whereBetween(‘id‘,[2600,2800]);
let endTime = Date.now();
console.log(endTime - startTime);
}
module.exports = {
start
}
其中用到了messages是两个消息体的JSON对象,代码如下:
let messages = [{ msg_from: ‘辛弃疾‘, msg_to: ‘刘晓伦‘, msg: `醉里挑灯看剑,梦回吹角连营。 八百里分麾下炙, 五十弦翻塞外声, 沙场秋点兵。 马作的卢飞快, 弓如霹雳弦惊。 了却君王天下事, 赢得生前身后名。 可怜白发生!`, create_time: new Date() }, { msg_from: ‘李清照‘, msg_to: ‘刘晓伦‘, msg: `天接云涛连晓雾。 星河欲转千帆舞。 仿佛梦魂归帝所, 闻天语, 殷勤问我归何处。 我报路长嗟日暮, 学诗谩有惊人句。 九万里风鹏正举。 风休住, 蓬舟吹取三山去!`, create_time: new Date(), }]; module.exports = messages
IndexedDB环境
IndexedDB的测试代码是在渲染进程中执行的,代码如下:
let Dexie = require(‘Dexie‘); const db = new Dexie(‘db‘); db.version(1).stores({ message: ‘++, message_from, message_to,msg,create_time‘ }); window.onload = async () => { let startTime = Date.now(); for (let i = 0; i < 10000; i++) { let index = i % 2; await db.message.add(messages[index]); } //let arr = await db.message.where("id").between(1000, 9000).delete(); let endTime = Date.now(); console.log(endTime - startTime); }
测试结果
插入
连续插入100行数据,执行8次
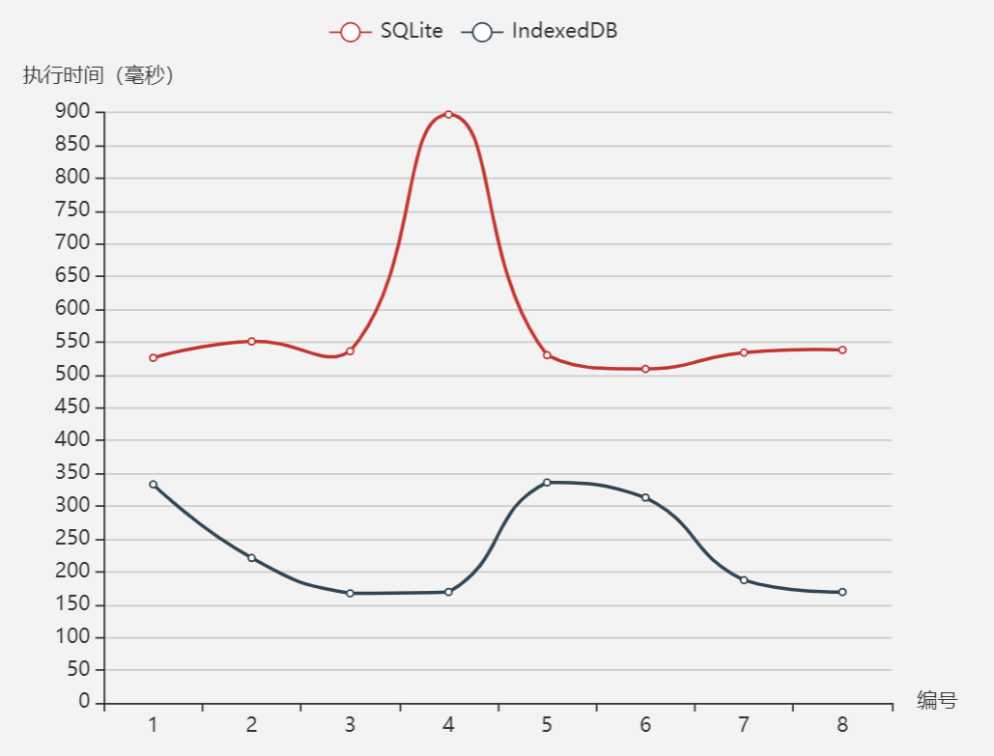
[ { name: ‘SQLite‘, data: [526,551,536, 897, 530, 509, 534,538] }, { name: ‘IndexedDB‘, data: [333,221,167, 169, 336, 313, 187,169] } ]
连续插入1000行数据,执行7次
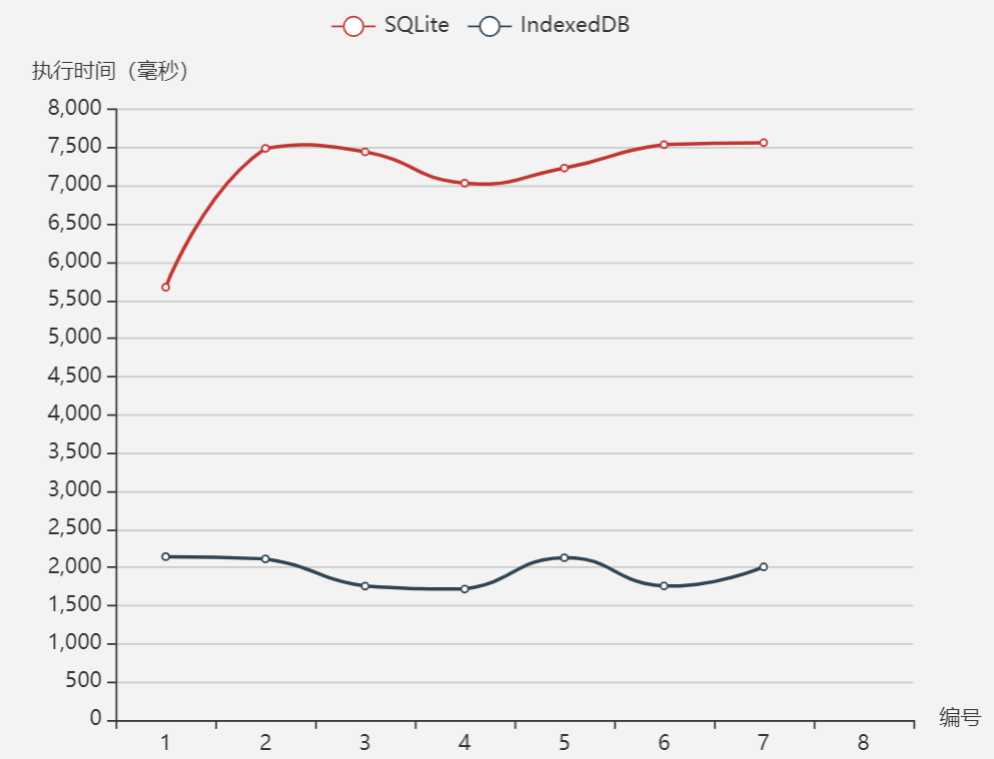
[ { name: ‘SQLite‘, data: [5669,7488,7443,7033,7231,7537,7563] }, { name: ‘IndexedDB‘, data: [2140,2111,1755,1716,2126,1757,2006] } ]
连续插入10000行数据,执行4次
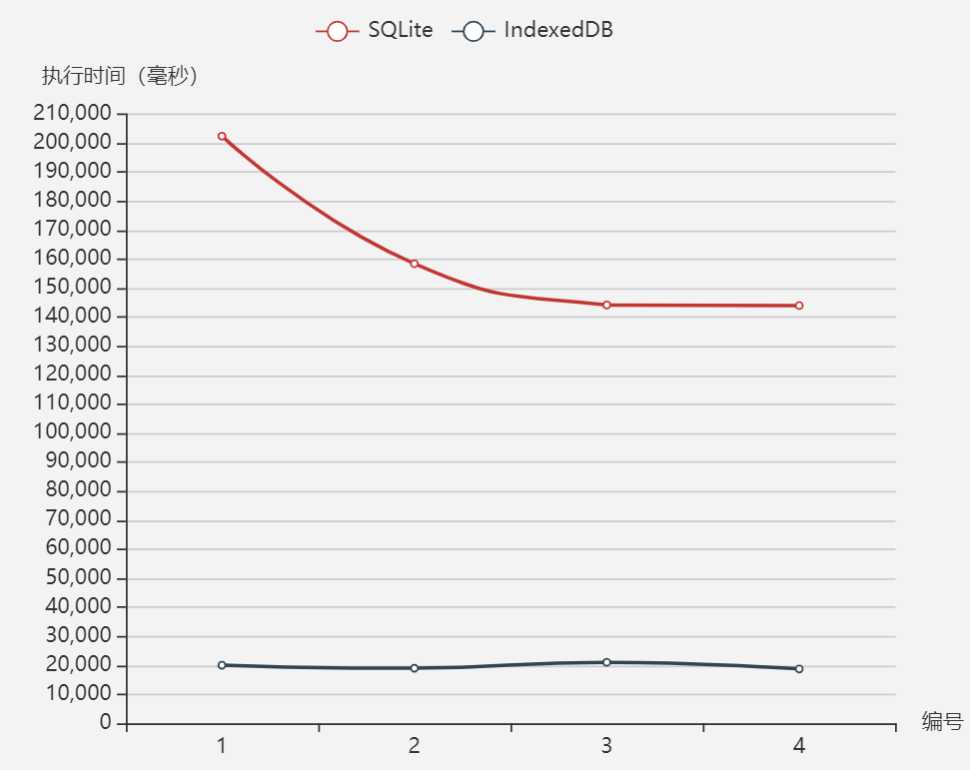
