云原生消息系统 Pulsar
Posted garfieldcgf
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了云原生消息系统 Pulsar相关的知识,希望对你有一定的参考价值。
1.pulsar概述
Apache Pulsar 是灵活的发布-订阅消息系统(Flexible Pub/Sub messaging),采用分层分片架构(backed by durable log/stream storage)。
Apache Pulsar 是一个开源的分布式pub-sub消息系统,最初是在雅虎创建的,现在是Apache Software Foundation的一部分,是下一代云原生分布式流数据平台。
Apache Pulsar 是服务和存储分离的消息系统,主要分为Broker和BookKeeper两大模块,Broker提供服务能力,BookKeeper提供存储能力。

2.pulsar之于kafka
1. 流式处理和队列的合体
Pulsar 就像是一个合二为一的产品,不仅可以像 Kafka 那样处理高速率的实时场景,还能支持标准的消息队列模式,比如多消费者、失效备援订阅和消息扇出,等等。Pulsar 会自动跟踪客户端的读取位置,并把这些信息保存在高性能的分布式 ledger(BookKeeper)当中。
与 Kafka 不一样的是,Pulsar 具备传统消息队列(如 RabbitMQ)那样的功能,因此,只需要运行一个 Pulsar 系统就可以同时处理实时流和消息队列。
2. 支持分区,但不是必需的
如果你用过 Kafka,就一定知道分区是怎么回事。Kafka 中的所有主题都是分区的,这样可以增加吞吐量。通过分区,单个主题的处理速率可以得到大幅提升。但如果某些主题不需要太高的处理速率,那该怎么办?对于这类情况,就不需要考虑分区了,以避免复杂的 API 和管理方面的工作,这样不是更好吗?
Pulsar 就可以做到。如果你只需要一个主题,而不需要分区,那使用一个主题就好了。如果你需要使用多个消费者实例来提升处理速率,其实也不需要使用分区,因为 Pulsar 的共享订阅可以达到你的目的。
如果你确实需要分区来进一步提升性能,你也可以使用分区。
3. 日志固然不错,但 ledger 更胜一筹
Kafka 开发团队预见了日志对于一个实时数据交换系统的重要性。因为日志是通过追加的方式写入系统的,所以数据写入速度很快。又因为日志中的数据是串行的,所以可以按照写入的顺序快速读取数据。相比随机读取和写入,串行读取和写入速度更快。对于任何一个提供数据保证的系统来说,持久化存储方面的交互都是一个瓶颈,而日志抽象最大限度地提升了这方面的效率。
日志固然是好,但当它们的量增长到很大的时候,也会给我们带来一些麻烦。在单台服务器上保存所有日志已经成为一个挑战。在服务器存储被日志填满之后该怎么办?如何进行伸缩?或者保存日志的服务器宕机,需要重新从副本创建新的服务器,该怎么办?将日志从一台服务器拷贝到另一台服务器是很耗费时间的,特别是如果你想要在保持系统实时数据的情况下完成这个操作就更难了。
Pulsar 对日志进行分段,从而避免了拷贝大块的日志。它通过 BookKeeper 将日志分段分散到多台不同的服务器上。也就是说,日志并不是保存在单台服务器上,所以任何一台服务器都不会成为整个系统的瓶颈。这样就可以更容易地处理故障,要进行伸缩也很容易,只需要加入新的服务器,不需要进行再均衡。
4. 无状态
对于云原生应用程序开发人员来说,他们最喜欢的东西就是无状态。无状态组件启动速度快,可替换,还可以实现无缝的伸缩。如果消息中间件也是无状态的,那岂不是更好?
Kafka 不是无状态的,因为每个 broker 都包含了分区的所有日志,如果一个 broker 宕机,并非任意一 broker 都可以接替它的工作。如果工作负载太高,也不能随意添加新的 broker 来分担。broker 之间必须进行状态同步。
在 Pulsar 架构中,broker 是无状态的。但是完全无状态的系统是无法用来持久化消息的,所以 Pulsar 其实是有维护在状态的,只是不是在 broker 上。在 Pulsar 架构中,数据的分发和保存是相互独立的。broker 从生产者接收数据,然后将数据发送给消费者,但数据是保存在 BookKeeper 中的。
因为 Pulsar 的 broker 是无状态的,所以如果工作负载很高,就可以直接添加新的 broker。
5. 简单的跨域复制
跨域复制是 Pulsar 的拿手好戏。Pulsar 在设计之初就考虑到了这个特性,配置也很容易。要搭建一个全球化的分布式 Pulsar 集群,并不需要你拥有博士学位。
6. 稳定的表现
一些基准测试(http://openmessaging.cloud/docs/benchmarks/pulsar/)表明,Pulsar 可以在提供较高吞吐量的同时保持较低的延迟。
7. 完全开源
Pulsar 提供了很多与 Kafka 相似的特性,比如跨域复制、流式消息处理(Pulsar Function)、连接器(Pulsar IO)、基于 SQL 的主题查询(Pulsar SQL)、schema registry,还有一些 Kafka 没有的特性,比如分层存储和多租户,所有这些特性都是开源的。
3.pulsar特点
1.Pulsar函数
使用友好的API轻松部署轻量级计算逻辑,无需其它的流处理引擎
2. 水平扩展
将容量无缝扩展到成百上千个节点
3.高吞吐
已经在Yahoo的生产环境中经受了考验,每秒数百万消息
4.低延迟
