Kintinuous 相关论文 Volume Fusion 详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kintinuous 相关论文 Volume Fusion 详解相关的知识,希望对你有一定的参考价值。
近几个月研读了不少RGBD-SLAM的相关论文,Whelan的Volume Fusion系列文章的效果确实不错,而且开源代码Kintinuous结构清晰,易于编译和运行,故把一些学习时自己的理解和经验写出来,供大家参考,同时希望各位批评指正。
研读之前已经发现有中文博客做了一些解析,我也受益不少。参见fuxingyin的blog:Kintinuous 解析 。不过有些地方已经不够详细,故此文重新进行解读。可能某些地方会重复。
本文是在自己阅读、整理、代码实践的基础上做的一些结果,希望对相关研究者有所帮助。
Kintinuous涉及的文章,其中包括4篇论文,1篇专利(如下链接来自其开源代码中找到:github repo - Kintinuous):
- Real-time Large Scale Dense RGB-D SLAM with Volumetric Fusion, T. Whelan, M. Kaess, H. Johannsson, M.F. Fallon, J. J. Leonard and J.B. McDonald, IJRR ‘14
- Deformation-based Loop Closure for Large Scale Dense RGB-D SLAM, T. Whelan, M. Kaess, J.J. Leonard, and J.B. McDonald, IROS ‘13
- Robust Real-Time Visual Odometry for Dense RGB-D Mapping, T. Whelan, H. Johannsson, M. Kaess, J.J. Leonard, and J.B. McDonald, ICRA ‘13
- Kintinuous: Spatially Extended KinectFusion, T. Whelan, M. Kaess, M.F. Fallon, H. Johannsson, J. J. Leonard and J.B. McDonald, RSS RGB-D Workshop ‘12
- A method and system for mapping an environment, T. Whelan, M. Kaess, J.J. Leonard and J.B. McDonald, US 9412173 B2
本文重点介绍第一篇,其中涵盖诸多其他文章、专利的相关算法。文章主要使用Volume Fusion的方法对采集到的点云数据进行融合重建,并结合图像特征进行闭环检测和优化,得到质量比较高的点云和三角面片。文章亮点:
- 大场景。可以重建数百米的场景,不用太够关心内存(显存)问题
- 实时。速度很快,依赖cuda,可以做到实时跟踪与重建
- 利用普通RGB-D相机就可以。作者默认使用华硕Xtion
其中,使用循环缓存的方式来解决大场景的内存问题,在下文中使用Volume shifting做重点介绍。相机姿态的跟踪采用点云特征和图像特征融合的方式。通过场景识别来检测轨迹闭环。
文章在KinectFusion算法的基础上做了许多理论和实践上的改进。KinectFusion效果好,精度高,但存在一些问题,比如只能重建固定小场景的区域,且仅依赖深度点云信息进行位置的跟踪(未使用图像特征),而且没有进行闭环检测。而VolumeFusion在这3个方面做了很好的改进和优化。
Kintinuous在实现上类似PTAM,Tracking和Mapping分别在独立的线程。代码里称作front-end 和back-end,甚至放在不同文件夹,使得阅读更加容易。
文章主要包括三个部分:
1. Extended Scale Volumetric Fusion
基于KinectFusion的Volume Fusion
文章用有符号距离(signed distance)来表达点元到表面(Surface)的距离的空间数据。参加文章Figure 1. GPU中存储的TSDF数据是以三维数组的形式表示的。Truncated signed distance function (TSDF) is a volumetric data structure that encodes implicit surfaces by storing the signed distance to the closest surface at each voxel up to a given truncation distance fromthe actual surface position.
