Proxmox VE 超融合集群不停服务更换硬盘操作实录
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Proxmox VE 超融合集群不停服务更换硬盘操作实录相关的知识,希望对你有一定的参考价值。
情况描述
四节点组成的proxmox VE超融合集群,连续运行时间超过500天。每个节点除了系统盘而外,由四个单独的2.4T 10000转sas盘做ceph osd。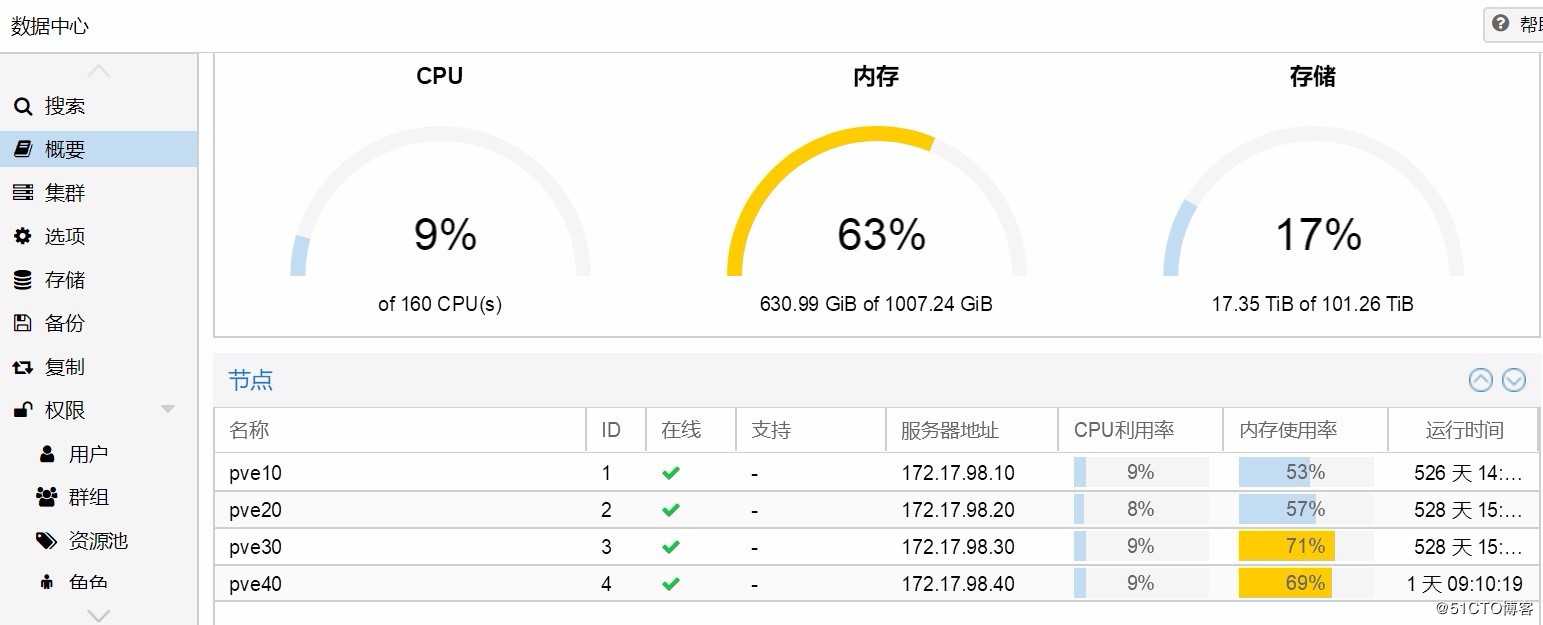
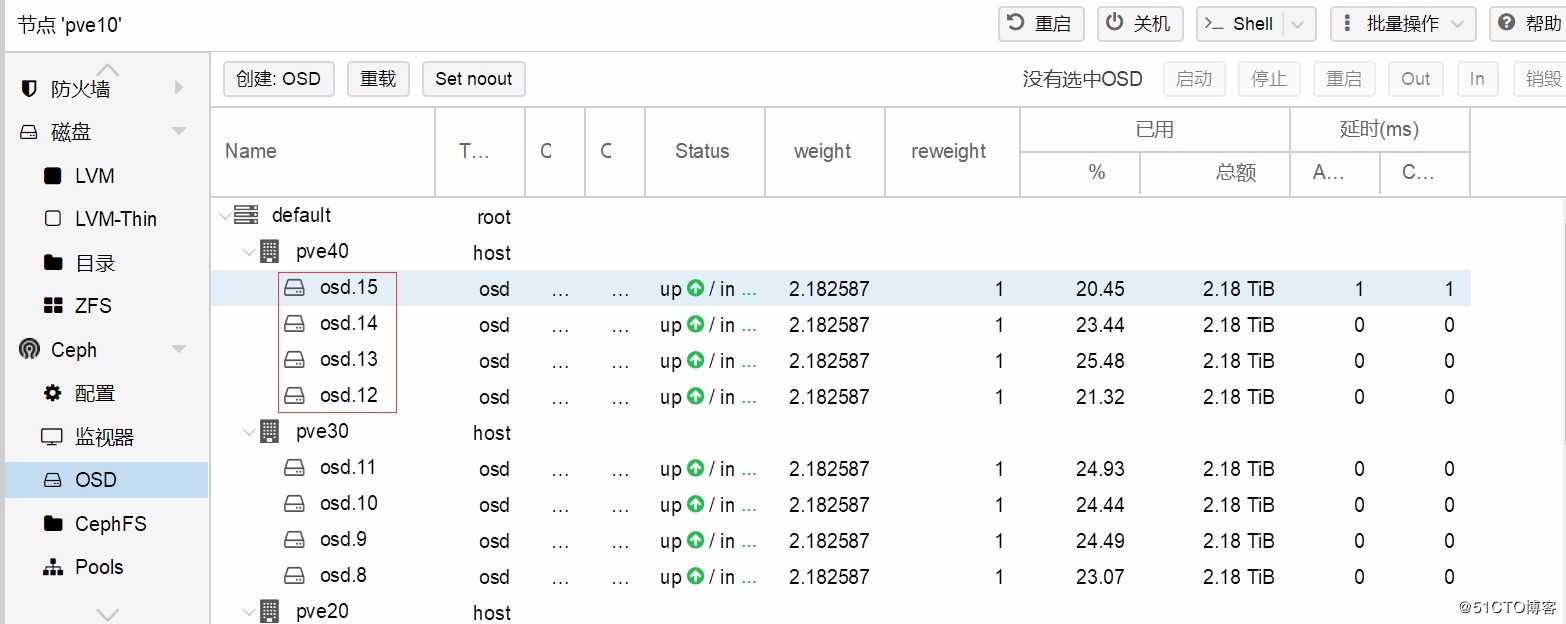