设计用于大规模的低延迟(<5ms)场景,具有强大的耐用性保证
5.Geo-replication地域复制
专为跨多个地理区域的数据中心之间的可配置复制而设计
6.多租户
构建为多租户系统。支持隔离,身份验证,授权和配额
7.持久存储
基于Apache BookKeeper的持久消息存储。提供写入和读取操作之间的IO级隔离
8.客户端库
灵活的消息传递模型,包含用于Java,C ++,Python和GO的高级API
9.可操作性
REST Admin API,用于配置,管理,工具和监视。部署在裸机或Kubernetes上。
4.架构概述
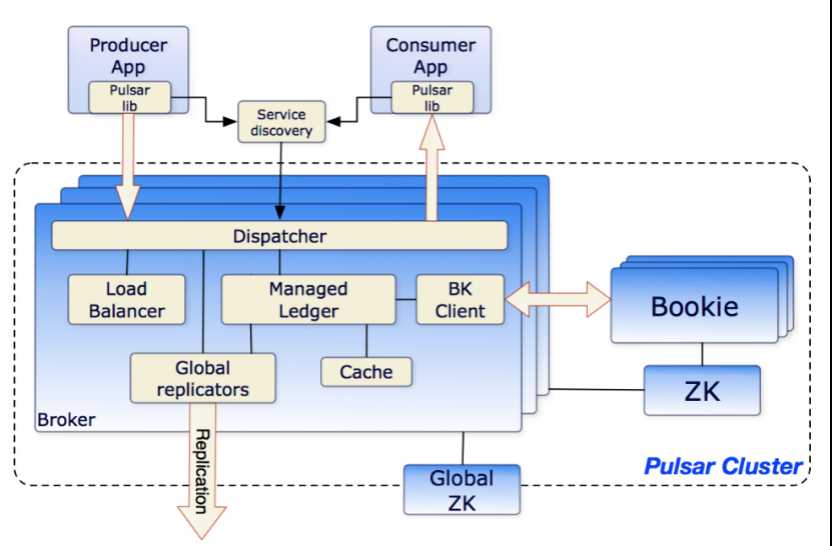
在最上层来看,一个Pulsar实例由一个或多个Pulsar本地集群组成。实例中的本地集群之间可以相互复制数据。
一个Pulsar本地的集群由下面三部分组成:
一个或者多个brokers负责处理和负载均衡从生产者源源不断发送出的消息,并将他们发送给消费者。它与配置存储交互来处理相应的任务,它将消息存储在BookKeeper实例中(aka bookies)。它依赖ZooKeeper集群处理特定的任务,等等。
一个包含一个或者多个Bookies的BookKeeper,这个BookKeeper主要负责消息的 持久化存储。
一个Pulsar全局的集群(实例)包含Global-Zookeeper服务。
5. 组件角色描述
1.Brokers
Pulsar的broker是一个无状态组件, 主要负责运行另外的两个组件:
一个 HTTP 服务器, 它暴露了 REST 系统管理接口以及在生产者和消费者之间进行 Topic查找的API。
一个调度分发器, 它是异步的TCP服务器,通过自定义 二进制协议应用于所有相关的数据传输。
2.Zookeeper
Pulsar利用Zookeeper进行元数据存储,集群配置和协调。在一个Pulsar实例中:
配置与仲裁存储: 存储租户,命名域和其他需要全局一致的配置项。
每个本地集群有自己独立的ZooKeeper保存集群内部配置和协调信息,例如归属信息,broker负载报告,BookKeeper ledger信息(这个是BookKeeper本身所依赖的),等等。
3.Global-Zookeeper
Pulsar利用Global -Zookeeper进行全局集群的元数据存储,集群配置和协调。使用Zookeeper的Observer角色,提高伸缩性,部署跨地区的ZooKeeper数据中心。
4.BookKeeper
Pulsar用 BookKeeper作为持久化存储。BookKeeper是一个分布式的预写日志(WAL)系统,有如下几个特性特别适合Pulsar的应用场景:
能让Pulsar创建多个独立的日志,这种独立的日志就是ledgers. 随着时间的推移,Pulsar会为Topic创建多个ledgers。
为按条目复制的顺序数据提供了非常高效的存储。
保证了多系统挂掉时ledgers的读取一致性。
提供不同的Bookies之间均匀的IO分布的特性。
容量和吞吐量都能水平扩展。并且容量可以通过在集群内添加更多的Bookies立刻提升。
Bookies被设计成可以承载数千的并发读写的ledgers。使用多个磁盘设备,一个用于日志,另一个用于一般存储,这样Bookies可以将读操作的影响和对于写操作的延迟分隔开。
5.Pulsar proxy
Pulsar客户端和Pulsar集群交互的一种方式就是直连Pulsar brokers 。 然而,在某些情况下,这种直连既不可行也不可取,因为客户端并不知道broker的地址。例如在云环境或者 Kubernetes 以及其他类似的系统上面运行Pulsar,直连brokers就基本上不可能了。
Pulsar proxy提供了解决这个问题的方案,它可以作为集群中的所有brokers的统一网关。 如果你选择运行Pulsar Proxy(这是可选的),所有的客户端连接将会通过这个代理而不是直接与brokers通信。
6.Service discovery
连接到Pulsar Broker的客户端需要能够使用单个URL与整个Pulsar实例进行通信。Pulsar提供了一个内置的服务发现机制。
6.订阅模型
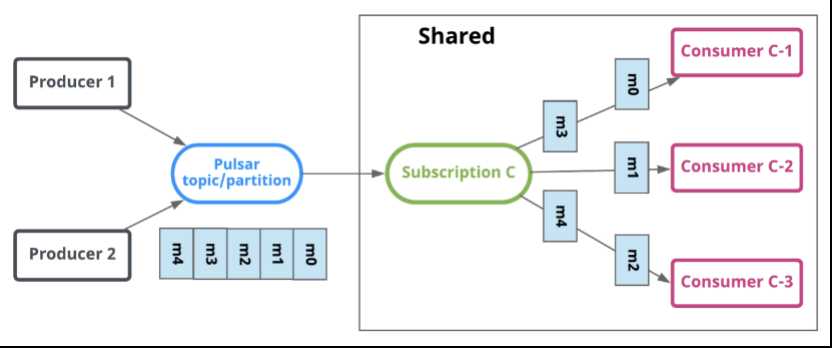
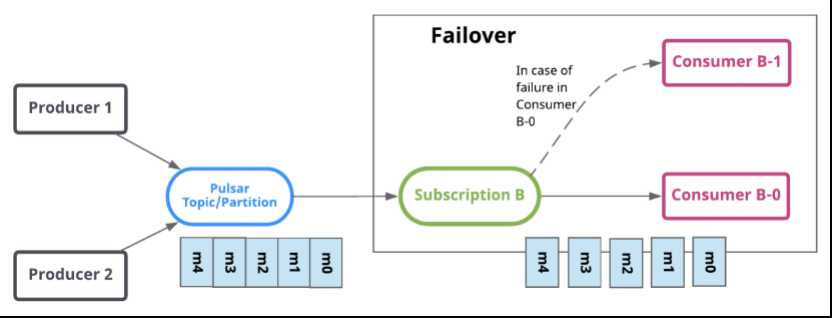
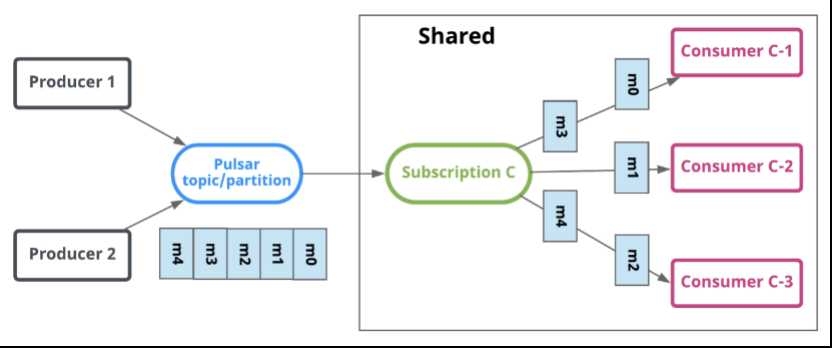
订阅是命名好的配置规则,指导消息如何投递给消费者。 Pulsar有三种订阅模式:exclusive,shared,failover。下图展示了这三种模式:
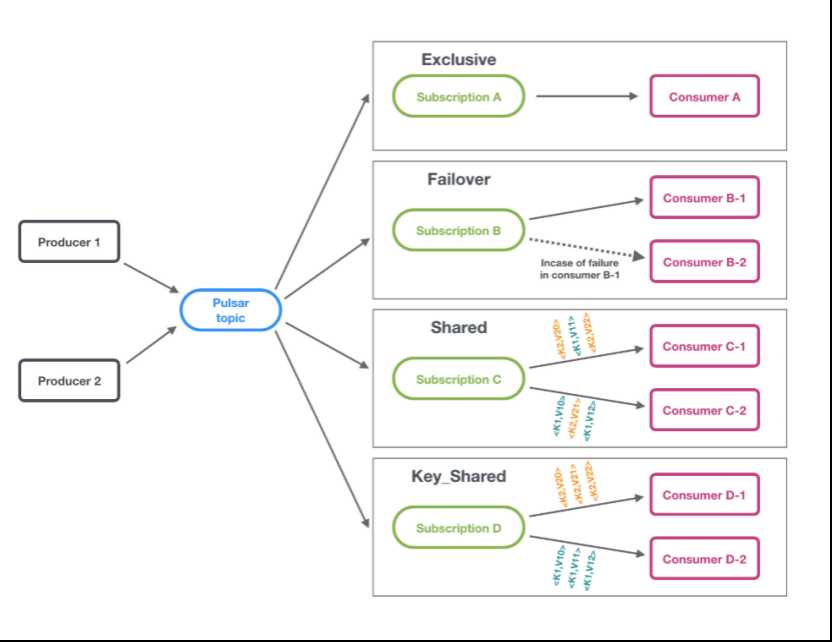
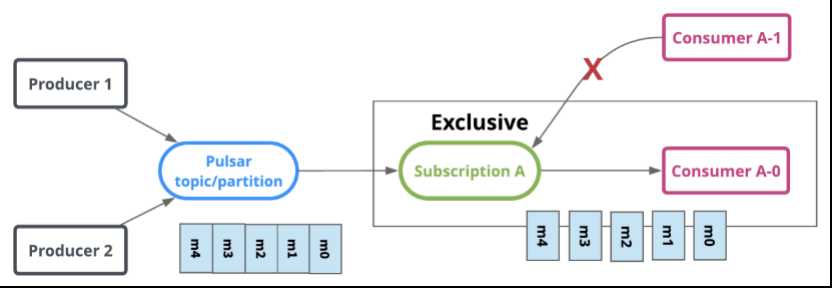
Exclusive(独占)
独占模式,只能有一个消费者绑定到订阅上。 如果多于一个消费者尝试以同样方式去订阅主题,消费者将会收到错误。
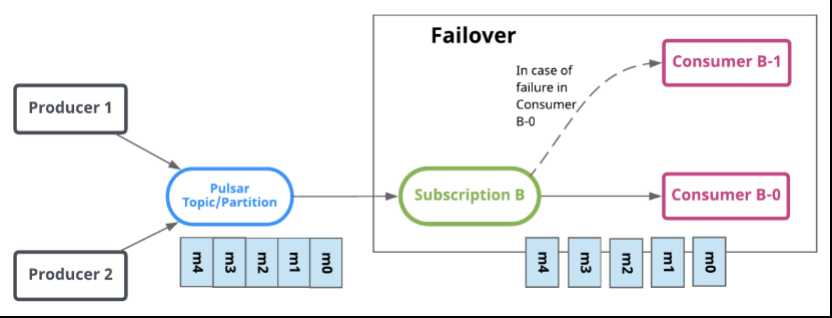
Failover(灾备)
Failover模式中,多个consumer可以绑定到同一个subscription。consumer将会按字典顺序排序,第一个consumer被初始化为唯一接受消息的消费者。这个consumer被称为master consumer。
当master consumer断开时,所有的消息(未被确认和后续进入的)将会被分发给队列中的下一个consumer。
