泰坦尼克Titanic乘客生存预测
Posted langb
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了泰坦尼克Titanic乘客生存预测相关的知识,希望对你有一定的参考价值。
前言
目标:预测测试集中乘客是否会存活
此项目数据集分为2份数据集titanic_train.csv和titanic_test.csv
titanic_train.csv: 训练集,共计891条数据
titanic_test.csv: 测试集,共计418条数据
字段 字段说明
PassengerId 乘客编号
Survived 存活情况(存活:1 ; 死亡:0)
Pclass 客舱等级
Name 乘客姓名
Sex 性别
Age 年龄
SibSp 同乘的兄弟姐妹/配偶数
Parch 同乘的父母/小孩数
Ticket 船票编号
Fare 船票价格
Cabin 客舱号
Embarked 登船港口
探索性数据分析
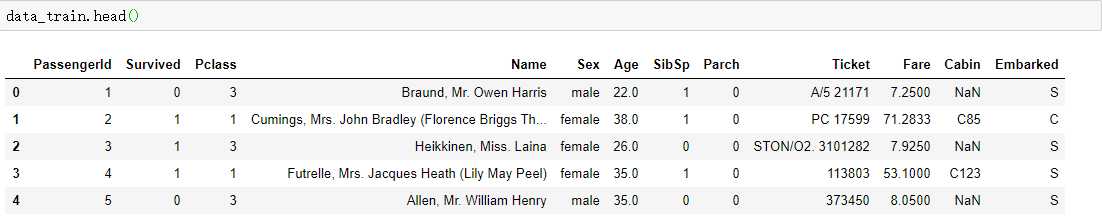
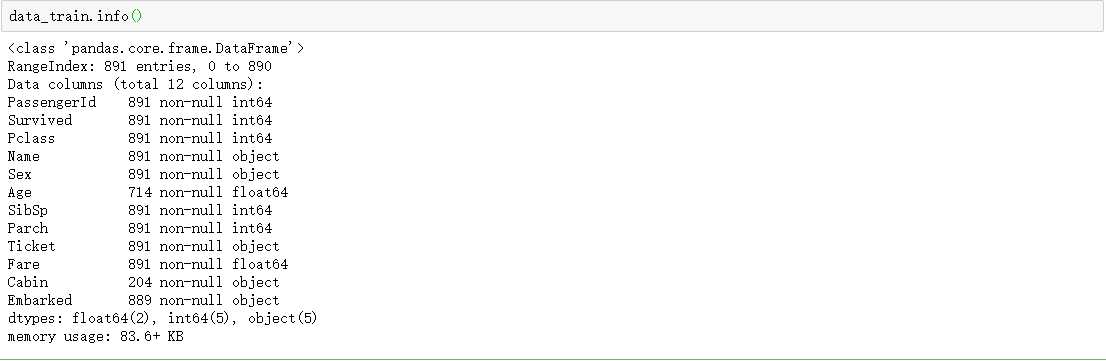
‘Cabin‘列大部分值都是缺失值,删除该列,乘客的名字也先不予考虑,将其删除。

‘Age‘缺失值用平均数填充,‘Embarked‘缺失值用众数填充。

补充后的数据为:
先看一下性别与获救率的关系,很显然女性得到了重点照顾。

下面做Heatmap(热图)对各变量进行相关性分析。
首先,对性别‘Sex‘列和登船港口‘Embarked‘列进行字符处理,船票编号类别大,难以分析规律,故先不参与相关性分析。

绘制Heatmap。

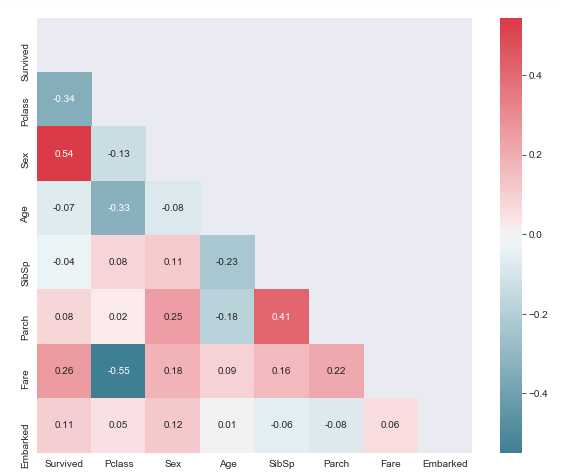
从图中可以得出:性别与是否获救相关性最强,女性更容易获救;其次是货舱等级以及票价与获救的高相关性,客舱越高级,船票越贵,越容易获救,可以说富人更容易获救。
其他信息为:一家人(父母子+配偶+兄弟姐妹)大概率一起坐船;越年长客舱越高级。
特征工程
删除特征:‘Name’ 和 ‘Cabin’(已完成)
合并特征:将‘SibSp’和‘Parch’合并 为新特征‘Mates‘

添加新特征:
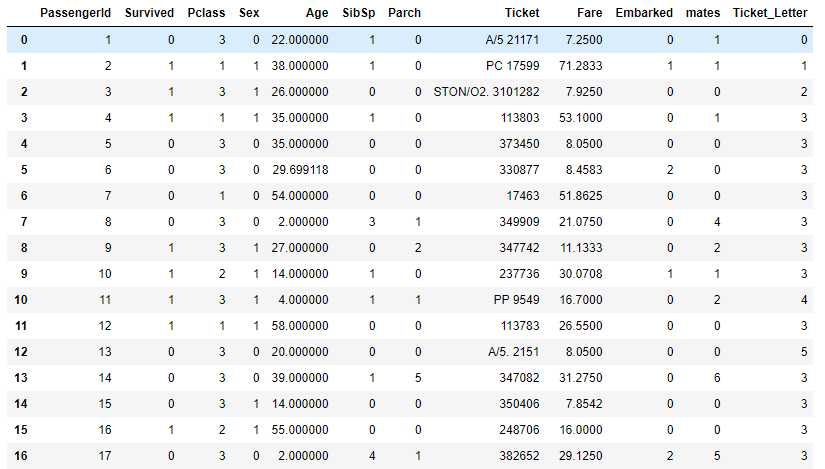
对船票编号’Ticket‘进行分析,将其分为字母开头型和数值型,其中字母开头型按字母进行细分,数字型统一算作一类,并对各类别数字编码。

效果如下:
模型选择
本文选用逻辑回归模型和随机森林模型。
逻辑回归模型:
特征工程前:


特征工程后:


随机森林模型:
特征工程前:


特征工程后:

以上是关于泰坦尼克Titanic乘客生存预测的主要内容,如果未能解决你的问题,请参考以下文章
机器学习第一步——用逻辑回归及随机森林实现泰坦尼克号的生存预测
大数据第一课(满分作业)——泰坦尼克号生存者预测(Titanic - Machine Learning from Disaster)