监控发现,其中一个节点的一块硬盘处于down的状态,尝试修复未获得成功,登录系统,发现系统日志有大量的IO错误,由此判断,一定是硬盘物理损坏。再通知机房,请值班技术帮忙,现场查看硬盘指示灯状态,有一块硬盘常亮红灯,确认故障与判断一致。
故障修复计划
由于是在线系统,服务不允许停止,这是最基本的要求。非常幸运的是,proxmox VE去中心化超融合集群,在保证集群得以维持的情况下,可以关掉任意一台或者多台物理服务器(别的超融合平台有控制节点,这个控制节点不能关)。
没有停机担忧以后,做出如下安排:
- ? 把有故障的物理机上正在运行的虚拟机,加入到ha中;
- ? 停机换硬盘;
- ? 系统识别硬盘;
- ? 创建osd;
- ? 回迁部分虚拟机到恢复好的物理节点。
故障修复实施
一切准备妥当之后,风高月黑之夜派人潜入机房,待命。按照计划,进行如下的步骤:
-
Web管理界面,把故障机运行着的虚拟机的ID号记录下来,然后将其加入到proxmox VE的HA(此高可用与pve集群不同,是建立在pve集群之上的)。
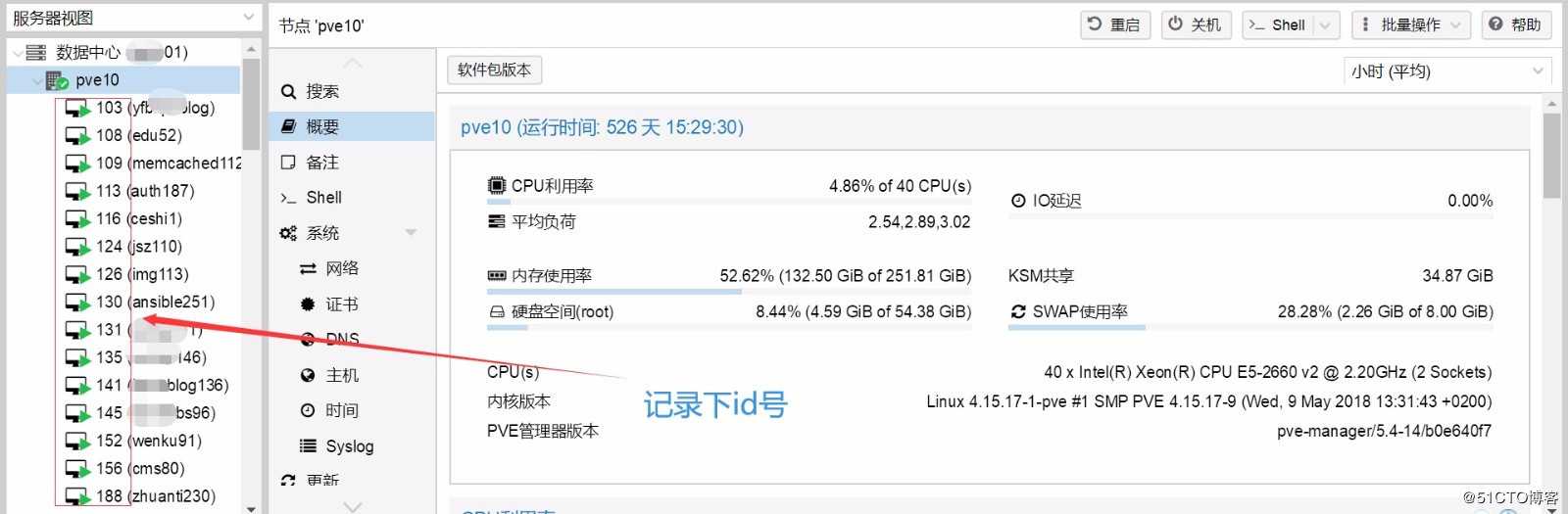
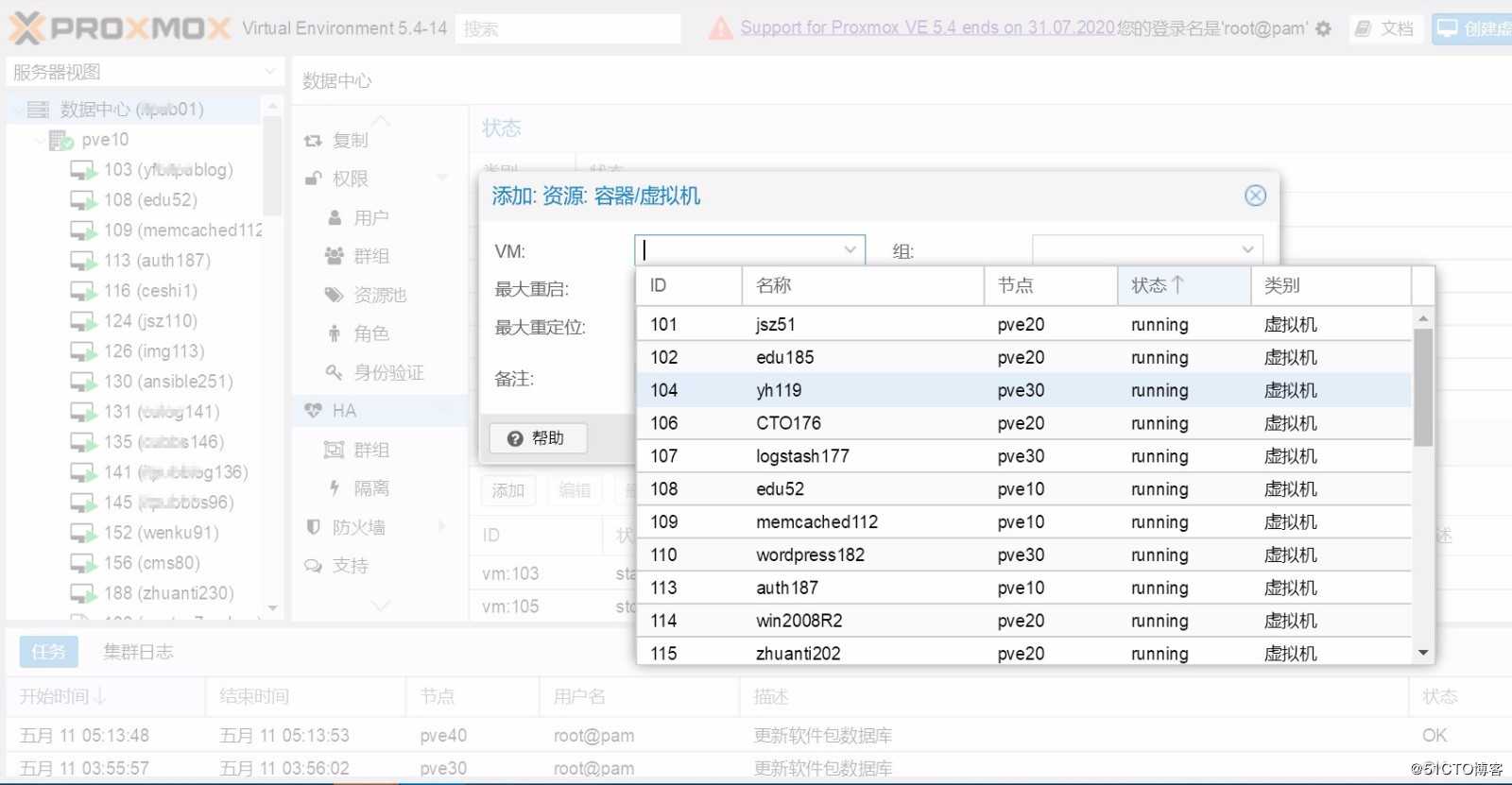