Shared(共享)
share或者round robin模式中,多个消费者可以绑定到同一个订阅上。消息通过round robin轮询机制分发给不同的消费者,并且每个消息仅会被分发给一个消费者。当消费者断开连接,所有被发送给他,但没有被确认的消息将被重新安排,分发给其它存活的消费者。
注意:
Shared模式的限制,使用shared模式时,需要重点注意以下两点: * 消息的顺序无法保证。* 你不可以使用累积确认。
累积消息确认不能用于共享订阅模式,因为共享模式中,一个订阅会涉及到多个消费者。
Key_shared
在Key_shared共享模式下,多个消费者可以附加到同一订阅。消息在跨消费者的分发中传递,具有相同key或相同订购key的消息仅传递给一个消费者。无论消息被重新传递多少次,它都会被传递给同一个消费者。当使用者连接或断开连接时,将导致服务的消费者更改某些消息的key。
多主题订阅
当consumer订阅pulsar的主题时,它默认指定订阅了一个主题,例如:persistent://public/default/my-topic。
Pulsar消费者可以同时订阅多个topic。可以用以下两种方式定义topic的列表:
通过最基础的 正则表达式(regex),例如 persistent://public/default/finance-.*
通过明确指定的topic列表
注意:
通过正则订阅多主题时,所有的主题必须在同一个namespace。
当订阅多主题时,Pulsar客户端会自动调用Pulsar的API来发现匹配表达式或者列表的所有topic,然后全部订阅。如果此时有暂不存在的topic,那么一旦这些topic被创建,conusmer会自动订阅。
不能保证顺序性,当消费者订阅多主题时,Pulsa所提供对单一主题订阅的顺序保证,就hold不住了。如果你在使用Pulsar的时候,遇到必须保证顺序的需求,我们强烈建议不要使用此特性。
7. 其他核心问题
1.死信主题
死信主题能够在某些消息无法由consumer成功消费时消费新消息。在这种机制中,无法消费的消息存储在一个单独的主题中,称为死信主题。开发人员可以决定如何处理死信主题中的消息。
死信主题取决于消息的重新传递。由于确认超时或否定确认,消息将重新传递。如果要对消息使用否定确认,请确保在确认超时之前对其进行否定确认。
注意:
目前,死信主题仅在共享订阅模式下启用。
如果不指定死信主题,默认会创建一个,格式如下:
<topicname>-<subscriptionname>-DLQ
2.消息保留和到期
Pulsar broker默认如下:
立即删除所有已经被消费者确认过的的消息
以消息backlog的形式,持久保存所有的未被确认消息
Pulsar有两个特性,让你可以覆盖上面的默认行为。
消息存留可以保存消费确认过的消息
消息过期可以给未被确认的消息设置存活时长(TTL)
3.消息去重
当消息被Pulsar持久化多于一次的时候,消息就会重复。消息去重是Pulsar可选的特性,阻止不必要的消息重复,每条消息仅处理一次,即使消息被接收多次。
broker是通过sequence_id判断消息是否重复,出现重复的原因可能是网络超时,发送或ack失败导致。
通过修改配置文件决定是否开启去重的功能,默认是不去重。
如果在Pulsar broker中启用消息重复数据删除,则无需对Pulsar客户端进行任何重大更改。但是,需要为客户端生产者提供两种设置:
生产者必须设置一个名字
消息发送超时需要设置为无穷大(即没有超时)
8.pulsar应用
腾讯计费(米大师)(https://cloud.tencent.com/product/midas) 是孵化于支撑腾讯内部业务千亿级营收的互联网计费平台,汇集国内外主流支付渠道,提供账户管理、精准营销、安全风控、稽核分账、计费分析等多维度服务。平台承载了公司每天数亿收入大盘,为 180+ 个国家(地区)、万级业务代码、100W+ 结算商户提供服务,托管账户总量300 多亿,是一个全方位的一站式计费平台。
9.pulsar搭建试用
1.系统要求
Pulsar目前适用于MacOS和Linux
默认情况下,Pulsar会分配2G JVM堆内存来启动。它可以在conf/pulsar_env.sh文件下更改PULSAR_MEM
2. 集群组成说明
搭建Pulsar集群至少需要3个组件:ZooKeeper集群、BookKeeper集群和broker集群(Broker是Pulsar的自身实例)。3个集群组件如下:
本地ZooKeeper集群(3个ZooKeeper节点组成)
bookie集群(也称为BookKeeper集群,3个BookKeeper节点组成)
broker集群(3个Pulsar节点组成)
Pulsar的安装包已包含了搭建集群所需的各个组件库。无需单独下载ZooKeeper安装包和BookKeeper安装包。
下载Pulsar安装包apache-pulsar-2.5.1-bin.tar.gz
3.准备资源
|
主机 |
系统版本 |
JDK版本 |
Pulsar版本 |
|
192.168.10.10 |
CentOS 7.2 |
1.8 |
2.5.1 |
|
192.168.10.11 |
CentOS 7.2 |
1.8 |
2.5.1 |
|
192.168.10.12 |
CentOS 7.2 |
1.8 |
2.5.1 |
4.创建集群环境
把下载的 Pulsar 安装包上传到 Linux 服务器,解压安装包。
# 解压安装包
tar -zxvf apache-pulsar-2.5.1-bin.tar.gz -C /opt
