Elasticsearch系列---相关性评分算法及正排索引
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch系列---相关性评分算法及正排索引相关的知识,希望对你有一定的参考价值。
概要
上一篇中多次提到了按相关性评分,本篇我们就来简单了解一下相关性评分的算法,以及正排索引排序的优势。
评分算法
Elasticsearch进行全文搜索时,Boolean Model是匹配的基础,先用boolean model将匹配的文档挑选出来,然后再运用评分函数计算相关度,参与的函数如我们提到的TF/IDF、Length Norm等,再加上一些控制权重的参数设置,得到最后的评分。
Boolean Model
作为全文搜索的基础,Boolean Model的结果决定文档是否要进行下一步的评分操作,使用AND、OR、NOT这种逻辑操作符来判断查找的文档,整个过程不评分,非常快速地将匹配的文档筛选出来。
由于Elastisearch各个版本相关度评分算法有异同,我们以6.3.1版本的BM25算法为准。
TFNORM/IDF
由Boolean Model之后得到的文档,我们开始计算文档的评分,每个文档的评分取决于每个关键词在文档中的权重,权重我们会从以下几个方面考虑:
TFNORM
即词频长度(Term Frequency Norm),单个term在文档中出现的频率,并结合字段长度,出现次数越高,字段长度越低,分越高,计算公式:
tfNorm(t in d) = (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength))
词t在文档d的词频(tf):freq表示出现频率,k1、b为ES参数,fieldLength为该字段长度,avgFieldLength为平均字段长度,公式了解一下即可。
IDF
即逆向文档频率(inversed document frequency),单个term在所有文档里出现的频率是多少?出现次数越高,分越低,计算公式:
idf(t) = log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5))
词 t 的逆向文档频率(idf):索引中文档数量与该词的文档数比率,然后求其对数
例如:"and"、"the","的"、"了"、"呢"这种词在文档里到处都是,出现的频率特别高,反倒是不常出现的词"Elastic","成都"可以帮助我们快速缩小范围找到感兴趣的文档。
结果合并
一个term经过上面两个算法计算后,会得到两个不同的值,这两个得分相乘得到一个综合性的分数,这个分数就是最终的_score
我们用explain来看一下这个综合分数的详细信息:
搜索请求:
GET /music/children/_search
{
"explain": true,
"query": {
"term": {
"name": "teeth"
}
}
}响应结果:
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.73617005,
"hits": [
{
"_explanation": {
"value": 0.7361701,
"description": "weight(name:teeth in 1) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.7361701,
"description": "score(doc=1,freq=1.0 = termFreq=1.0
), product of:",
"details": [
{
"value": 0.6931472,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 1,
"description": "docFreq",
"details": []
},
{
"value": 2,
"description": "docCount",
"details": []
}
]
},
{
"value": 1.0620689,
"description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:",
"details": [
{
"value": 1,
"description": "termFreq=1.0",
"details": []
},
{
"value": 1.2,
"description": "parameter k1",
"details": []
},
{
"value": 0.75,
"description": "parameter b",
"details": []
},
{
"value": 3.5,
"description": "avgFieldLength",
"details": []
},
{
"value": 3,
"description": "fieldLength",
"details": []
}
]
}
]
}
]
}
}
]
}
}_explanation节点,里面包含了description、value、details字段,从这里我们可以知道计算的类型,计算结果和任何我们需求的计算细节。从示例中我们可以看到IDF和TF的计算公式和计算结果。
我们可以看到最终得分是0.73617005,其中tfNorm得分1.0620689,idf得分0.6931472,经过相乘1.0620689 * 0.6931472 = 0.73617005
多个term查询
上面的案例是只有一个term查询的,如果有多个term查询,如:
GET /music/children/_search
{
"explain": true,
"query": {
"match": {
"name": "your teeth"
}
}
}我们可以看到,总的_score就是将每个term查询的_score求和。
Lucene公式
这里我们先看query score的计算公式:
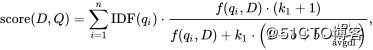
我们从左往右看,公式依次的含义如下:
- score(D,Q):这个公式最终的结果,Q表示query,D表示doc,表示一个query对一个doc的最终的总得分。
- IDF(qi):idf算法对一个term的值。
- f(xxx)/xxx:这一大串公式,即tf norm的计算公式。
- ∑ 求和符号:idf和tf norm结果相乘,最后求和。
这个求相关性分数的公式了解一下即可,可以结合上面的案例去理解这个公式。
这个公式可以参见wiki: [Okapi BM25]https://en.wikipedia.org/wiki/Okapi_BM25
文档是如何被匹配到的
如果对搜索的结果有异议,我们可以指定文档ID进行查看,该文档为什么能被匹配上,也是使用explain参数,示例如下:
GET /music/children/4/_explain
{
"query": {
"match": {
"content": "wake up morning"
}
}
}4为文档ID,此请求的含义表示针对如下的搜索条件,文档ID为4的记录是为何能匹配上的,响应的结果也是非常长,节选一部分:
{
"_index": "music",
"_type": "children",
"_id": "4",
"matched": true,
"explanation": {
"value": 0.9549814,
"description": "sum of:",
"details": [
{
"value": 0.62577873,
"description": "weight(content:wake in 0) [PerFieldSimilarity], result of:",
"details": [
{
"value": 0.62577873,
"description": "score(doc=0,freq=1.0 = termFreq=1.0
), product of:",
"details": [
{
"value": 0.6931472,
"description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:",
"details": [
{
"value": 1,
"description": "docFreq",
"details": []
},
{
"value": 2,
"description": "docCount",
"details": []
}
]
},注意关键属性matched,如果是true,则explanation会有非常详细的信息,每个分词后的关键词,相关性得分是多少,都会详细列举出来,很多匹配过程的细节,都能在上面找到证据。如果是false,响应报文则是这样:
{
"_index": "music",
"_type": "children",
"_id": "1",
"matched": false,
"explanation": {
"value": 0,
"description": "No matching clauses",
"details": []
}
}这是一个非常实用的工具,研发过程中出现让人困惑的搜索结果,都可以用它进行分析。
正排索引
ES在索引文档时,会建立倒排索引,倒排索引的检索性能非常高,但对排序来说,却不是理想的结构。
因此ES索引文档时,还会建立正排索引,即Doc Values,这是一种列式存储结构,默认情况下每个字段都会存储到Doc Values里。
所以整个搜索排序过程中,正排搜索和倒排搜索是这样配合的:
- 倒排索引负责关键词的检索,快速得到匹配的结果集。
- 正排索引完成排序、过滤、聚合的功能,得到期望的文档顺序。
应用场景
Elasticsearch中的Doc Values常被应用到以下场景:
- 对某个字段排序
- 对某个字段聚合
- 对某个字段过滤
- 某些与字段相关的计算、脚本执行等
性能
Doc Values是被保存到磁盘上的,如果os cache内存足够,整个working set将自动缓存到内存中,性能非常高,如果内存不充裕,Doc Values会将其写入到磁盘上。
整体来说,性能还是可以的,合理的os cache设置,可以极大地提高查询的性能。
小结
本篇主要介绍了相关性评分算法的基础知识,能够使用工具查看评分的详细过程,可以辅助解释一些困惑的现象,最后简单介绍了一下正排索引的应用场景。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区
可以扫左边二维码添加好友,邀请你加入Java架构社区微信群共同探讨技术
以上是关于Elasticsearch系列---相关性评分算法及正排索引的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch系列---相关性评分算法及正排索引
Elasticsearch实用BM25 -第1部分: shard 如何影响Elasticsearch中的相关性评分