Scala学习之路----基础入门
Posted qwangxiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scala学习之路----基础入门相关的知识,希望对你有一定的参考价值。
一、Scala解释器的使用
REPL:Read(取值)-> Evaluation(求值)-> Print(打印)-> Loop(循环)
scala解释器也被称为REPL,会快速编译scala代码为字节码,然后交给JVM来执行。
计算表达式:在scala>命令行内,键入scala代码,解释器会直接返回结果。
如果你没有指定变量来存放这个值,那么值默认的名称为res,而且会
显示结果的数据类型,比如Int、Double、String等等。
例如,输入1 + 1,会看到res0: Int = 2
内置变量:在后面可以继续使用res这个变量,以及它存放的值。
例如,"Hi, " + res0,返回res2: String = Hi, 2
自动补全:在scala>命令行内,可以使用Tab键进行自动补全。
二、声明变量
声明val常量:可以声明val常量来存放表达式的计算结果。
例如,val result = 1 + 1
但是常量声明后,是无法改变它的值的,否则会返回error: reassignment
to val的错误信息。
声明var变量:如果要声明值可以改变的引用,可以使用var变量。
例如,var myresult = 1,myresult = 2
但是在Scala程序中,通常建议使用val,也就是常量。
因为在Spark的大型复杂系统中,需要大量的网络传输数据,
如果使用var,值可能被错误的更改,所以建议多使用val。
三、数据类型与操作符
1》基本数据类型: Byte、 Char、 Short、 Int、 Long、 Float、 Double、 Boolean。
Scala的数据类型统一都是类。 Scala自己会负责基本数据类型和引用类型的转换操作。
使用以上类型, 直接就可以调用大量的函数, 例如, 1.toString(), 1.to(10)。
类型的加强版类型: Scala使用很多加强类给数据类型增加了上百种增强的功能或函数。
·例如, String类通过StringOps类增强了大量的函数, "Hello".intersect(" World")。
·例如, Scala还提供了RichInt、 RichDouble、 RichChar等类型, RichInt就提供了to函数, 1.to(10), 此处Int先隐式转换为RichInt,然后再调用其to函数。
2》基本操作符: Scala的算术操作符与Java的算术操作符也没有什么区别, 比如+、 -、 *、 /、 %等, 以及&、 |、 ^、 >>、 <<等。
但是, 在Scala中, 这些操作符其实是数据类型的函数, 比如1 + 1, 可以写做1.+(1)
例如, 1.to(10), 又可以写做1 to 10
注:Scala中没有提供++、--操作符, 我们只能使用+和-, 比如counter = 1,counter++是错误的, 必须写做counter += 1
3》除了方法之外,Scala还提供函数
数学函数:sqrt() pow() min()
引入特定包时使用import 包名._;
import scala.math._ ,_是通配符,类似Java中的*
四、流程控制结构
1、if表达式的定义: 在Scala中, if表达式是有值的, 就是if或者else中最后一行语句返回的值。
例如, val age = 30; if (age > 18) 1 else 0
可以将if表达式赋予一个变量, 例如, val isAdult = if (age > 18) 1 else 0
另外一种写法, var isAdult = -1; if(age > 18) isAdult = 1 else isAdult = 0, 但是通常使用上一种写法
2、if表达式的类型推断: 由于if表达式是有值的, 而if和else子句的值类型可能不同, 此时if表达式的值是什么类型呢?