5.配置部署本地 ZooKeeper 集群
1.新建文件夹,并写入配置内容。
#修改zookeeper的端口
clientPort=12181
# 在/opt/apache-pulsar-2.5.1目录中新建文件目录
mkdir -p data/zookeeper
# 新建文件 myid,写入 1
echo 1 > data/zookeeper/myid
注意:
另外两台服务器的 myid 文件内容分别写入 2 和 3。
# 服务器 2
mkdir -p data/zookeeperecho 2 > data/zookeeper/myid
# 服务器 3
mkdir -p data/zookeeperecho 3 > data/zookeeper/myid
2.配置 zookeeper.conf 文件。
# 指定dataDir目录dataDir=/opt/apache-pulsar-2.5.1/data/zookeeper
# zookeeper 节点地址
server.1=192.168.10.10:12888:13888
server.2=192.168.10.11:12888:13888
server.3=192.168.10.12:12888:13888
注意:在另外两台服务器上,对 zookeeper.conf 文件进行完全相同的配置。
3. 在/opt/apache-pulsar-2.5.1目录中,执行启动命令。
# 进入 zookeepers 目录
cd /opt/apache-pulsar-2.5.1
# 执行后台运行命令
bin/pulsar-daemon start zookeeper
4. 验证 ZooKeeper 节点是否启动成功。
# 进入 zookeepers 目录
cd /opt/apache-pulsar-2.5.1
# 执行 zookeeper 客户端连接命令
bin/pulsar zookeeper-shell -server 192.168.10.10:12181
注意:
Enter键进入命令行界面后,可完全使用ZooKeeper的各种命令,如 ls、get等命令。使用 quit 命令退出命令行界面。
1. 按照以上步骤,在另外两台服务器上部署 ZooKeeper 节点。
5. 在任一个Pulsar节点,初始化集群元数据。
# 进入 zookeepers 目录
cd /opt/apache-pulsar-2.5.1
# 执行命令初始化集群元数据
bin/pulsar initialize-cluster-metadata
--cluster pulsar-cluster
--zookeeper 192.168.10.10:12181
--configuration-store 192.168.10.10:12181
--web-service-url http://192.168.10.10:8083/
--web-service-url-tls https://192.168.10.10:8443/
--broker-service-url pulsar://192.168.10.10:6650/
--broker-service-url-tls pulsar+ssl://192.168.10.10:6651/
6.配置部署 BookKeeper 集群
1. 修改配置文件 bookkeeper.conf。
# 进入bookie 配置文件目录
cd /opt/apache-pulsar-2.5.1/conf
# 编辑 bookkeeper.conf 文件
vim bookkeeper.conf
# advertisedAddress 修改为服务器对应的ip,在另外两台服务器也做对应的修改advertisedAddress=192.168.10.10
# 修改以下两个文件目录地址journalDirectories=/mnt/disk01/data/bookkeeper/journal
ledgerDirectories=/mnt/disk01/data/bookkeeper/ledger
# 修改zk地址和端口信息zkServers=192.168.10.10:12181, 192.168.10.11:12181, 192.168.10.12:12181
# 修改Prometheus指标采集端口,该端口不修改会冲突
prometheusStatsHttpPort=8100
# 修改httpServerEnabled
httpServerEnabled=true
# 修改httpServerPort
httpServerPort=8100
2. 初始化元数据,并启动 bookie 集群。
# 先执行初始化元数据命令;再执行启动命令
# 进入 bookies 目录
cd /opt/apache-pulsar-2.5.1
# 执行初始化元数据命令;若出现提示,输入 Y,继续(只需在一个bookie节点执行一次)
bin/bookkeeper shell metaformat
# 以后台进程启动bookie
bin/pulsar-daemon start bookie
3. 按照以上步骤,启动另外两个 bookie 节点。
4. 验证 bookie 是否启动成功。
# 进入 bookies 目录
cd /opt/apache-pulsar-2.5.1
# 验证是否启动成功
bin/bookkeeper shell bookiesanity
# 出现如下显示,表示启动成功Bookie
sanity test succeeded.
