数据结构-排序内部排序
Posted Mount256
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构-排序内部排序相关的知识,希望对你有一定的参考价值。
文章目录
- 对任意 n 个关键字排序的比较次数至少为
log2(n!)(向上取整)
1 直接插入排序
1.1 算法简要思想
每一趟排序中,数列的前面为有序序列,后面为无序序列。
每一趟排序中,均选取无序序列中的第一个元素,插到有序序列的正确位置。
1.2 算法特性
- 【时间复杂度】最好:O(n);最坏:O(n2);平均:O(n2)
- 【空间复杂度】O(1)
- 【稳定性】稳定
- 【适用性】顺序存储、链式存储
- 【性质】每趟排序后,最左端或最右端总是有序的
2 希尔排序
2.1 算法简要思想
设置一个步长 d,将无序序列分为 d 个表,对各个子表进行直接插入排序,然后再取第二个步长重复上述过程。
2.2 手动模拟
原始序列:4,2,3,1,16,10,9,14,8,7

2.3 算法特性
- 【时间复杂度】最坏:O(n2)
- 【空间复杂度】O(1)
- 【稳定性】不稳定
- 【适用性】顺序存储
3 冒泡排序
3.1 算法简要思想
每一趟排序(冒泡)中,从后往前(或从前往后)两两比较相邻元素的值,若为逆序则交换。
每一趟的结果是将最小的元素交换到序列的第一个位置(或将最大的元素交换到序列的最后一个位置)。
3.2 算法特性
- 【时间复杂度】最好:O(n);最坏:O(n2);平均:O(n2)
- 【空间复杂度】O(1)
- 【稳定性】稳定
- 【适用性】顺序存储
- 【性质 1】每趟排序后,总有一个元素放置在最终位置上
- 【性质 2】每趟排序后,最左端或最右端总是有序的
4 快速排序
4.1 算法思路
- 选取区间 A 最左边的元素 x 作为基准值;
- 从区间 A 的最右边开始,往左找,碰到第一个比 x 小的元素时停下,把下标记为 j;(基准数在最左边,必须从最右边开始扫描!)
- 从区间 A 的最左边开始,往右找,碰到第一个比 x 大的元素时停下,把下标记为 i;
- 交换 A[i] 和 A[j];
- 继续从 j 往左找,再从 i 往右找,重复上述过程,直到 i 和 j 碰面为止,将 A[i] 与第一个元素 x 交换;
- 将区间 A 分为两段:
[最左边, i-1],[i+1, 最右边](或[最左边, j-1],[j+1, 最右边]),重复上述过程。
4.2 算法代码
