GluonCV 0.6: Embrace Video Understanding
Posted king-lps
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GluonCV 0.6: Embrace Video Understanding相关的知识,希望对你有一定的参考价值。
GluonCV 0.6: Embrace Video Understanding
Author: Yi Zhu, Applied Scientist at Amazon
视频理解一直是一个趋势性的研究课题,因为分析动态视频可以帮助我们开发更好的计算机视觉算法,从而产生更强的人工智能。然而,视频研究存在着数据量大、实验周期长、缺乏可重复的编码库、缺乏教程、边缘设备部署困难等诸多障碍。
在这个新版本中,GluonCV解决了上述限制。GluonCV现在完全支持最先进的视频分类算法和主要数据集。在发布的同时,我们还提供了新的快速视频阅读器、分布式培训支持、广泛的教程和可复制的基准测试。使用GluonCV可以轻松地学习、开发和部署视频理解模型,而不必太担心工程细节。
More Pre-Trained Models and Datasets
最近,FAIR刚刚开放了他们的PySlowFast代码库用于视频理解。与PySlowFast相比,GluonCV提供了对更多模型和数据集的支持。例如,这个版本涵盖了最先进的算法:s TSN, C3D, I3D, P3D, R2+1D, Non-local and SlowFast, 并支持4个最广泛的数据集: UCF101, HMDB51, Kinetics400 和 Something-Something-V2.
这是一个在Kinetics400数据集上的预训练模型表:
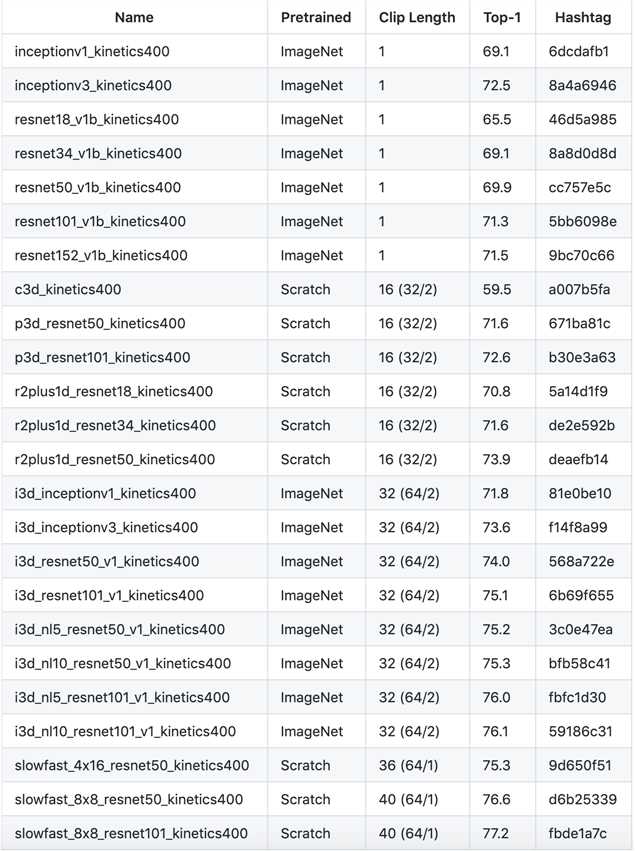
只需一行代码就可调用这些模型:net = get_model(model_name)
get_model:在GluonCV中定义好的方法。更多信息请参考:here。
Fast Video Reader: Decord
随着每个数据集中视频数量的增加,数据集的预处理和加载成为一个复杂而棘手的过程。以Kinetics400数据集为例,它是视频理解领域中广泛采用的一个基准,约有300K个视频。如果Kinetics400中的所有视频都被解码成帧,那么得到的帧总数将是ImageNet数据集中图像总数的100倍。Kinetics400数据集需要450GB的磁盘空间来存储所有视频,解码成帧时需要6.8TB的磁盘空间。如此庞大的数据量将使I/O成为训练过程中最紧张的瓶颈,导致GPU资源的浪费和实验周期的延长。
在这里,介绍一个新的视频阅读器,Decord。可以使用它直接从磁盘加载视频。用法很简单。从视频中读取帧类似于Numpy索引,使学习成本几乎为零。
import decord vr = decord.VideoReader(‘demo.mp4‘) # ‘demo.avi‘ frames = vr.get_batch([1,3,5,7]) print(frames.shape) # (4,240,320,3)
Decord至少比OpenCV VideoCapture和PyAV VideoContainer(记得pytorch依赖这个)快两倍。特别是在随机搜索的情况下,Decord的速度要快8倍。使用Decord将显著加快实验速度。

Easy-to-use customized API
GluonCV提供两个定制API:定制的dataloader和定制的model。可以方便搞起来。