7.部署配置 Broker 集群
1. 修改配置文件 broker.conf。
# 进入配置文件目录
cd /opt/apache-pulsar-2.5.1/conf
# 编辑 broker.conf 文件
# 修改集群名,和ZooKeeper里初始化元数据时指定的集群名(--cluster pulsar-cluster)相同
clusterName=pulsar-cluster
# 修改如下两个配置,指定的都是ZooKeeper集群地址和端口号zookeeperServers=192.168.10.10:12181, 192.168.10.11:12181, 192.168.10.12:12181
configurationStoreServers=192.168.10.10:12181, 192.168.10.11:12181, 192.168.10.12:12181
# 修改如下参数为本服务器ip地址,另外两个broker节点配置文件也做对应修改advertisedAddress=192.168.10.10
# 修改brokerServicePortTls端口
brokerServicePortTls=6651
# 修改webServicePortTls端口
webServicePortTls=8443
# 修改brokerDeleteInactiveTopicsEnabled,默认非活动的topic会被删除
brokerDeleteInactiveTopicsEnabled=false
2. 启动 broker 节点。
# 进入 brokers 目录
cd /opt/apache-pulsar-2.5.1
# 以后台进程启动 broker
bin/pulsar-daemon start broker
3. 按照以上步骤,对另外两个 broker 节点做对应配置,并启动 broker 节点。
4. 查看集群中 brokers 节点信息,验证 broker 是否都启动成功。
# 进入任一个 broker 目录
cd /opt/apache-pulsar-2.5.1
# 查看集群 brokers 节点情况
bin/pulsar-admin brokers list pulsar-cluster
至此,集群 ZooKeeper,Broker,Bookie 节点启动完毕,集群部署成功!接下来可以进行 HelloWorld 测试!
8.测试Pulsar
1. 依次创建集群、租户、命名空间、分区 topic,并为命名空间指定集群名。
# 进入 brokers 目录,选取任一个 broker 节点执行命令即可
cd /opt/apache-pulsar-2.5.1
# 创建集群(集群名:pulsar-cluster)
bin/pulsar-admin clusters create pulsar-cluster1
# 创建租户(租户名:my-tenant)
bin/pulsar-admin tenants create my-tenant
# 创建命名空间(命名空间名:my-tenant/my-namespace,它指定了租户 my-tenant)
bin/pulsar-admin namespaces create my-tenant/my-namespace
# 创建持久性分区topic(topic全名:persistent://my-tenant/my-namespace/my-topic;分区数为 3)
bin/pulsar-admin topics create-partitioned-topic persistent://my-tenant/my-namespace/my-topic -p 3
# 更新命名空间为其指定集群名
bin/pulsar-admin namespaces set-clusters my-tenant/my-namespace --clusters pulsar-cluster
2. 设置 maven 依赖。
<dependency>
<groupId>org.apache.pulsar</groupId>
<artifactId>pulsar-client</artifactId>
<version>2.5.1</version>
</dependency>
3. 创建生产者
public class PulsarProducerDemo3 {
// 连接集群 broker
private static String localClusterUrl = "pulsar://192.168.10.10:6650";
public static void main(String[] args) {
try {
Producer<byte[]> producer = getProducer();
String msg = "hello world pulsar!";
Long start = System.currentTimeMillis();
MessageId msgId = producer.send(msg.getBytes());
System.out.println("spend=" + (System.currentTimeMillis() - start) + ";send a message msgId = " + msgId.toString());
} catch (Exception e) {
System.err.println(e);
}
}
public static Producer<byte[]> getProducer() throws Exception {
PulsarClient client;
client = PulsarClient.builder().serviceUrl(localClusterUrl).build();
Producer<byte[]> producer = client.newProducer().topic("persistent://my-tenant/my-namespace/my-topic").producerName("producerName").create();
return producer;
}
}
4. 创建消费者。
public class PulsarConsumerDemo3 {
private static String localClusterUrl = "pulsar:// 192.168.10.10:6650";
public static void main(String[] args) {
try {
//将订阅消费者指定的主题消息
Consumer<byte[]> consumer = getClient().newConsumer()
.topic("persistent://my-tenant/my-namespace/my-topic")
.subscriptionName("my-subscription")
.subscribe();
while (true) {
Message msg = consumer.receive();
System.out.printf("consumer-Message received: %s.
", new String(msg.getData()));
// 确认消息,以便broker删除消息
consumer.acknowledge(msg);
}
} catch (Exception e) {
System.out.println(e);
}
}
public static PulsarClient getClient() throws Exception {
PulsarClient client;
client = PulsarClient.builder().serviceUrl(localClusterUrl).build();
return client;
}
}
10.Pulsar函数
1.简述
开发人员使用友好的API轻松部署轻量级计算逻辑,无需运行其他流处理引擎。
Pulsar函数是轻量级的计算过程:
使用来自一个或多个Pulsar主题的消息,
将开发人员提供的处理逻辑应用于每条消息,
将计算结果发布到另一个主题。
Pulsar函数非常适合简单的数据(交易流水)清洗清洗场景。
2.Java的函数说明
在Java中编写Pulsar函数涉及实现两个接口之一:
java.util.function.Function接口。
org.apache.pulsar.functions.api接口,此接口的工作方式与java.util.function.Function接口非常相似,但主要的区别在于它提供了一个Context 对象,开发人员可以通过各种方式使用它。
函数分为function和 window function,window function通过记录数和时间限制窗口的大小。
3.资源准备
1. 配置functions-worker
在Pulsar集群所有节点启动functions-worker服务。
在/opt/apache-pulsar-2.5.1目录中,修改配置文件functions_worker.yml
# 进入Pulsar目录
cd /opt/apache-pulsar-2.5.1
# 编辑functions_worker.yml
vim functions_worker.yml
# 修改workerId
workerId: worker79
# 修改workerHostname
workerHostname: 192.168.10.10
# 修改workerPort
workerPort: 6750
# 修改workerPortTls
workerPortTls: 6751
# 修改configurationStoreServers
configurationStoreServers: 192.168.10.10:12181
# 修改pulsarServiceUrl
pulsarServiceUrl: pulsar://192.168.10.10:6650
# 修改pulsarWebServiceUrl
pulsarWebServiceUrl: http://192.168.10.10:8083