void QSort (int A[], int low, int high)
if (low >= high)
return;
int i = low, j = high; // 左右指针分别指向区间两端
int pivot; // 基准值
将 A 数组中随机一个元素和 A[low] 交换; // 随机选取基准值
pivot = A[low]; // 最左边作为基准值
while (i != j)
while ((i < j) && (A[j] > pivot)) // 右指针从区间右端往左端移动
j--;
while ((i < j) && (A[i] <= pivot)) // 左指针从区间左端往右端移动(注意还有等于条件)
i++;
if (i < j)
swap(A[i], A[j]); // 交换 A[i] 和 A[j]
swap(A[low], A[i]); // 将基准值放入最终位置
QSort(A, low, i-1); // 递归处理左区间
QSort(A, i+1, high); // 递归处理右区间
4.3 手动模拟
原始序列:49,38,65,97,13,76,27,49,52,5
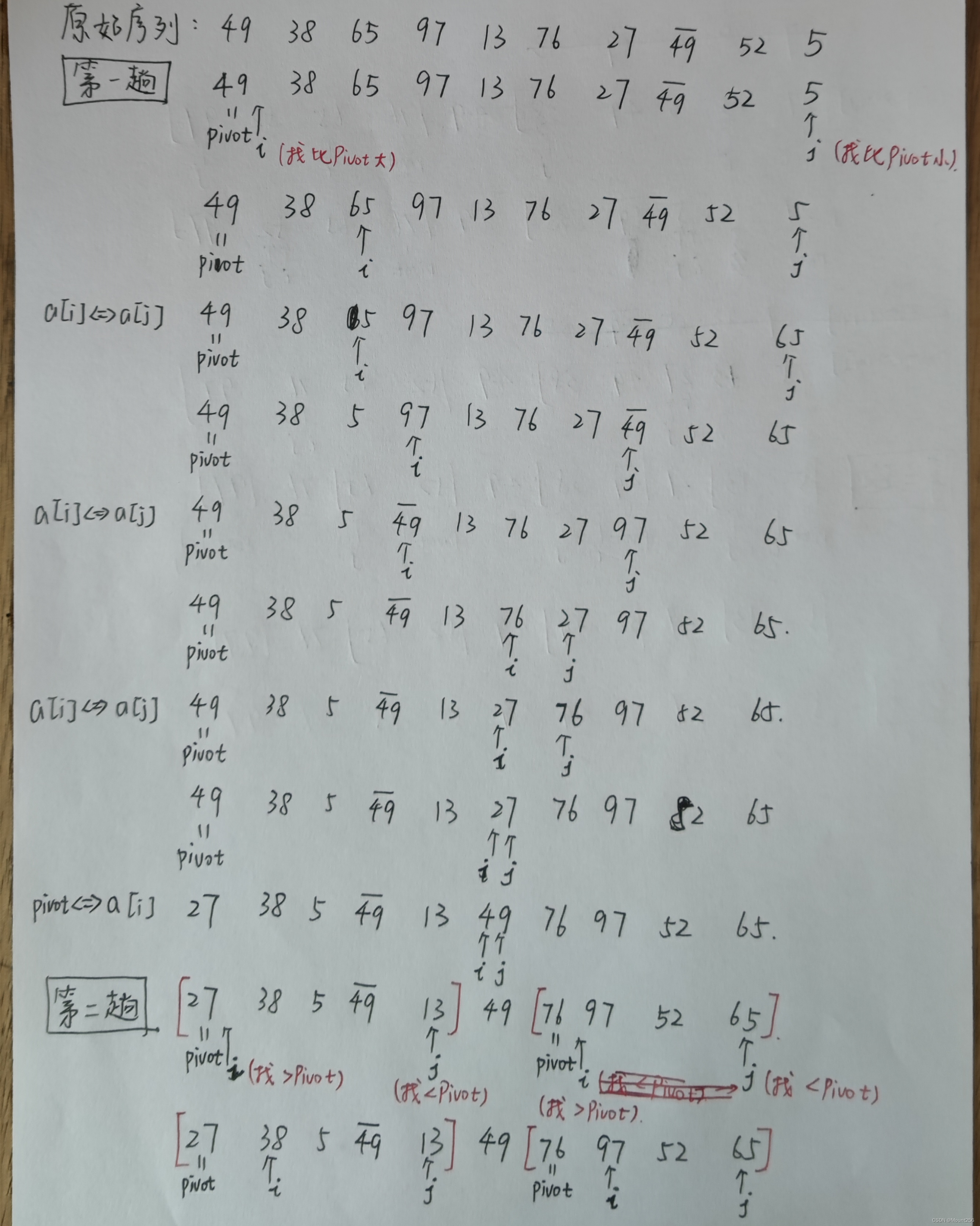

4.4 算法特性
