使用 Google Colab上的PyTorch YOLOv3
Posted panchuangai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 Google Colab上的PyTorch YOLOv3相关的知识,希望对你有一定的参考价值。
作者|Hervind Philipe
编译|VK
来源|Towards Data Science

对于计算机视觉爱好者来说,YOLO (You Only Look Once)是一个非常流行的实时对象检测概念,因为它非常快,而且性能非常好。
在本文中,我将共享处理视频的代码,以获取谷歌Colab内每个对象的边框。
我们将不讨论YOLO的概念或架构,因为很多好的文章已经在媒体中详细阐述了这一点。这里我们只讨论函数代码。

开始
谷歌Colab地址:https://colab.research.google.com/github/vindruid/yolov3-in-colab/blob/master/yolov3_video.ipynb。
yolo的git仓库:https://github.com/ultralytics/yolov3。尽管仓库已经包含如何使用YOLOv3的教程,教程只需要运行python detect.py --source file.mp4,但是我准备简化代码。在谷歌Colab / Jupyter笔记本
准备YoloV3和LoadModel
首先克隆YoloV3仓库,然后导入通用包和repo函数
!git clone https://github.com/ultralytics/yolov3
import time
import glob
import torch
import os
import argparse
from sys import platform
%cd yolov3
from models import *
from utils.datasets import *
from utils.utils import *
from IPython.display import html
from base64 import b64encode
设置参数解析器,初始化设备(CPU / CUDA),初始化YOLO模型,然后加载权重。
parser = argparse.ArgumentParser()
parser.add_argument(‘--cfg‘, type=str, default=‘cfg/yolov3-spp.cfg‘, help=‘*.cfg path‘)
parser.add_argument(‘--names‘, type=str, default=‘data/coco.names‘, help=‘*.names path‘)
parser.add_argument(‘--weights‘, type=str, default=‘weights/yolov3-spp-ultralytics.pt‘, help=‘weights path‘)
parser.add_argument(‘--img-size‘, type=int, default=416, help=‘inference size (pixels)‘)
parser.add_argument(‘--conf-thres‘, type=float, default=0.3, help=‘object confidence threshold‘)
parser.add_argument(‘--iou-thres‘, type=float, default=0.6, help=‘IOU threshold for NMS‘)
parser.add_argument(‘--device‘, default=‘‘, help=‘device id (i.e. 0 or 0,1) or cpu‘)
parser.add_argument(‘--classes‘, nargs=‘+‘, type=int, help=‘filter by class‘)
parser.add_argument(‘--agnostic-nms‘, action=‘store_true‘, help=‘class-agnostic NMS‘)
opt = parser.parse_args(args = [])
weights = opt.weights
img_size = opt.img_size
# 初始化设备
device = torch_utils.select_device(opt.device)
# 初始化模型
model = Darknet(opt.cfg, img_size)
# 加载权重
attempt_download(weights)
if weights.endswith(‘.pt‘): # pytorch格式
model.load_state_dict(torch.load(weights, map_location=device)[‘model‘])
else: # darknet 格式
load_darknet_weights(model, weights)
model.to(device).eval();
# 获取名字和颜色
names = load_classes(opt.names)
colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(names))]
%cd ..
我们正在使用YOLOv3-sp-ultralytics权值,该报告称其在平均平均精度上远远优于其他YOLOv3
functiontorch_utils.select_device()将自动找到可用的GPU,除非输入是“cpu”
对象Darknet在PyTorch上初始化YOLOv3架构,并且需要使用预训练的权重来加载(此时我们不希望训练模型)
预测视频中的目标检测
接下来,我们将读取视频文件并使用框重写视频。
def predict_one_video(path_video):
cap = cv2.VideoCapture(path_video)
_, img0 = cap.read()
save_path = os.path.join(output_dir, os.path.split(path_video)[-1])
fps = cap.get(cv2.CAP_PROP_FPS)
w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*‘MP4V‘), fps, (w, h))
我们使用MP4格式写入新的视频,变量为vid_writer。而宽度和高度则根据原始视频设置。