Scala会自动进行推断, 取两个类型的公共父类型Any。
例如, if(age > 18) 1 else 0, 表达式的类型是Int, 因为1和0都是Int
例如, if(age > 18) "adult" else 0, 此时if和else的值分别是String和Int, 则表达式的值是Any, Any是String和Int的公共父类型。
如果if后面没有跟else, 则默认else的值是Unit, 也用()表示, 类似于Java中的void或者null。
例如, val age = 12; if(age > 18) "adult"。 此时就相当于if(age > 18) "adult" else ()。
3、将if语句放在多行中: 默认情况下, REPL只能解释一行语句, 但是if表达式通常需要放在多行。
可以使用{}的方式, 比如以下方式, 或者使用:paste和ctrl+D的方式。
if(age > 18) { "adult"
} else if(age > 12) "teenager" else "children"
注:默认情况下, Scala不需要语句终结符, 默认将每一行作为一个语句
4、一行放多条语句: 如果一行要放多条语句, 则必须使用语句终结符
例如, 使用分号作为语句终结符, var a, b, c = 0; if(a < 10) { b = b + 1;c = c + 1 }
通常来说, 对于多行语句, 还是会使用花括号的方式
var a, b, c = 0;if(a < 10) {
b = b + 1;c = c + 1}
5、块表达式: 块表达式, 指的就是{}中的值, 其中可以包含多条语句, 最后一个语句的值就
是块表达式的返回值。
例如, var d = if(a < 10) { b = b + 1; c + 1 }
6、输入和输出
print和println: print打印时不会加换行符, 而println打印时会加一个换行符。
printf可以用于进行格式化,例如, printf("Hi, my name is %s, I‘m %d years old .", "Leo", 30)
readLine: readLine允许我们从控制台读取用户输入的数据, 类似于Java中的System.in和Scanner的作用。
综合案例:使用paste和ctrl+D
val name = readLine("Welcome to Game House. Please tell me your name: ")
print("Thanks. Then please tell me your age: ")
val age = readInt()
if(age > 18) {
printf("Hi, %s, you are %d years old, so you are legel to come here!", name, age)
} else {
printf("Sorry, boy, %s, you are only %d years old. you are illegal to come here!",
name, age)
}
五、循环
1、Scala拥有与Java相同的while和do-while循环
但没有与for(初始化变量;判断条件;更新变量)循环直接对应的对构。
Scala中的for:for(i<-表达式),让变量i遍历<-右边表达式的所有值。
注意:
1、在for循环的变量之前并没有val或var的指定,该变量的类型是集合的元素类型。
2、循环变量的作用域一直持续到循环结束
3、to 和 until,两者得到都是集合,区别如下:
scala> 1 to 10 (包含10)
res8: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
scala> 1 until 10 (不包含10)
res10: scala.collection.immutable.Range = Range(1, 2, 3, 4, 5, 6, 7, 8, 9)
4、循环的几种遍历方式
一、直接遍历------遍历字符串
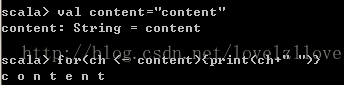
二、求和---------1到8的和

三、以 变量<-表达式 的形式提供多个生成器,用分号将它们隔开(嵌套循环)
for(i<- 1 to 9;j<- 1 to i){
if(i==j) println(j+"*"+i+"="+j*i)
else print(j+"*"+i+"="+j*i+" ")
}
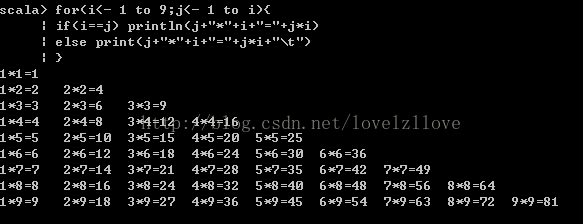
四、在循环中使用变量
for(i<- 1 to 6;tem=2*i-1;j<- 1 to tem){
print("*");if(j==tem) {println()}}
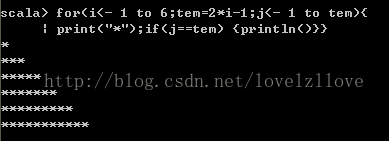
五、守卫式,即在for循环中添加过滤条件if语句
for(i<- 1 to 3;j<- 1 to 3 if i!=j) print((10*i+j)+" ")
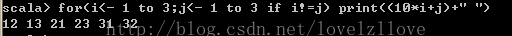
六、推导式
如果for循环的循环体以yield开始,则该循环会构造出一个集合,每次迭代生成集合中的一个值。

六、函数
1、函数的分类
单行函数:def sayHello(name: String) = print("Hello, " + name)
多行函数:如果函数体中有多行代码, 则可以使用代码块的方式包裹多行代码, 代码块中最后一行
的返回值就是整个函数的返回值。 与Java中不同, 不能使用return返回值。
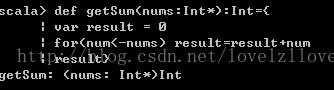
比如如下的函数, 实现累加的功能:
def sum(n: Int) :Int= {
var sum = 0;
for(i <- 1 to n) sum += i
sum}
2、函数的定义与调用
在Scala中定义函数时, 需要定义函数的函数名、 参数、 函数体。
def sayHello(name: String, age: Int) = {
if (age > 18) { printf("hi %s, you are a big boy
", name); age }