- 【时间复杂度】最好:O(nlog2n);最坏:O(n2);平均:O(nlog2n)
- 【空间复杂度】最好:O(log2n);最坏:O(n);平均:O(log2n)
- 【稳定性】不稳定
- 【适用性】顺序存储
- 【一趟的定义】排序过程中,对尚未确定最终位置的所有元素进行一遍处理
- 【性质 1】每趟排序后,总有一个元素放置在最终位置上
- 【性质 2】第 i 趟排序完成后,会有 i 个以上的数出现在它最终将要出现的位置
- 【性质 3】当每次的枢轴把表等分为长度相近的两个子表时,速度是最快的
- 【性质 4】当表本身已经有序或逆序时,速度最慢
4.5 相关例题
【例 1】下列选项中,不可能是快速排序第 2 趟排序结果的是( )
A. 2,3,5,4,6,7,9
B. 2,7,5,6,4,3,9
C. 3,2,5,4,7,6,9
D. 4,2,3,5,7,6,9
【解法一】第 i 趟排序完成后,会有 i 个或以上的数出现在它最终将要出现的位置,即它左边的数比它小,右边的数比它大。
由于题目问的是第 2 趟排序结果,因此分析每个选项能否找到两个或以上这样的数(符合的数被加粗),即它左边的数比它小,右边的数比它大。
- A 项:2,3,5,4,6,7,9