每一个voxel包含一个16位浮点型距离S(s)T(signed distance)、一个无符号权重S(s)w和RGB值。总共6个字节。融合新的深度图时,可以利用文中相关函数更新。
Volume用来存储点云的信息;当相机移动位置偏大时,移动Volume而不是增大Volume,并对Volume进行数据的整理和地图生成,减少内存消耗。
TSDF使用的内存固定,其尺寸Vs为512,这样算下来总共需要GPU的显存512×512×512×6÷1024 = 768 MB。
初始时R为单位矩阵,I为0阵,即相机中心为原点。
Volume Shifting
体移动,其实指的是体(Volume)的中心移动。此方案使用了循环缓存的方式,将使用空间限制在768MB。移动的标准并不复杂,大于一定阈值时才移动,否则不动。fuxingyin文章中有详解。
Surface Extraction
建图与重建的过程,如下图1所示。
每一次Volume Shifting的时刻,选择剥离出的Slice区域中的TSDF模型的接近0的值的区域,生成点云。提取方法是与坐标轴的三个平行的方向进行Raycast,并检测TSDF中符号变化点zero crossings,并将其剥离出来,就是重建好的场景点云。仅仅选出权重最小的点。之后采用一定方法生成点云和Mesh,并转移到主内存中。点云通过filter进行重复点云的剥离,逐渐融合成为最终的模型。
每一份被剥离出来的点云组合成为云片(cloud slice)。通过GPT算法对持续剥离的云片进行处理和融合,保证生成完整的mesh。
本文并不使用Cube fusion的方式是为了不影响Volume Shifting,而用3个方向的Raycast的效率比较高,包括完成GPU和内存之间的数据交换。
每一个(剥离出的)云片(cloud slice)对应一个camera pose,如图1所示。
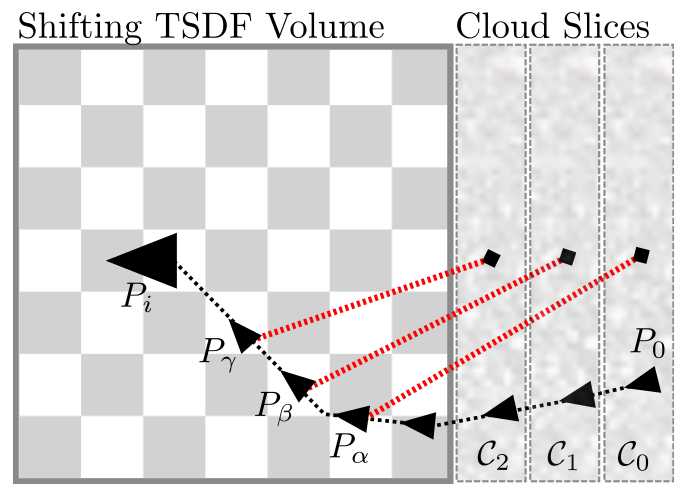
图1.(文章中原Figure.4)Volume Shifting时生成的点云片(Cloud Slices),左侧的相机姿态是全局坐标。右侧的C0,C1,C2表示被切分的云片。
Dynamic Cube Positioning
相机放在动态立方体中的位置。如果放在正中,则视野上的数据只有一部分。而根据圆形或者球星模型来摆放,空间利用率会大大提高。相机的中心放在Cube内的一个圆(球)上。文章中写的很清楚。
Color Estimation 颜色估计
同Volume fusion类似,颜色的估计也是利用加权平均的思想,去除噪声和一些光线散射、折射等影响。
2.Camera Pose Estimation
相机位姿估计
基于KinectFusion的几何估计存在一些问题,比如对一些走廊等区域,空洞大的区域处理不好。VolumeFusion则采用几何信息和图像信息融合的方式,利用GPU达到了实时位置跟踪。
2.1 几何估计。几何估计的基础依旧是KinectFusion中的TSDF模型,核心依旧是ICP(Iterative Closest Point)算法(ICP是图形学中的经典算法,与很多变种,后期的文章中会单独介绍)。文章采用基于GPU的ICP算法来加快运算,能量函数采用的是point-to-plane的距离,并根据近似原理做了线性化,这点跟KinectFusion类似,并有了进一步的改进。最终的结果通过一个6×6的雅克比矩阵,获得当前最优的增加,直到点云的对齐。
2.2 图像信息估计。在拥有深度信息的前提下,文章利用光流法的思想,通过最小化Photometic Error方式,获取最优的姿态。
- 预处理,包括深度图和rgb图的去噪、滤波等
- 类似直接法的思想,只处理梯度较大的区域,比特征点提取的数目更多
- Iterativet transformation estimation, 分两部进行,先投影,后解一个线性方程来获取增量
3.3 联合姿态估计。采用的方法是将两个cost进行加权叠加。
E = Eipc + wrgbdErgbd (1)
其中wrgbd是权重,根据经验设为0.1.