开始对视频中的每一帧进行循环以获得预测。
while img0 is not None:
img = letterbox(img0, new_shape=opt.img_size)[0]
# 转换
img = img[:, :, ::-1].transpose(2, 0, 1) # BGR 到 RGB, 到 3xHxW
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.float() # uint8 到 fp16/32
img /= 255.0 # 0 - 255 到 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
pred = model(img)[0]
# 应用 NMS
pred = non_max_suppression(pred, opt.conf_thres, opt.iou_thres, classes=opt.classes, agnostic=opt.agnostic_nms)
这个模型的图像大小是416。一个函数名信箱正在调整图像的大小,并给图像填充,因此一个宽度或高度变成416,而另一个小于等于416,但仍然可以被32整除
第二部分是将图像转换为RGB格式,并将通道设置为第一维(C,H,W)。将图像数据放入设备(GPU或CPU)中,将像素从0-255缩放到0-1。在我们将图像放入模型之前,我们使用img.unsqeeze(0)函数,因为我们必须将图像重新格式化为4维(N,C,H,W), N是图像的数量,在本例中为1。
对图像进行预处理后,将其放入模型中得到预测框。但是预测有很多的框,所以我们需要非最大抑制来过滤和合并框。
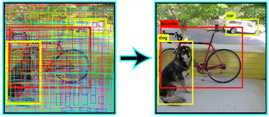
画边界框和标签,然后写入视频
我们在NMS之后循环所有的预测(pred)来绘制盒子,但是图像已经被调整为416像素,我们需要使用scale_coords函数将其缩放为原始大小,然后使用plot_one_box函数来绘制框
# 检测
for i, det in enumerate(pred): #检测每个图片
im0 = img0
if det is not None and len(det):
# 更改框的大小
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# 写入结果
for *xyxy, conf, cls in det:
label = ‘%s %.2f‘ % (names[int(cls)], conf)
plot_one_box(xyxy, im0, label=label, color=colors[int(cls)])
vid_writer.write(im0)
_, img0 = cap.read()
播放Colab的视频
视频在函数predict_one_video被写入为Mp4格式,我们压缩成h264所以视频可以在谷歌Colab / Jupyter直接播放。
显示原始视频
我们使用IPython.display.HTML来显示视频,其宽度为400像素。视频是用二进制读取的
path_video = os.path.join("input_video","opera_house.mp4")
save_path = predict_one_video(path_video)
# 显示视频
mp4 = open(path_video,‘rb‘).read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("""
<video width=400 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
压缩和显示处理过的视频
OpenCV视频写入器的输出是一个比原始视频大3倍的Mp4视频,它不能在谷歌Colab上显示使用相同的方法,解决方案之一是我们做压缩。
我们使用ffmpeg -i {save_path} -vcodec libx264 {compressed_path}
path_video = os.path.join("input_video","opera_house.mp4")
save_path = predict_one_video(path_video)
# 压缩视频
compressed_path = os.path.join("output_compressed", os.path.split(save_path)[-1])
os.system(f"ffmpeg -i {save_path} -vcodec libx264 {compressed_path}")
#显示视频
mp4 = open(compressed_path,‘rb‘).read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("""
<video width=400 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
结果

左边是原始视频,右边是使用代码处理的
试试你自己的视频
- 转到GitHub上的谷歌Colab文件(https://colab.research.google.com/github/vindruid/yolov3-in-colab/blob/master/yolov3_video.ipynb)
- 上传你的视频在
input_video文件夹,只需运行最后一个单元格(predict & show video)
原文链接:https://towardsdatascience.com/yolov3-pytorch-on-google-colab-c4a79eeecdea
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
以上是关于使用 Google Colab上的PyTorch YOLOv3的主要内容,如果未能解决你的问题,请参考以下文章
使用 Google Colab上的PyTorch YOLOv3
Google Colab 上的 PyTorch Geometric CUDA 安装问题
如何修复 Colab 上的“错误:pytorch3d 构建***失败”错误?
如何修复 google colab 上的 cuda 运行时错误?
神经网络学习小记录70——Pytorch 使用Google Colab进行深度学习
google Colab 使用教程 免费GPU google Colaboratory 上运行 pytorch tensorboard