- B 项:2,7,5,6,4,3,9
- C 项:3,2,5,4,7,6,9 (只找到一个)
- D 项:4,2,3,5,7,6,9
所以选 C。
【解法二】由于第 i 趟排序完成后,会有 i 个或以上的数出现在它最终将要出现的位置,所以只需将最终的排序结果写出来,再跟每个选项进行对比,符合条件的结果应该有两个以上的元素相同(加粗)。
- 最终:2,3,4,5,6,7,9
- A 项:2,3,5,4,6,7,9 (有 5 个相同)
- B 项:2,7,5,6,4,3,9 (有 2 个相同)
- C 项:3,2,5,4,7,6,9 (只有 1 个相同)
- D 项:4,2,3,5,7,6,9 (有 2 个相同)
所以选 C。
【例 2】排序过程中,对尚未确定最终位置的所有元素进行一遍处理称为一“趟”。下列序列中,不可能是快速排序第二趟结果的是( )
A. 5, 2, 16, 12, 28, 60, 32, 72
B. 2, 16, 5, 28, 12, 60, 32, 72
C. 2, 12, 16, 5, 28, 32, 72, 60
D. 5, 2, 12, 28, 16, 32, 72, 60
【解】由于第 i 趟排序完成后,会有 i 个或以上的数出现在它最终将要出现的位置,所以只需将最终的排序结果写出来,再跟每个选项进行对比,符合条件的结果应该有两个以上的元素相同(加粗)。
- 最终:2, 5, 12, 16, 28, 32, 60, 72
- A 项:5, 2, 16, 12, 28, 60, 32, 72
- B 项:2, 16, 5, 28, 12, 60, 32, 72
- C 项:2, 12, 16, 5, 28, 32, 72, 60
- D 项:5, 2, 12, 28, 16, 32, 72, 60
第一趟排序,确定一个元素位置,第二趟排序,又可以确定一个或两个元素位置。
- 当第一趟元素确认的位置为最左或最右时,第二趟排序只能确认一个位置(A,B 项)
- 当第一趟元素确认位置不是最左或最右时,第二趟能确认 2 个位置(C 项)
所以选 D。
【注】按以上思路分析例 1 的选项,发现均符合上述规律。
5 简单选择排序
5.1 算法简要思想
每一趟排序中,数列的前面为有序序列,后面为无序序列。
每一趟排序中,均在无序序列中选取关键字最小的元素,插到有序序列的最后一个位置。
5.2 算法特性
- 【时间复杂度】最好:O(n2);最坏:O(n2);平均:O(n2)
- 【空间复杂度】O(1)
- 【稳定性】不稳定
- 【适用性】顺序存储、链式存储