[ { name: ‘SQLite‘, data: [202415,158451,144221,143993] }, { name: ‘IndexedDB‘, data: [20028,18979,21013,18738] } ]
已存在10000行数据的前提下,再插入10行数据
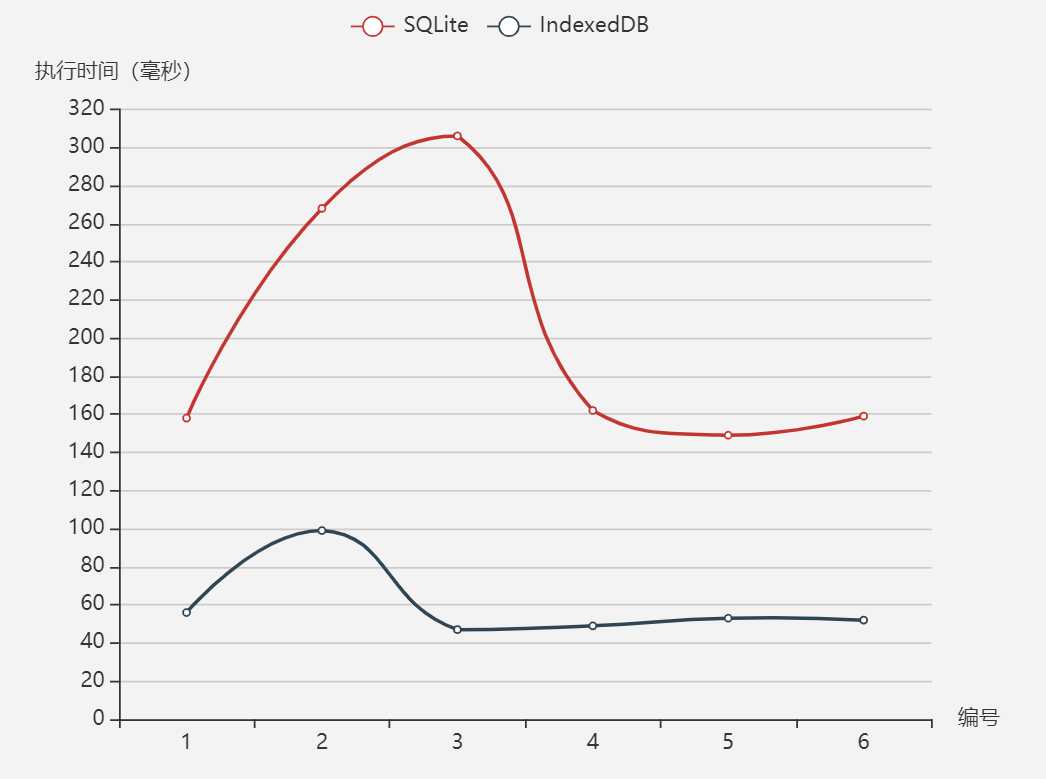
[ { name: ‘SQLite‘, data: [158,268,306,162,149,159] }, { name: ‘IndexedDB‘, data: [56,99,47,49,53,52] } ]
检索
在10000行数据中按主键检索8000行数据
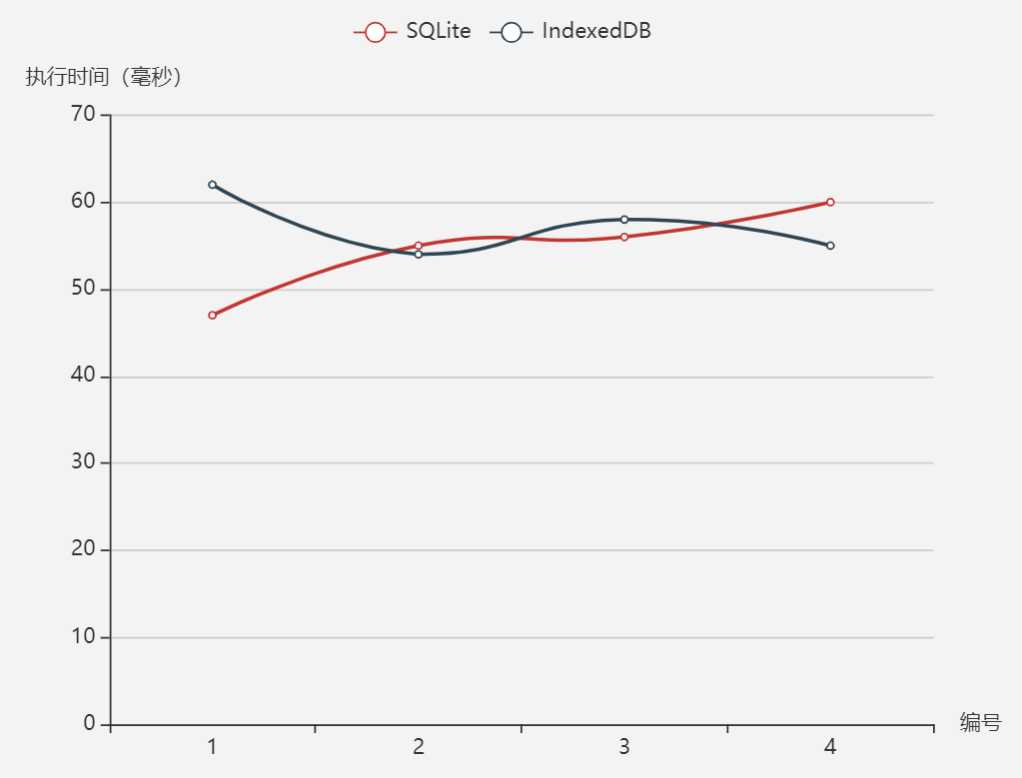
[ { name: ‘SQLite‘, data: [47,55,56,60] }, { name: ‘IndexedDB‘, data: [62,54,58,55] } ]
删除
SQLite
已存在10000行数据的前提下,删除200行数据(毫秒):18、16、18
已存在10000行数据的前提下,删除8000行数据(毫秒):18
已存在10000行数据的前提下,删除10000行数据(毫秒):18
IndexedDB
已存在10000行数据的前提下,删除200行数据(毫秒):21、10、10
已存在10000行数据的前提下,删除8000行数据(毫秒):58
已存在10000行数据的前提下,删除10000行数据(毫秒):30
更新
SQLite
已存在10000行数据的前提下,更新1行数据(毫秒):8、8、8、9、8、8
已存在10000行数据的前提下,更新100行数据(毫秒):30、30、28、30、30