# 修改pulsarFunctionsCluster,Pulsar集群名称
pulsarFunctionsCluster: pulsar-cluster
注意:在另外两台服务器上,对 functions_worker.yml文件进行相应的配置。
2. 启动functions-worker
在Pulsar集群的所有节点上执行以下命令
# 进入 Pulsar文件目录
cd /opt/apache-pulsar-2.5.1
# 启动function服务
bin/pulsar-daemon start functions-worker
4. 测试函数
1. 设置maven依赖
<dependency> <groupId>org.apache.pulsar</groupId> <artifactId>pulsar-functions-api</artifactId> <version>2.5.1 </version> </dependency>
2. 编写代码
public class ExclamationFunction implements Function<String, String> { @Override public String process(String input, Context context) { Logger LOG = context.getLogger(); LOG.info("======process input======:{}", input); return String.format("%s!", input); } }
3. 编译生成api-examples.jar
4. 上传api-examples.jar到Pulsar目录/opt/apache-pulsar-2.5.1/examples
5. 提交函数
bin/pulsar-admin-function functions create --processing-guarantees ATMOST_ONCE -- max-message-retries -1 --jar examples/api-examples.jar --classname org.apache.pulsar.functions.api.examples.ExclamationFunction --inputs persistent://public/default/exclamation-input --output persistent://public/default/exclamation-output --name exclamation
6. 查看函数信息
bin/pulsar-admin-function functions get
--tenant public
--namespace default
--name exclamation
7. 查看函数运行状态
bin/pulsar-admin-function functions getstatus --tenant public --namespace default --name exclamation
8. 查看函数日志
在函数运行状态上可以看到function运行时所属的节点,到运行的节点上,查看日志
cd /opt/apache-pulsar-2.5.1/logs/functions/public/default
# 选择exclamation函数日志目录
cd exclamation
# 打开日志文件
vim exclamation-0.log
5. 分配function运行时的资源
|
资源 |
描述. |
运行时 |
|
CPU |
核数 |
Docker (即将推出) |
|
RAM |
内存字节数 |
Process, Docker |
|
Disk |
磁盘字节数 |
Docker |
1. 通过以下命令指定资源
bin/pulsar-admin functions create --jar target/my-functions.jar --classname org.example.functions.MyFunction --cpu 8 --ram 8589934592 --disk 10737418240
2. Logging,日志定位
$ bin/pulsar-admin functions create --name my-func-1 --log-topic persistent://public/default/my-func-1-log # Other configs
6. 管理函数
管理pulsar函数时,需要指定有关这些函数的各种信息,包括租户、名称空间、输入和输出主题等。但是,有一些参数具有默认值,如果忽略,将提供这些默认值。下表列出了默认值:
默认参数示例:
|
参数 |
默认值 |
|
函数名 |
为函数指定名称,例如:标记--classname org.example.myFunction会给函数指定一个myFunction的名称。 |
|
租户 |
从输入主题的名称派生。如果输入主题位于marketing租户下的asia名称空间下,即主题名称的格式为persistent://marketing/asia/{topicName},则名称空间将为marketing。 |
|
名称空间 |
从输入主题的名称派生。如果输入主题位于marketing租户下的asia名称空间下,即主题名称的格式为persistent://marketing/asia/{topicName},则名称空间将为asia。 |
|
输出主题 |
{input topic}-{function name}-output。如何没有提供输出主题,函数默认会提供主题:incoming-exclamation-output。 |
|
订阅类型 |
对于至少一次且最多一次的处理保证,默认情况下应用共享;对于有效的一次保证,应用故障转移 |
|
处理保证 |
ATLEAST_ONCE(可用选项包括ATMOST_ONCE/ ATLEAST_ONCE/ EFFECTIVELY_ONCE) |
|
Pulsar服务URL |
pulsar://localhost:6650 |
7. 处理保证机制
1. 语义类型
Pulsar函数提供三种不同的消息传递语义,可以将其应用于任何函数。
|
传递语义 |
描述 |
|
At-most-once |
发送到函数的每个消息都可能被处理,或者不被处理(因此“最多”)。 |
|
At-least-once |
发送到函数的每个消息都可以处理多次(因此“至少”)。 |
|
Effectively-once |
发送到函数的每条消息都将有一条与其相关联的输出。 |
2. 语义测试
提交函数后查看function日志,处理保证的类型与订阅类型关联,如下:
1.EFFECTIVELY_ONCE
##############################EFFECTIVELY_ONCE#################################
PulsarSourceConfig(
processingGuarantees=EFFECTIVELY_ONCE,
subscriptionType=Failover,
subscriptionName=public/default/exclamation,
maxMessageRetries=-1,
deadLetterTopic=null,
topicSchema={
persistent://public/default/exclamation-input=ConsumerConfig(
schemaType=null,
serdeClassName=null,
isRegexPattern=false,
receiverQueueSize=null)},
typeClassName=java.lang.String,
timeoutMs=null)
通过SourceConfig可以看出处理保证为EFFECTIVELY_ONCE,订阅类型是FAILOVER,如下图:
Starting Pulsar consumer perf with config: {
"topicNames" : [ "persistent://public/default/exclamation-input" ],
"topicsPattern" : null,
"subscriptionName" : "public/default/exclamation",
"subscriptionType" : "Failover",
"receiverQueueSize" : 1000,
"acknowledgementsGroupTimeMicros" : 100000,
"negativeAckRedeliveryDelayMicros" : 60000000,
"maxTotalReceiverQueueSizeAcrossPartitions" : 50000,
"consumerName" : null,
"ackTimeoutMillis" : 0,
"tickDurationMillis" : 1000,
"priorityLevel" : 0,
"cryptoFailureAction" : "CONSUME",
"properties" : {
"application" : "pulsar-function",
"id" : "public/default/exclamation",
"instance_id" : "0"
},
"readCompacted" : false,
"subscriptionInitialPosition" : "Latest",
"patternAutoDiscoveryPeriod" : 1,
"regexSubscriptionMode" : "PersistentOnly",
"deadLetterPolicy" : null,
"autoUpdatePartitions" : true,
"replicateSubscriptionState" : false,
