数据挖掘---支持向量机(SVM)
Posted junge-mike
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘---支持向量机(SVM)相关的知识,希望对你有一定的参考价值。
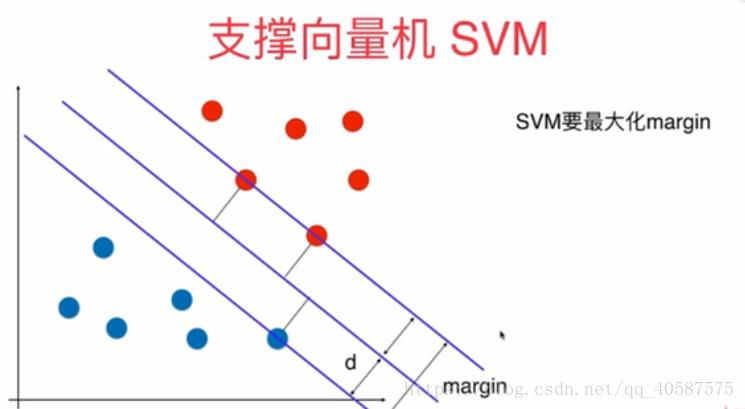
?1.SVM 的基本思想:
?SVM把分类问题转换成寻求分类平面的问题,并通过最大化分类边界点到分类平面的距离来实现分类。通俗的讲支持向量机的解决的问题是找到最好的分类超平面。支持向量机(Support vector machine)通常用来解决二分类问题
![]() ?
?
2.构造目标函数
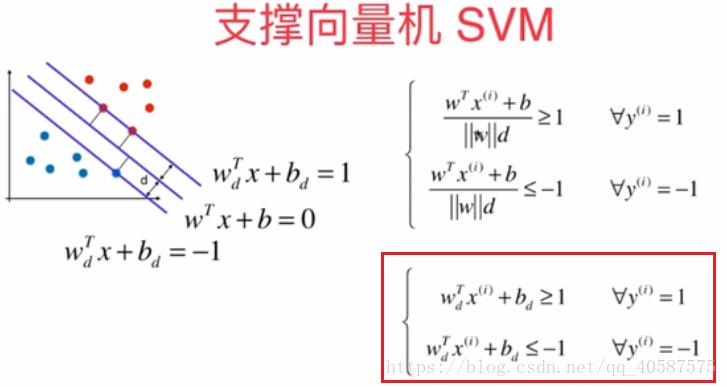
类似于点到直线的距离,可以得到点到超平面的距离为
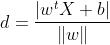
![]() ?
?
?在Logistic回归算法,我们是把数据分成0类和 1 类,而同样为了推导式子的方便性,采用-1 和 1 两类。
可以将红色框的式子转换成:
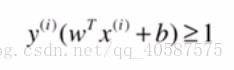
![]() ?
?
?目标方程:

![]() ?
?
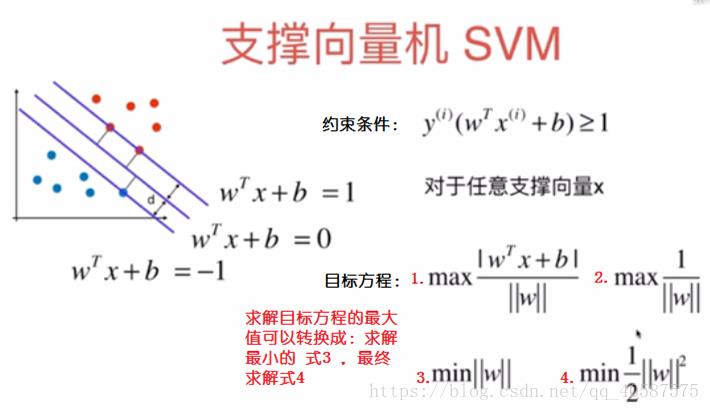
![]() ?
?
我们需要求的是:两数据集中几个数据最近的点的最大的距离。
在满足约束条件(即样本点为支持向量)下,最大的几何间隔中取最小的值。max L(w,b,a) 是得到支持向量的样本点,然后再这些样本点中找到min 1/2 || w ||2 的最小值(最大间隔)。
?可以得到有条件约束的最优化问题,通常引入拉格朗日函数简化上述问题,称此类问题为对偶问题(The wolfe dualproblem)。
?使用拉格朗日乘数法用来解决等式约束下的最优化问题:
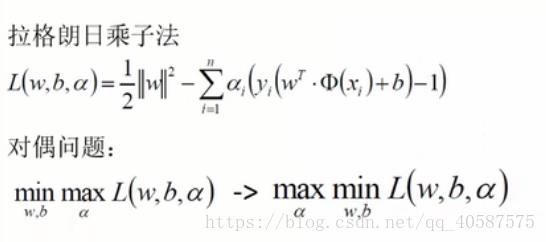
![]() ?
?
?对偶问题的求解:
?步骤1 :固定 α ,然后L(ω, b, α)对 ω 、b 求偏导,令其偏导数等于0。
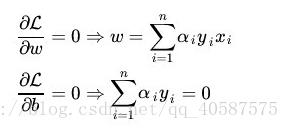
![]() ?
?
?把上述2式带入到L(ω, b, α)当中:

![]() ?
?
?步骤2 :对 α 求极大,通过步骤1 已经把变量 ω 、b 消去,函数只有 α。
?在式子前面加个 - 负号,是求极大值转换成求极小值:

![]() ?
?
3.软间隔
?实际遇到的问题数据总是有噪音的,也就是说可能存在一两个可忽略的特殊点使margin大大减小,也可能有一两个特殊点导致集合线性不可分(如下图),所以我们需要允许模型犯一定的错误来过滤掉噪音,即允许间隔的调整称为软间隔。

![]() ?
?

![]() ?
?

![]() ?
?
?4.核函数kernel
(多项式核函数)(高斯核函数计算花销大:gamma越大会形成过拟合,越小则会欠拟合)(升维)
?设χ是输入空间(欧氏空间或离散集合),Η为特征空间(希尔伯特空间),如果存在一个从χ到Η的映射
?φ(x):χ→Η
?使得对所有的x,z∈χ,函数Κ(x,z)=φ(x)?φ(z), 则称Κ(x,z)为核函数,φ(x)为映射函数,φ(x)?φ(z)为x,z映射到特征空间上的内积。
?由于映射函数十分复杂难以计算,在实际中,通常都是使用核函数来求解内积,计算复杂度并没有增加,映射函数仅仅作为一种逻辑映射,表征着输入空间到特征空间的映射关系。至于为什么需要映射后的特征而不是最初的特征来参与计算,为了更好地拟合是其中一个原因,另外的一个重要原因是样例可能存在线性不可分的情况,而将特征映射到高维空间后,往往就可分了。

![]() ?
?

![]() ?
?
5.SMO(Sequential Minimal Optimization, 序列最小优化)算法解析:
SVM,有许多种实现方式,SMO算法实现是一种。
1998年,由Platt提出的序列最小最优化算法(SMO)可以高效的求解上述SVM问题,它把原始求解N个参数二次规划问题分解成很多个子二次规划问题分别求解,每个子问题只需要求解2个参数,方法类似于坐标上升,节省时间成本和降低了内存需求。每次启发式选择两个变量进行优化,不断循环,直到达到函数最优值。
参考:SVM支持向量机推导
以上是关于数据挖掘---支持向量机(SVM)的主要内容,如果未能解决你的问题,请参考以下文章