颜色的权重是frame-to-frame的对齐,而几何权重是frame-to-model的对其(icp)。每一次迭代我们通过获取雅克比矩阵获得增量。其结果比较准确,轨迹较为稳定。
3. Loop Closure
闭环
由于误差累计的原因,漂移问题是所有SLAM或者里程计系统都需要面对的问题。同相机估计类似,文章采用几何和色彩特征联合的方式获取闭环,完成Pose Graph矫正。
作者选择了一个非刚体(non-rigid)的方法进行处理,将系统分为前段和后端。
- 前段 front-end
- 拓展体积融合
- 相机位姿估计
- Place recognition (DBow, bags of words)场景识别模块
- 后端 back-end
- dense map deformation,通过Pose Graph的优化。通过闭环的结果,使用iSam的方法来优化位姿
- 优化的轨迹通过匹配好的图像特征来限制非刚体的空间变形
所有的相机位姿都采用全局坐标系,而多个相机姿态直接都有相互对应关系。熟悉slam算法的同学可能知道g2o库就是为了解决类似这样的闭环问题的全局最优库。
Place Recognition 场景识别
闭环特征并不是每一帧都加入,而是根据一定的规则,即在平移和旋转达到一定程度时,才选择加入本帧特征。选择的标准如下(a, b表示两个位姿)
mab = ||r(Ra-1Rb) ||2 + ||ta - tb ||2 (2)
其中带下标的R和t分别代表旋转和平移矩阵。公式(2)是一个综合评估旋转和平移的公式,每一帧图片加入时,我们依照公式(2)将其与上一个加入场景的frame计算距离mab。如果此距离达到一定阈值mp,则将此帧加入。文中选择mp=0.3.
不过,选择和平移两个分量可以分别选择,比如选择达到一定角度,或者平移大于一定距离。但实际效果差别并不大。
闭环的检测采用场景识别的方式。作者采用SURF特征(Speeded Up Robust Feature, 熟悉图像视觉的同学肯定不会陌生)结合DBoW来检测闭环。具体方法如下:
- 针对SURF特征,采用基于k-d tree的FLANN库做快速特征匹配。注:DBoW库也是SLAM研究中的常用库,高效,准确。
- 两个Frame的匹配采用RANSAC Transformation Estimation的方法,如果匹配率在25%以下则认为不是闭环。否则,使用LM(Levenberg–Marquardt algorithm)优化方法对其进行位置估计。
- 此时两个frame的点云几何特征和图像特征比较一致。为了提高速度,对点云进行了下采样。利用前一步RANSAC的结果作为初始估计进行ICP,当残差小于一定阈值时,认为匹配成功。
一个闭环检测成功之后,便加入到Pose-Graph中,供后面的优化过程(space deformation 和 Optimisation)使用。
Space Deformation 空间变形
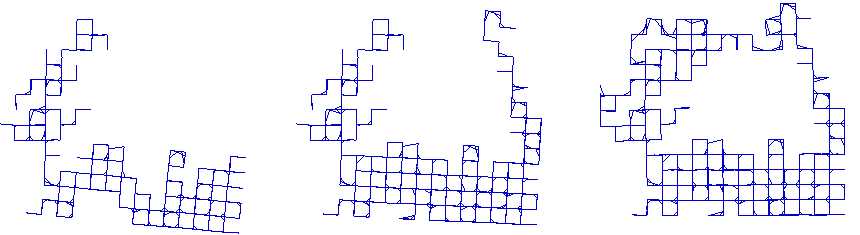
图2. iSam文章中Manhattan数据优化的步骤
由于不可避免的漂移问题,需要在完成闭环检测后对建好的地图进行矫正,达到类似图2的效果,将漂移的部分修正回来。
1. deformation graph, 由点云(Mesh)中的点和面构成。
2. incremental graph. 原本的方法是在3D空间中均匀采样,并形成deformation graph,但简单的采样和连接会生成Graph中一些无关的点。这样导致的问题可参照原文中图12。为此作者提出了incremental graph, 采样的方法文章中有详细描述(方法比较tricky,可能会单独写一篇文章分析)。
3. Vertex权重选择.每一个vertex都在Graph中有一个影响区域,其权重跟其邻域内其他Vertex的距离相关。
Optimisation 优化
检测到闭环时,进行两步优化。首先进行位姿(Pose)优化,然后是稠密地图优化(point cloud)。位姿的优化采用iSam框架,参见图2。
地图的优化 优化的目标包含3个cost functions。首先是最大刚体化(as rigid as possible)。第二项是平滑项。第三项是对闭环的轨迹位置进行优化。其中包括匹配好的SURF特征。实际中包括四项:
wrotErot + wregEreg + WconpEconp + WsurfEsurf
权重选择wsurf = 100而wrot = 1,可见其对图像特征的依赖程度。优化方案为Gauss-Newton法。
4. 重建结果
文章中的结果已经比较多,各种数据比较也说明了其优势。下面贴一下自己在房间内测试的结果。由于使用的GPU较弱,大概能达到12~15 fps的速率。

图3 Desk,仅重建一面墙的结果。多视角融合的效果比较好,墙壁和地面均比较平。未包含纹理信息。

图4 另外一个角度,带纹理和天花板信息。
以上是关于Kintinuous 相关论文 Volume Fusion 详解的主要内容,如果未能解决你的问题,请参考以下文章