爬虫(工具:webmagic)
Posted winner963
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫(工具:webmagic)相关的知识,希望对你有一定的参考价值。
概述:
网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
一般来说,一个爬虫包括几个部分:
- 页面下载
页面下载是一个爬虫的基础。下载页面之后才能进行其他后续操作。
- 链接提取
一般爬虫都会有一些初始的种子URL,但是这些URL对于爬虫是远远不够的。爬虫在爬页面的时候,需要不断发现新的链接。
- URL管理
最基础的URL管理,就是对已经爬过的URL和没有爬的URL做区分,防止重复爬取。
- 内容分析和持久化
一般来说,我们最终需要的都不是原始的html页面。我们需要对爬到的页面进行分析,转化成结构化的数据,并存储下来。
不同的爬虫(通用类型的爬虫[何1] 、垂直类型的爬虫[何2] ),对这几部分的要求是不一样的。
实现
webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬虫开发的材料。
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。
webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/cookie等功能。
webmagic的主要特色:
- 完全模块化的设计,强大的可扩展性。
- 核心简单但是涵盖爬虫的全部流程,灵活而强大,也是学习爬虫入门的好材料。
- 提供丰富的抽取页面API。
- 无配置,但是可通过POJO+注解形式实现一个爬虫。
- 支持多线程。
- 支持分布式。
- 支持爬取js动态渲染的页面。
- 无框架依赖,可以灵活的嵌入到项目中去。
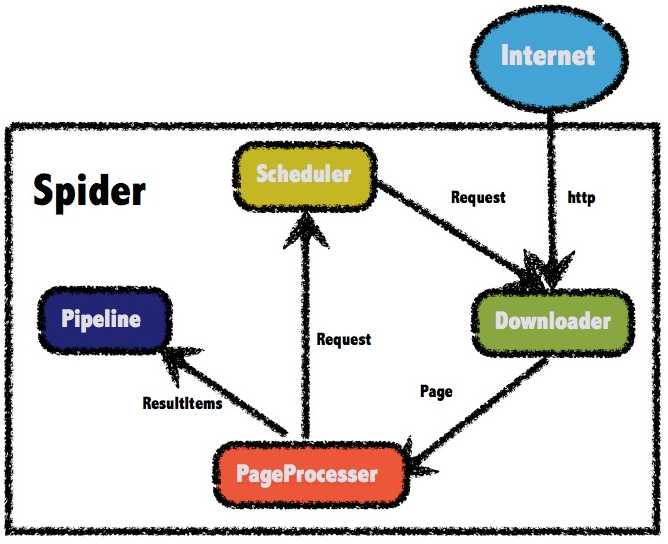
WebMagic总体架构
WebMagic的结构分为Downloader、PageProcessor、Scheduler、Pipeline四大组件,并由Spider将它们彼此组织起来。这四大组件对应爬虫生命周期中的下载、处理、管理和持久化等功能。WebMagic的设计参考了Scapy,但是实现方式更Java化一些。
#Spider(整个爬虫的调度框架):Spider将这几个组件组织起来,让它们可以互相交互,流程化地执行,可以认为Spider是一个大的容器,它也是WebMagic逻辑的核心。
#Downloader(页面下载):Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
#PageProcessor(链接提取和页面分析):PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
#Scheduler(URL管理):Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler
#Pipeline(离线分析和持久化):Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
[何1]对于通用型的爬虫,例如搜索引擎蜘蛛,需要指对互联网大部分网页无差别进行抓取。这时候难点就在于页面下载和链接管理上--如果要高效的抓取更多页面,就必须进行更快的下载;同时随着链接数量的增多,需要考虑如果对大规模的链接进行去重和调度,就成了一个很大的问题。一般这些问题都会在大公司有专门的团队去解决,比如这里有一篇来自淘宝的快速构建实时抓取集群。对Java来说,如果你要研究通用爬虫,那么可以看一下heritrix或者nutch。
[何2]垂直类型的爬虫要解决的问题则不一样,比如想要爬取一些网站的新闻、博客信息,一般抓取数量要求不是很大,难点则在于如何高效的定制一个爬虫,可以精确的抽取出网页的内容,并保存成结构化的数据。这方面需求很多,webmagic就是为了解决这个目的而开发的。
以上是关于爬虫(工具:webmagic)的主要内容,如果未能解决你的问题,请参考以下文章