- 【性质】每趟排序后,最左端或最右端总是有序的
6 堆排序
6.1 建立大根堆(手动模拟)
原始序列:4,2,3,1,16,10,9,14,8,7
从第 n/2(向下取整)个结点开始,依次向前对第 n/2(向下取整)个至第 1 个结点的子堆。
注意,每次交换后,都要对下一层的子堆进行递归调整,因为交换后有可能破坏已调整子堆的结构。
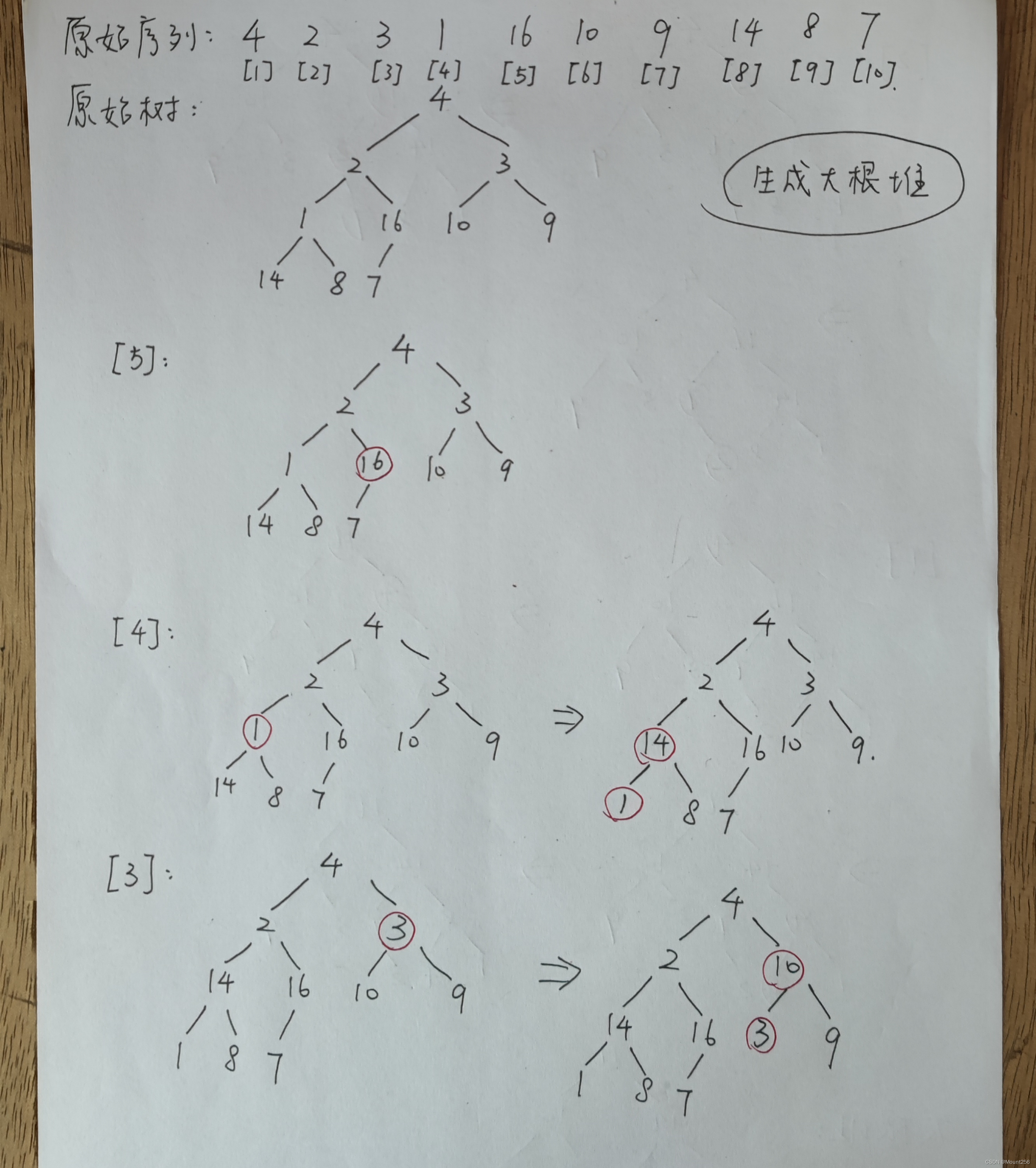
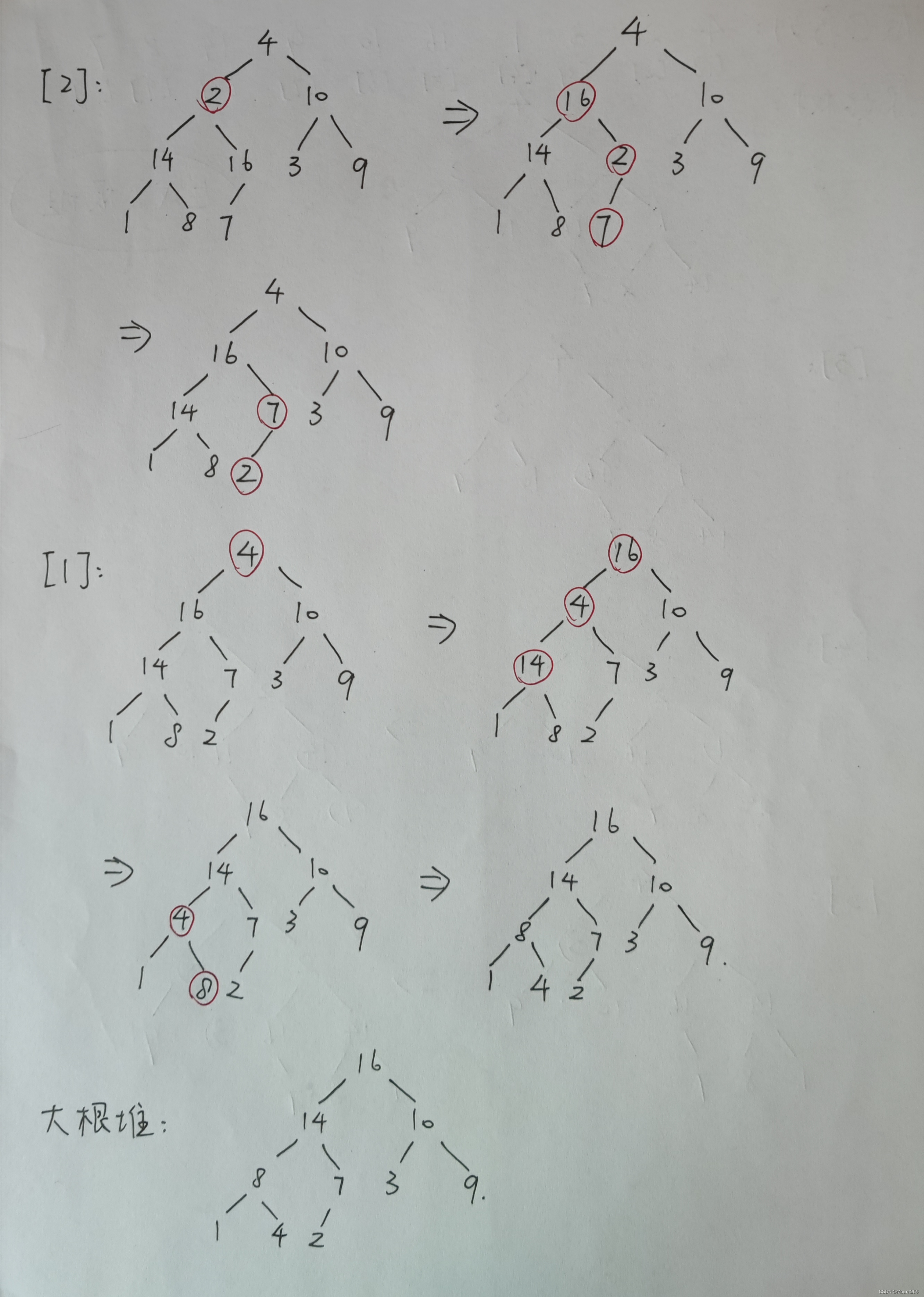
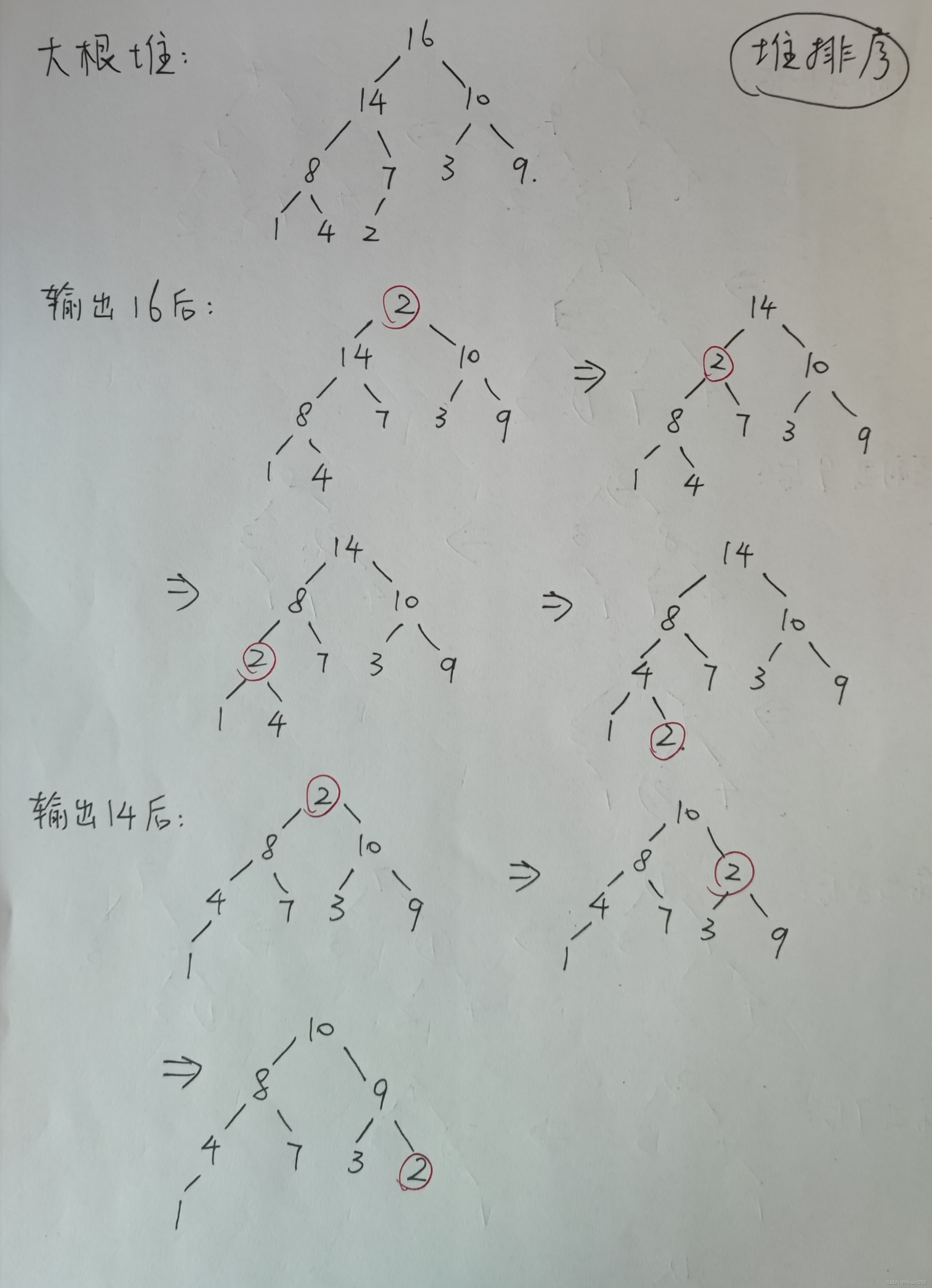
6.2 堆排序(手动模拟)
每次输出堆顶元素后,将堆的最后一个元素与堆顶元素交换,此时堆的性质被破坏,需要向下进行调整堆。
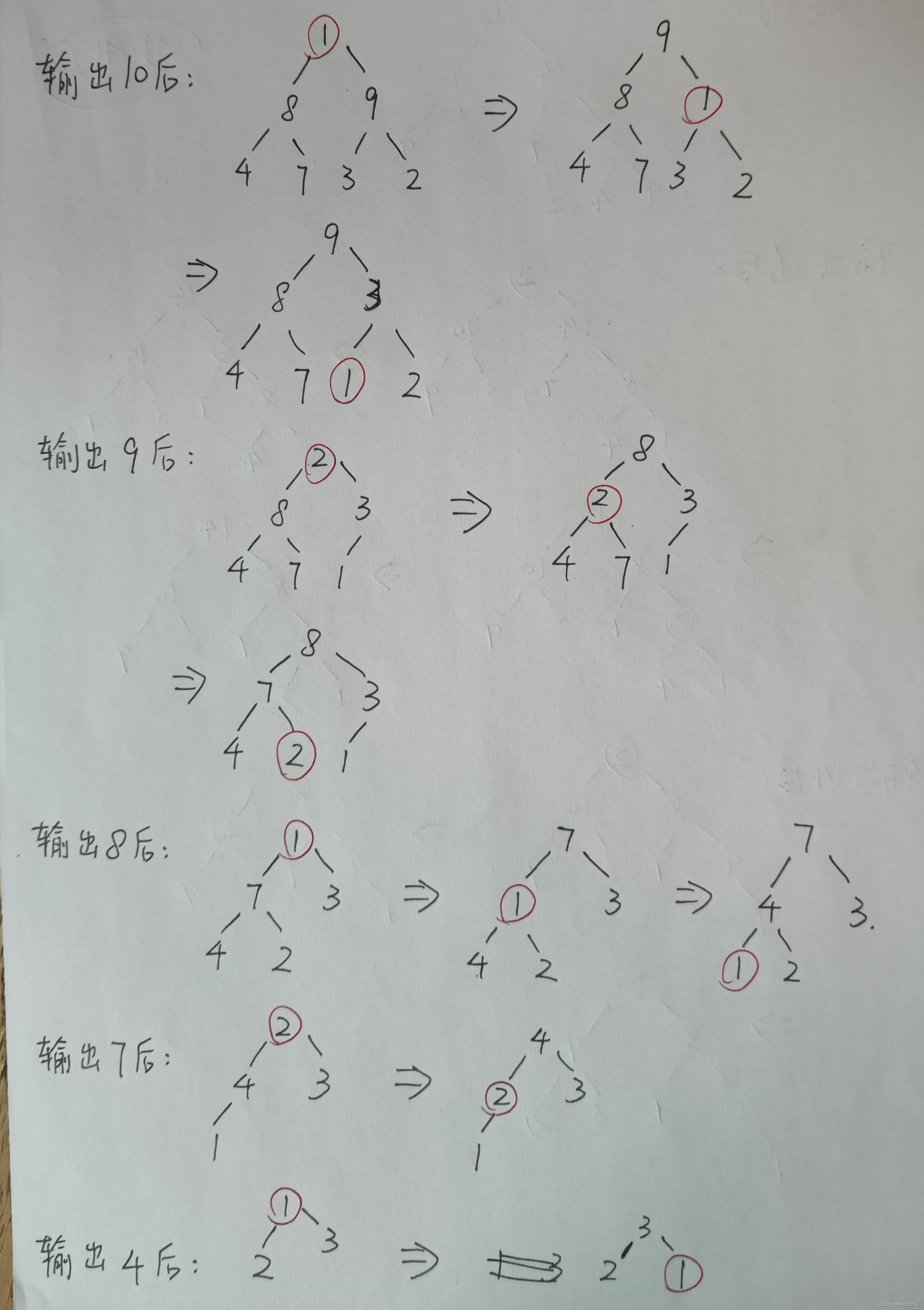
6.3 算法特性
- 【时间复杂度】最好、最坏、平均:O(nlog2n)
- 【空间复杂度】O(1)
- 【稳定性】不稳定
7 基数排序
7.1 手动模拟
排序顺序:个位、十位、百位。
放入桶中时一定要注意先后顺序,要用链表串起来!
取出桶时也一定要注意先后顺序!遵守先进先出原则!