"resetIncludeHead" : false
}
PulsarSinkConfig(
processingGuarantees=EFFECTIVELY_ONCE, topic=persistent://public/default/exclamation-output,
serdeClassName=null,
schemaType=null,
typeClassName=java.lang.String)
2.ATMOST_ONCE
############################ ATMOST_ONCE######################################
PulsarSourceConfig(
processingGuarantees=ATMOST_ONCE,
subscriptionType=Shared,
subscriptionName=public/default/exclamation,
maxMessageRetries=-1,
deadLetterTopic=null,
topicSchema={
persistent://public/default/exclamation-input=ConsumerConfig(
schemaType=null,
serdeClassName=null,
isRegexPattern=false,
receiverQueueSize=null)},
typeClassName=java.lang.String,
timeoutMs=null)
处理保证为ATMOST_ONCE,订阅类型是Shared,如下图:

Starting Pulsar consumer perf with config: {
"topicNames" : [ "persistent://public/default/exclamation-input" ],
"topicsPattern" : null,
"subscriptionName" : "public/default/exclamation",
"subscriptionType" : "Shared",
"receiverQueueSize" : 1000,
"acknowledgementsGroupTimeMicros" : 100000,
"negativeAckRedeliveryDelayMicros" : 60000000,
"maxTotalReceiverQueueSizeAcrossPartitions" : 50000,
"consumerName" : null,
"ackTimeoutMillis" : 0,
"tickDurationMillis" : 1000,
"priorityLevel" : 0,
"cryptoFailureAction" : "CONSUME",
"properties" : {
"application" : "pulsar-function",
"id" : "public/default/exclamation",
"instance_id" : "0"
},
"readCompacted" : false,
"subscriptionInitialPosition" : "Latest",
"patternAutoDiscoveryPeriod" : 1,
"regexSubscriptionMode" : "PersistentOnly",
"deadLetterPolicy" : null,
"autoUpdatePartitions" : true,
"replicateSubscriptionState" : false,
"resetIncludeHead" : false
}
Starting Pulsar producer perf with config: {
"topicName" : "persistent://public/default/exclamation-output",
"producerName" : null,
"sendTimeoutMs" : 0,
"blockIfQueueFull" : true,
"maxPendingMessages" : 1000,
"maxPendingMessagesAcrossPartitions" : 50000,
"messageRoutingMode" : "CustomPartition",
"hashingScheme" : "Murmur3_32Hash",
"cryptoFailureAction" : "FAIL",
"batchingMaxPublishDelayMicros" : 10000,
"batchingMaxMessages" : 1000,
"batchingEnabled" : true,
"batcherBuilder" : { },
"compressionType" : "LZ4",
"initialSequenceId" : null,
"autoUpdatePartitions" : true,
"properties" : {
"application" : "pulsar-function",
"id" : "public/default/exclamation",
"instance_id" : "0"
}
}
3.ATLEAST_ONCE
##############################ATLEAST_ONCE####################################
PulsarSourceConfig(
processingGuarantees=ATLEAST_ONCE,
subscriptionType=Shared,
subscriptionName=public/default/exclamation,
maxMessageRetries=-1,
deadLetterTopic=null,
topicSchema={
persistent://public/default/exclamation-input=ConsumerConfig(
schemaType=null,
serdeClassName=null,
isRegexPattern=false,
receiverQueueSize=null)},
typeClassName=java.lang.String,
timeoutMs=null)
处理保证为ATLEAST_ONCE,订阅类型是Shared,如下图:
Starting Pulsar consumer perf with config: {
"topicNames" : [ "persistent://public/default/exclamation-input" ],
"topicsPattern" : null,
"subscriptionName" : "public/default/exclamation",
"subscriptionType" : "Shared",
"receiverQueueSize" : 1000,
"acknowledgementsGroupTimeMicros" : 100000,
"negativeAckRedeliveryDelayMicros" : 60000000,
"maxTotalReceiverQueueSizeAcrossPartitions" : 50000,
"consumerName" : null,
"ackTimeoutMillis" : 0,
"tickDurationMillis" : 1000,
"priorityLevel" : 0,
"cryptoFailureAction" : "CONSUME",
"properties" : {
"application" : "pulsar-function",
"id" : "public/default/exclamation",
"instance_id" : "0"
},
"readCompacted" : false,
"subscriptionInitialPosition" : "Latest",
"patternAutoDiscoveryPeriod" : 1,
"regexSubscriptionMode" : "PersistentOnly",
"deadLetterPolicy" : null,
"autoUpdatePartitions" : true,
"replicateSubscriptionState" : false,
"resetIncludeHead" : false
}
PulsarSinkConfig(
processingGuarantees=ATLEAST_ONCE,
topic=persistent://public/default/exclamation-output,
serdeClassName=null,
schemaType=null,
typeClassName=java.lang.String)
Starting Pulsar producer perf with config: {
"topicName" : "persistent://public/default/exclamation-output",
"producerName" : null,
"sendTimeoutMs" : 0,
"blockIfQueueFull" : true,
"maxPendingMessages" : 1000,
"maxPendingMessagesAcrossPartitions" : 50000,
"messageRoutingMode" : "CustomPartition",
"hashingScheme" : "Murmur3_32Hash",
"cryptoFailureAction" : "FAIL",
"batchingMaxPublishDelayMicros" : 10000,
"batchingMaxMessages" : 1000,
"batchingEnabled" : true,