IndexedDB
已存在10000行数据的前提下,更新1行数据(毫秒):11、8、7、7、8、8
已存在10000行数据的前提下,更新100行数据(毫秒):15、14、12、10、13
结论分析
结论:插入数据两个数据库性能相差巨大,IndexedDB显然优于SQLite,检索,删除,更新操作两个数据库性能相差无几
分析:
SQLite有双写入机制,IndexedDB应该是有多级缓存写入机制(待考),显然多级缓存写入机制更优秀
因为是Electron工程下完成此对比,所以Js经Electron转到Node.js再转到SQLite的Node module最后才转到SQLite的C代码,这个过程可能是性能损耗的一大主要原因
最后:
综合对比下来,大型Electron应用更推荐使用IndexedDB来存储业务数据
(由于有Dexie的加持,IndexedDB操作也足够简单,所有中小型应用也是不错的选择)
如果你需要加密客户端数据,SQLite还需要外套sqlcipher这样的加密库,所以性能上会有更多损耗,
然而IndexedDB本身就有一层加密逻辑(可以说只能防君子,防不了小人),虽然简单,但聊胜于无。
最后
欢迎大家购买我的新书《Electron实战:入门、进阶与性能优化》,
书里还有更多有趣的内容,
大家感兴趣可以加QQ群949674481交流。
当当:http://product.dangdang.com/28547952.html;
京东:https://item.jd.com/12867054.html

以上是关于大型Electron应用本地数据库技术选型的主要内容,如果未能解决你的问题,请参考以下文章