- 关机,查看故障机运行的虚拟机是否全部自动漂移(对照记录下来的虚拟机id号)。
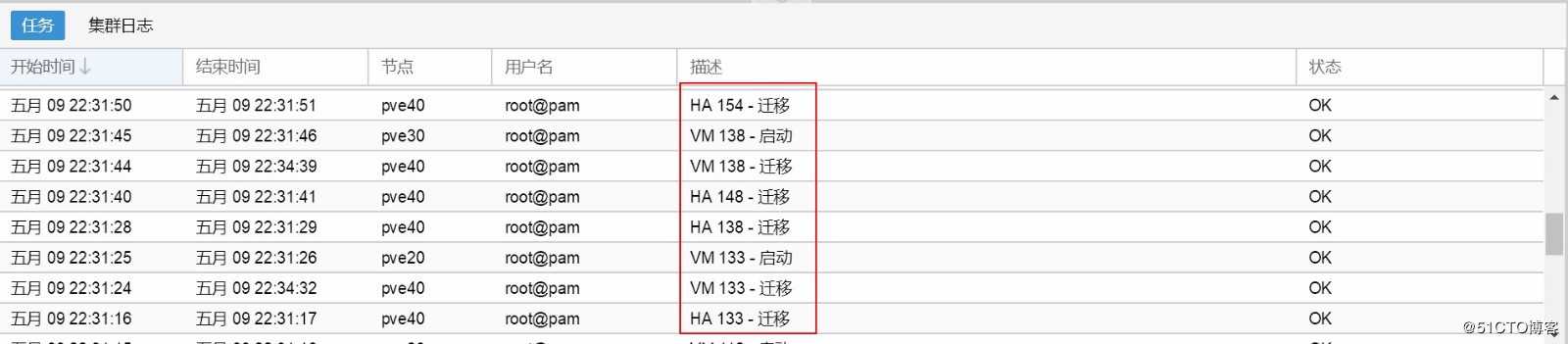
- 通知机房待命的兄弟,拔出坏硬盘,身手敏捷地插上新硬盘。启动系统,看系统是否识别硬盘,不幸的是,没有被识别(其实也是意料之中),需要进入raid卡的控制控制界面,把这个新盘做成raid 0(单盘raid0 ,强烈建议不要搞raid 5),再启动,能识别到这个硬盘,具体的指令就是df -h。
-
执行下列命令初始化新更换的磁盘:
wipefs -af /dev/sdcwipefs -af /dev/sdc #sdc为新更换的磁盘设备名称