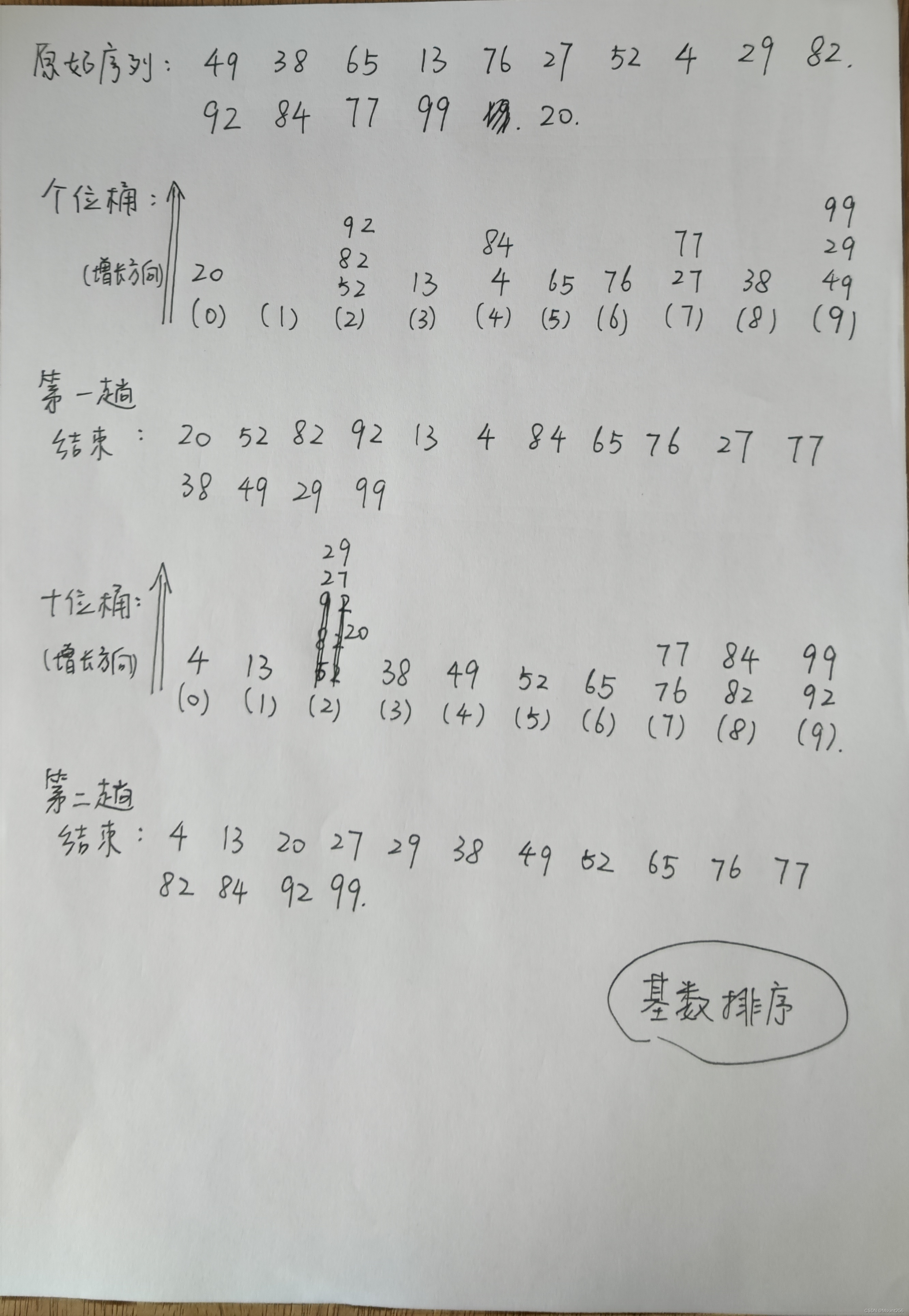
7.2 算法特性
- 【时间复杂度】最好、最坏、平均:O(d(n+r))
- 【空间复杂度】O(r)
- 【稳定性】稳定
以上是关于数据结构-排序内部排序的主要内容,如果未能解决你的问题,请参考以下文章