"batcherBuilder" : { },
"compressionType" : "LZ4",
"initialSequenceId" : null,
"autoUpdatePartitions" : true,
"properties" : {
"application" : "pulsar-function",
"id" : "public/default/exclamation",
"instance_id" : "0"
}
}
11. Dashboard
1. 说明
Pulsar自带Docker版本的Dashboard,对集群Broker、Bookie、ZooKeeper及Topic等进行监控和统计。
以下在CentOS使用Prometheus+Grafana搭建Pulsar集群监控Dashboard。实现对NameSpace、Topic、Broker、Bookie、ZooKeeper等指标和组件进行监控和统计。
2. 准备资源
一台CentOS裸机服务器:192.168.10.10。
Prometheus 安装包(版本号 2.12.0)。
Grafana 安装包(版本号 6.3.5)。
3. 下载解压 Prometheus、Grafana 安装包
# Prometheus 安装包下载地址
https://github.com/prometheus/prometheus/releases/download/v2.12.0/prometheus-2.12.0.linux-amd64.tar.gz
# 解压安装包
tar -zxvf prometheus-2.12.0.linux-amd64.tar.gz
# Grafana 安装包下载地址
https://dl.grafana.com/oss/release/grafana-6.3.5.linux-amd64.tar.gz
# 解压安装包
tar -zxvf grafana-6.3.5.linux-amd64.tar.gz
# 解压后,我的文件路径如下
# /opt/prometheus-2.12.0.linux-amd64
# /opt/grafana-6.3.5
4. 配置Prometheus的prometheus.yml 配置文件
1. 修改集群名(cluster: pulsar-cluster)
2. 配置 broker 节点、IP 和端口号
3. 配置 bookie 节点、IP 和端口号
4. 配置 ZooKeeper 节点、IP 和端口号
说明:
1. 测试集群是3台CentOS服务器。每台服务器上都部署一个broker节点、一个bookie节点、一个ZooKeeper节点。
2. 3台服务器的测试环境IP地址设定如下:
192.168.10.10
192.168.10.11
192.168.10.12
3. 集群名为pulsar-cluster。若在搭建Pulsar集群的过程中,没有修改端口号,则只需要参照如下配置文件修改集群名和机器IP地址即可。
4. 部署监控的机器IP地址为
192.168.10.10。
5. prometheus.yml 文件示例
prometheus.yml文件模版下载地址:(https://github.com/streamnative/apache-pulsar-grafana-dashboard/blob/master/prometheus/standalone.yml.template)
根据实际情况进行修改。以下是一个 prometheus.yml 文件示例:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
external_labels:
cluster: pulsar-cluster
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global ‘evaluation_interval‘.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it‘s Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "broker"
honor_labels: true # don‘t overwrite job & instance labels
static_configs:
- targets: [‘192.168.10.10:8083‘,‘192.168.10.11:8083‘,‘192.168.10.12:8083‘]
- job_name: "bookie"
honor_labels: true # don‘t overwrite job & instance labels
static_configs:
- targets: [‘192.168.10.10:8100‘,‘192.168.10.11:8100‘,‘192.168.10.12:8100‘]
- job_name: "zookeeper"
honor_labels: true
static_configs:
- targets: [‘192.168.10.10:9990‘,‘192.168.10.11:9990‘,‘192.168.10.12:9990‘]
6. 后台启动Prometheus
# 进入Prometheus目录
cd /opt/prometheus-2.12.0.linux-amd64
# 以后台进程执行启动命令
nohup ./prometheus --config.file ./prometheus.yml --web.listen-address=192.168.10.10:9090 --web.enable-lifecycle --storage.tsdb.retention=10d >prometheus.log 2>&1 &
# 参数说明
# --config.file 指定 prometheus.yml 文件路径
# 指定监听地址端口
# --web.listen-address=192.168.10.10:9090
# --web.enable-lifecycle 启动时热加载配置文件使用
# --storage.tsdb.retention 指定统计数据存储时长,10d 代表10天
# >prometheus.log 2>&1 & 存储输出的启动日志
7. 访问Prometheus
1. 部署监控的机器ip为192.168.10.10
2. 在浏览器访问http://192.168.10.10:9090/graph
3. 能成功访问及运行成功
4. Prometheus做时序数据存储,以及提供强大的查询功能,Dashboard展示使用Grafana更漂亮专业,搭建配置Grafana
8. 后台启动 Grafana
# 进入 Grafana 文件目录
cd /opt/grafana-6.3.5/
# 以后台进程执行启动命令
nohup bin/grafana-server start >grafana.log 2>&1 &
9. 访问 Grafana
1. 部署监控的机器 ip为192.168.10.10
2. 在浏览器访问 http://192.168.10.10:3001
3. 出现如下图所示 Grafana 首页,输入默认用户名 admin,默认密码 admin。
10. 配置 Grafana 数据源
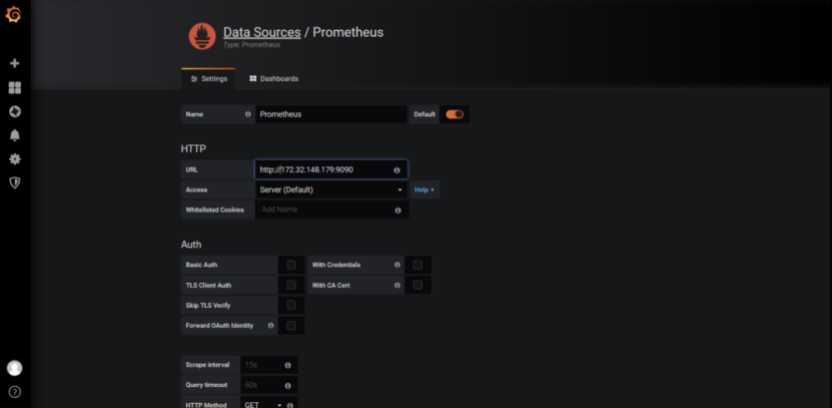
1. 添加 Prometheus 数据源。
2. 选择 Prometheus。

3. 配置 Prometheus 数据源。
11. 导入监控 Dashboard 模板
1. 从 Github 下载 Dashboard 模板。
2. 选择上传导入 Dashboard 模版(这里以 "Pulsar 集群总况.json" 模板为例)。
3. 导入成功,查看 Dashboard 面板统
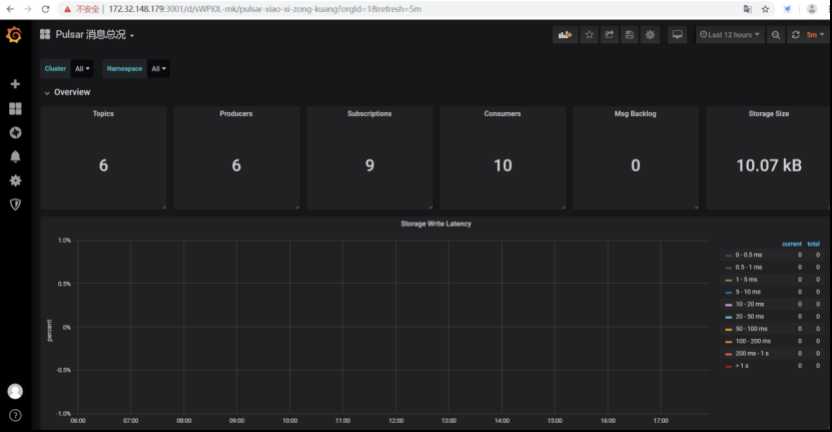
4. 依次导入Pulsar 消息总况.json、Pulsar Topic详情.json、Pulsar JVM监控.json,查看Dashboard,展示如下:
12 安全管理
1. 简述
作为企业的中央消息总线,Apache Pulsar经常用于存储关键任务数据。因此,在Pulsar中启用安全功能至关重要。
默认情况下,Pulsar不配置加密,身份验证或授权。任何客户端都可以通过纯文本服务URL与Apache Pulsar通信。因此,我们必须确保通过这些纯文本服务URL访问的Pulsar仅限于受信任的客户端。在这种情况下,您可以使用网络分段和/或授权ACL来限制对可信IP的访问。如果不使用,则群集的状态是敞开的,任何人都可以访问群集。
Pulsar支持可插拔的身份验证机制。Pulsar客户端使用此机制对代理和代理进行身份验证。还可以配置Pulsar以支持多个身份验证源。
2. 身份验证提供商
目前,Pulsar支持以下身份验证提供商:
TLS身份验证
Athenz
Kerberos
13 分层存储
Pulsar面向segment的架构允许topic backlog增长的十分庞大,如果有没加以限制,随着时间的增加,代价将越来越高。
有一个减轻这个消耗的办法,那就是使用分层存储。 通过分层存储,在backlog中的旧消息可以从BookKeeper转移到更连接的存储器中,如果不发生变化客户端仍然可以通过backlog去访问。
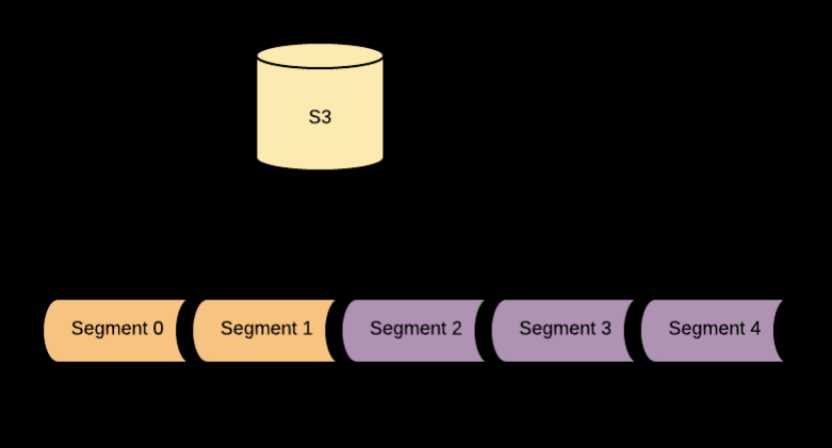
Pulsar目前支持亚马逊的S3以及Google云存储GCS来作为长期存储。可以通过Rest API或者命令行接口,将数据从短期数据卸载Offloading长期存储。用户传入他们想要保留在BookKeeper上的大量Topic数据,Broker会复制backlog数据到长期存储。通过一个可配置的延时(默认是4小时),与那时数据会从BookKeeper上被删除。
通过修改conf/broker.conf实现分层存储的功能。后续略
以上是关于云原生消息系统 Pulsar的主要内容,如果未能解决你的问题,请参考以下文章