对WMD: From Word Embedding to Document Distance的理解
Posted andre-ma
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对WMD: From Word Embedding to Document Distance的理解相关的知识,希望对你有一定的参考价值。
零、背景简介
- Word Embedding可有效表示不同词间的语义相似度(通常用欧式或余弦距离计算),使用BOW(Bag of words)或TF-IDF也能有效表示文档内不同关键词间的距离,但是上述2种方法在表示不同文档间的语义相似性时就显得不那么好用了。因此作者提出基于Word Embedding的WMD(Word Mover‘s Distance)算法来计算文档间的距离(或语义相似性)
- 该方法有效表示不同文档间的语义相似距离,算法无超参数且实现简单
- WMD算法在找出一篇文档的k个最相似文档的错误率表现已超过目前最好的7个baseline
一、基本概念解释
- 矩阵(X)是训练好的词库Embedding, d维,共n个单词
[X epsilon R^{ d imes n} ag 1
]
- (i^{th})表示词库中的第i个单词
- (X_iepsilon R^d) 表示第i个单词(在词库中索引)的embedding表示,每个单词都是d维
- (C_i)表示文档(d_i)中,第i个单词出现次数
- (d_i) 即标准化词袋模型(nBOW),表示单词i出现在当前文档中的总次数 / 当前文档所有词出现总次数之和(当然要去除停用词),个人理解某篇文档d同理应该是n维的,要用词库及索引表示文档,因此会很稀疏,具体如下(2)式:
[d_i = frac {C_i}{sum_{j=1}^{n} C_j} ag 2
]
- (C(i,j))为文档1中第i个词到文档2中第j个词间Embedding的欧式距离,具体如下(3)式
[C(i,j) = left | left | X_i - X_j
ight |
ight |_2 ag 3
]
- (T_{i,j})同样为n*n矩阵,表示文档1中第i个单词到文档2中第j个单词间的转移成本(也可理解为权重向量),其中(T_{i,j})非负
二、WMD算法
1.算法思想
计算不同文档间的语义相似度(或距离),先用不同文档的所有单词(去除停用词)通过单词出现数量加权和标准化来向量化表示文档,再计算不同文档向量之间各个单词的映射关系,即找出文档1中所有单词分别映射到文档2中具体哪些单词(该步骤计算使用word embedding计算欧氏距离),最后对匹配好的所有单词距离进行计算并sum为文档距离。 该算法没有考虑文档中单词出现的顺序,考虑到了单词出现的数量,考虑了单词的语义相似性,也考虑了同一意思的不同句子可以用不同单词表示的情况。由于WMD算法时间复杂度较大,同时给出了2中优化算法。
2.目标函数
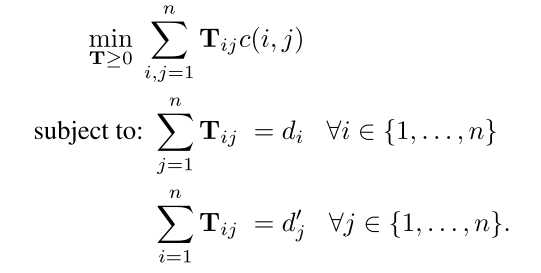
- 该目标函数表示计算文档1中的每一个单词i到文档2中的每一个单词的权重 和 embedding距离乘积的SUM, 其中有两个限制条件:
- 文档1中第i个单词转移到文档2中的每个单词的权重和等于(d_i)
- 文档1中的每一个单词转移到文档2中的第j个单词的权重和等于(d‘_j)
- 以上可表示为给定条件下的优化问题, 但平均时间复杂度是 (O(p^3log{p})),p表示文档中去除停用词的单词unique数, 由于时间复杂度过高,原文给出了2中优化算法
三、优化算法
1.WCD(Word Centroid Distance)
该算法使用了初中数学讲的基本不等式:(left | a
ight | + left | b
ight | geqslant left | a+b
ight |),并
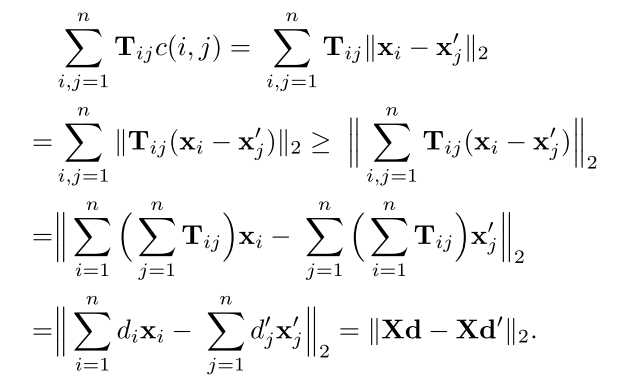

以上是关于对WMD: From Word Embedding to Document Distance的理解的主要内容,如果未能解决你的问题,请参考以下文章