- Web管理界面创建osd。如果下拉列表提示“没有未使用的磁盘”,可以重复第“4”步。
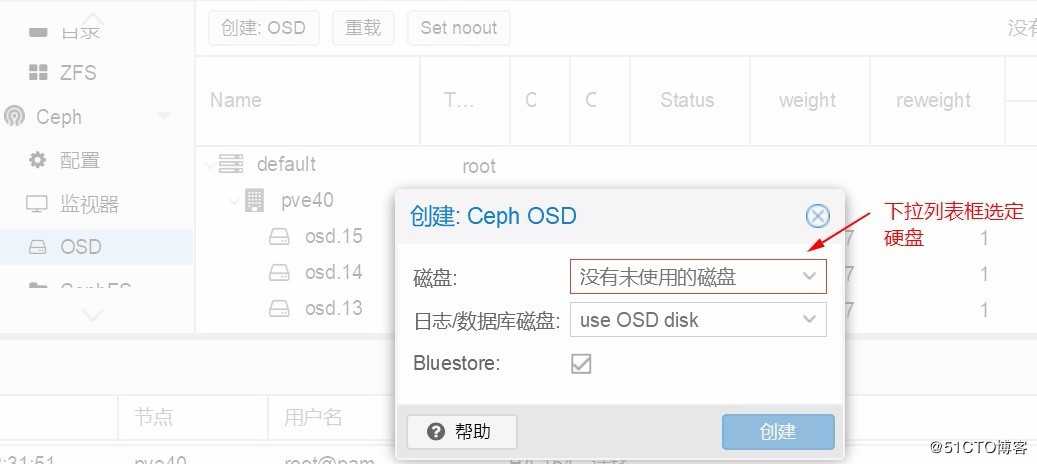
- 刷新页面,查看新的osd是否已经被正确加入。同时也可以在命令执行如下指令进行同步验证:
ceph osd treeceph osd tree
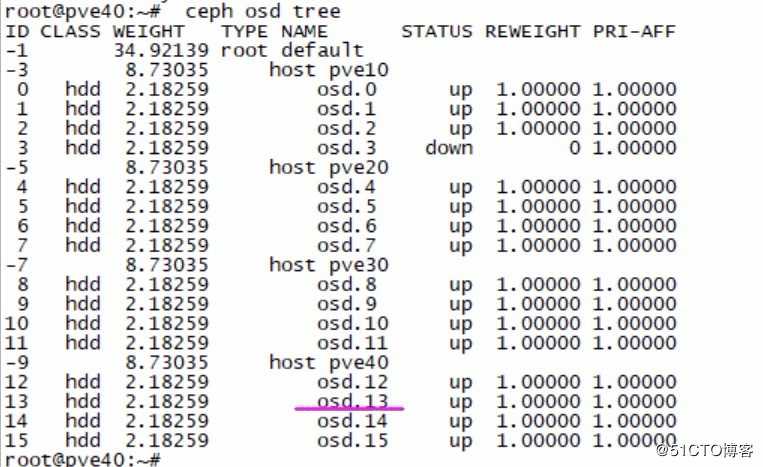
- 回迁部分虚拟机到恢复好物理节点。点鼠标就行,不再赘述。
以上是关于Proxmox VE 超融合集群不停服务更换硬盘操作实录的主要内容,如果未能解决你的问题,请参考以下文章