首先介绍一个类VideoClsCustom,是一个定制的dataloader,对于大多数视频分类任务来说是很适合的。不论以任何格式存储在任何地方,你只需要准备一个如下的text文件来跑起来:

每行有三个元素:视频路径、视频长度、视频类别。如果你已经将视频解码为帧,那只需要将视频路径替换为帧文件夹的路径。看一个读取64帧视频片段的例子,每隔一帧读取224大小图像:
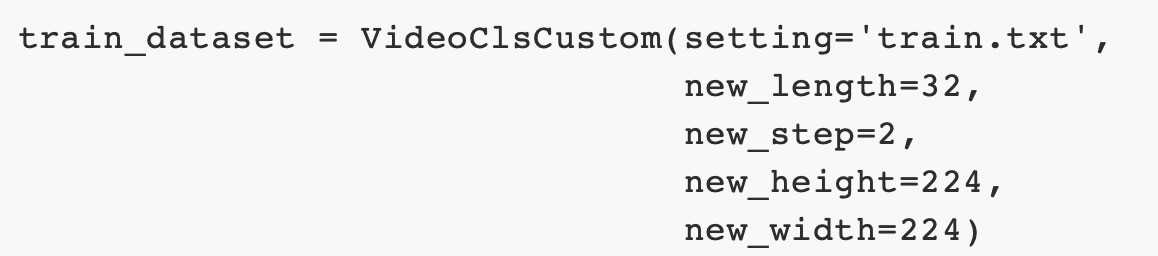
还可以调整许多其他参数,例如时间抖动、要使用哪个视频读取器等。VideoClsCustom可以通过调整这些参数来满足大多数数据集和模型的训练需要。实际上,Gluon的UCF101、HMDB51、Something和Kinetics400数据加载程序都是从这个类继承的,而不需要编写新代码。为所有人提供一个接口。
也提供了一些定制的模型来快速开始,例如slowfast_4x16_resnet50_custom。例如,如果要训练视频异常检测模型,这是一个二进制分类问题。可以简单地将模型构建为
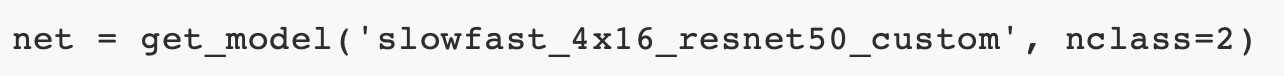
有了这两个强大的定制API,用户可以在几行代码中开始在自己的数据集上进行培训和测试。这里提供了一个教程,可以快速搞起来。
Extensive tutorials
在过去的五年里,视频理解发展迅速。然而,稳定的开源工具包,如MMAction、PyVideoResearch、VMZ和PySlowFast,最近才发布。大多数工具包假设用户已经具备视频理解的知识,并且只提供训练命令和一个模型库。新人必须先阅读一堆资料,然后才能理解和知道如何使用工具包。
GluonCV在Jupyter笔记本中提供了大量的教程,因为边做边学是最好的方法。用户可以直接在本地机器上学习,例如使用预先训练好的视频分类模型、如何训练最先进的模型、如何提取特征、如何在自己的数据集上进行微调等。GluOnTV支持Windows、Linux和Mac。
需要强调的是,对分布式培训有很好的支持。有一个易于遵循的分步指南,向用户展示如何设置集群、如何准备数据以及如何开始培训。分布式训练具有良好的可扩展性。没有花里胡哨的东西,可以用2台机器加速训练1.6倍,用4台机器加速训练3.2倍,用8台机器加速训练6倍。使用分布式培训可以显著缩短实验周期,这对学术研究和工业部署都至关重要。
Quantized Models for Fast Deployment
MXNET继续与英特尔紧密合作,在GluonCV中添加更多的INT8模型。在Intel Deep Learning Boost(VNNI)的支持下,GluonCV中的INT8量化模型可以比32位浮点模型实现显著的加速(5倍)。以下性能结果是在具有24个物理核心的AWS EC2 C5.12xlarge实例上进行基准测试的。需要最新的MXNet稳定版本才能正确使用这些新功能。
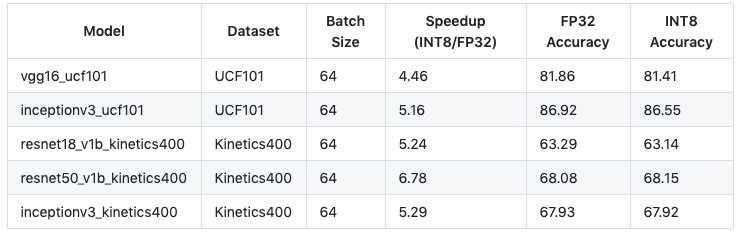
使用INT8量化模型与标准GluonCV模型相同,只需在模型名称中添加后缀_INT8,即可满足提速!
还提供了一个校准工具,供用户在自己的数据集上将模型量化到INT8。目前,校准工具只支持hybridized gluon模型。用户可以使用quantize_net API对自己的hybridized gluon模型进行量化。
以上是关于GluonCV 0.6: Embrace Video Understanding的主要内容,如果未能解决你的问题,请参考以下文章
Cherish life and embrace the life