tf-idf sklearn
Posted bafenqingnian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了tf-idf sklearn相关的知识,希望对你有一定的参考价值。
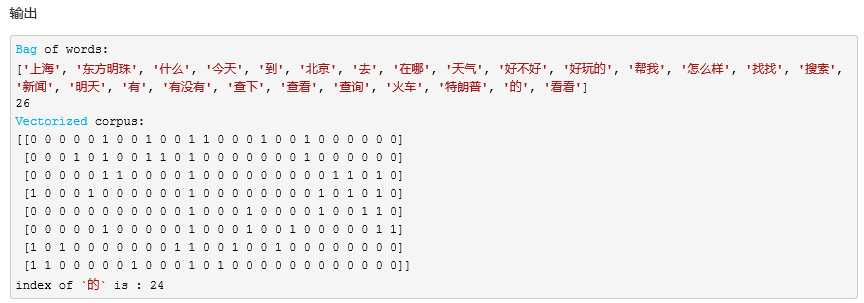
第一步:语料转化为词袋向量
step 1. 声明一个向量化工具vectorizer;
本文使用的是CountVectorizer,默认情况下,CountVectorizer仅统计长度超过两个字符的词,但是在短文本中任何一个字都可能十分重要,比如“去/到”等,所以要想让CountVectorizer也支持单字符的词,需要加上参数token_pattern=‘\\b\\w+\\b‘。
step 2. 根据语料集统计词袋(fit);
step 3. 打印语料集的词袋信息;
step 4. 将语料集转化为词袋向量(transform);
step 5. 还可以查看每个词在词袋中的索引。
代码:

step 1中: min_df、max_df 表示一个阈值,低于、超过这个阈值的词汇讲被忽略
from sklearn.feature_extraction.text import CountVectorizer
# step 1
vectoerizer = CountVectorizer(min_df=1, max_df=1.0, token_pattern=‘\\b\\w+\\b‘)
# step 2
vectoerizer.fit(corpus)
# step 3
bag_of_words = vectoerizer.get_feature_names()
print("Bag of words:")
print(bag_of_words)
print(len(bag_of_words))
# step 4
X = vectoerizer.transform(corpus)
print("Vectorized corpus:")
print(X.toarray())
# step 5
print("index of `的` is : {}".format(vectoerizer.vocabulary_.get(‘的‘)))
第二步:根据词袋向量统计TF-IDF
step 1. 声明一个TF-IDF转化器(TfidfTransformer);
step 2. 根据语料集的词袋向量计算TF-IDF(fit);
step 3. 打印TF-IDF信息:比如结合词袋信息,可以查看每个词的TF-IDF值;
step 4. 将语料集的词袋向量表示转换为TF-IDF向量表示;
from sklearn.feature_extraction.text import TfidfTransformer
# step 1
tfidf_transformer = TfidfTransformer()
# step 2
tfidf_transformer.fit(X.toarray())
# step 3
for idx, word in enumerate(vectoerizer.get_feature_names()):
print("{} {}".format(word, tfidf_transformer.idf_[idx]))
# step 4
tfidf = tfidf_transformer.transform(X)
print(tfidf.toarray())
输出
上海 1.8109302162163288 东方明珠 2.504077396776274 什么 2.504077396776274 今天 2.504077396776274 到 2.504077396776274 北京 1.587786664902119 去 2.504077396776274 在哪 2.504077396776274 天气 2.09861228866811 好不好 2.504077396776274 好玩的 2.504077396776274 帮我 1.0 怎么样 2.504077396776274 找找 2.504077396776274 搜索 2.504077396776274 新闻 2.09861228866811 明天 2.504077396776274 有 2.504077396776274 有没有 2.504077396776274 查下 2.09861228866811 查看 2.09861228866811 查询 2.504077396776274 火车 2.09861228866811 特朗普 2.504077396776274 的 1.587786664902119 看看 2.504077396776274 [[0. 0. 0. 0. 0. 0.3183848 0. 0. 0.42081614 0. 0. 0.20052115 0.50212047 0. 0. 0. 0.50212047 0. 0. 0.42081614 0. 0. 0. 0. 0. 0. ] [0. 0. 0. 0.50212047 0. 0.3183848 0. 0. 0.42081614 0.50212047 0. 0.20052115 0. 0. 0. 0. 0. 0. 0. 0.42081614 0. 0. 0. 0. 0. 0. ] [0. 0. 0. 0. 0. 0.33116919 0.52228256 0. 0. 0. 0. 0.20857285 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.52228256 0.43771355 0. 0.33116919 0. ] [0.38715525 0. 0. 0. 0.53534183 0. 0. 0. 0. 0. 0. 0.21378805 0. 0. 0. 0. 0. 0. 0. 0. 0.44865824 0. 0.44865824 0. 0.33944982 0. ] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.23187059 0. 0. 0. 0.48660646 0. 0. 0. 0. 0.48660646 0. 0. 0.5806219 0.36816103 0. ] [0. 0. 0. 0. 0. 0.33116919 0. 0. 0. 0. 0. 0.20857285 0. 0. 0. 0.43771355 0. 0. 0.52228256 0. 0. 0. 0. 0. 0.33116919 0.52228256] [0.33420711 0. 0.4621274 0. 0. 0. 0. 0. 0. 0. 0.4621274 0.18454996 0. 0. 0.4621274 0. 0. 0.4621274 0. 0. 0. 0. 0. 0. 0. 0. ] [0.37686288 0.52110999 0. 0. 0. 0. 0. 0.52110999 0. 0. 0. 0.20810458 0. 0.52110999 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. ]]
出处: http://www.cnblogs.com/CheeseZH/
上面的sklearn 的函数介绍:
CountVectorizer 实例介绍:

以上是关于tf-idf sklearn的主要内容,如果未能解决你的问题,请参考以下文章