else { printf("hi %s, you are a little boy
", name); age}}
调用:sayHello("leo", 30)
注:Scala要求必须给出所有参数的类型, 但是不一定给出函数返回值的类型。
只要右侧的函数体中不包含递归的语句, Scala就可以自己根据右侧的表达式推断出返回类型。
3、递归函数与返回类型
如果在函数体内递归调用函数自身, 则必须给出函数的返回类型。
例如, 实现经典的斐波那契数列:
def feibo(n:Int):Int={
if(n<=2) 1
else feibo(n-1)+feibo(n-2)}
例如如下阶乘:
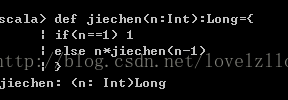
4、参数
1》默认参数
在Scala中, 有时我们调用某些函数时, 不希望给出参数的具体值, 而希望使用参数自身默认的值, 此时就在定义函数时使用默认参数。
def sayHello(firstName: String, middleName: String = "William", lastName:
String = "Croft") = firstName + " " + middleName + " " + lastName
如果给出的参数不够, 则会从左往右依次应用参数。
Java与Scala实现默认参数的区别如下:
-----------------------------------------------------------------------------------
Java:
public void sayHello(String name, int age) {
if(name == null) {
name = "defaultName"
} if(age == 0) {
age = 18
}}
sayHello(null, 0)
-----------------------------------------------------------------------------------
Scala:
def sayHello(name: String, age: Int = 20) {
print("Hello, " + name + ", your age is " + age)}
sayHello("leo")
2》带名参数
在调用函数时, 也可以不按照函数定义的参数顺序来传递参数, 而是使用带名参数的方式来
传递。如:sayHello(firstName = "Mick", lastName = "Nina", middleName = "Jack")
还可以混合使用未命名参数和带名参数, 但是未命名参数必须排在带名参数前面。如下:
正确:sayHello("Mick", lastName = "Nina", middleName = "Jack")
错误:sayHello("Mick", firstName = "Nina", middleName = "Jack")
3》使用序列调用变长参数
在如果要将一个已有的序列直接调用变长参数函数, 是不对的。 比如val s = sum(1 to 5)。
此时需要使用Scala特殊的语法将参数定义为序列, 让Scala解释器能够识别。
这种语法非常有用!Spark的源码中大量地使用。
例如:val s = sum(1 to 5 : _*) 通过:_*转换成参数序列
案例: 使用递归函数实现累加,如下:
def sum2(nums: Int*): Int = {
if (nums.length == 0) 0
else nums.head + sum2(nums.tail: _*)
}
调用:sum2(1,2,3,4,5) 或是 sum2(1 to 5 :_*)
注:1、定义nums为一个变长参数,定义函数时用*,调用函数需要表示一个参数序列时用:_*
2、head 表示集合中的第一个元素,tail 表示集合中除了第一个元素外的其他元素
七、过程
定义:在Scala中, 定义函数时, 如果函数体直接包裹在了花括号里面, 而没有使用=连接,
则函数的返回值类型就是Unit, 这样的函数就被称之为过程。过程通常用于不需要返回值的函数。
过程还有一种写法, 就是将函数的返回值类型定义为Unit。比较如下:
def sayHello(name: String) = "Hello, " + name
def sayHello(name: String) { print("Hello, " + name); "Hello, " + name }
def sayHello(name: String): Unit = "Hello, " + name
八、lazy值
在Scala中, 提供了lazy值的特性, 也就是说, 如果将一个变量声明为lazy, 则只有在第一次使用
该变量时, 变量对应的表达式才会发生计算。这种特性对于特别耗时的计算操作特别有用, 比如打开文件进行IO, 进行网络IO等。
1、import scala.io.Source._
lazy val lines = fromFile("C://Users//Administrator//Desktop//test.txt").mkString
即使文件不存在, 也不会报错, 只有第一次使用变量时会报错, 证明了表达式计算的lazy特性
val lines = fromFile("C://Users//Administrator//Desktop//test.txt").mkString 这句会报错
2、val lines=sc.textFile("file:///home/tg/datas/ws")
val rdd1=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
val rdd2=rdd1.collect
算子: flatMap() map() reduceByKey()转换类型的算子(transformation)
collect()行动类型的算子(action)
3、val rdd=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).map(m=>(m._2,m._1))
.sortByKey(true).map(m=>(m._2,m._1)).collect
注:转换类型的算子就是lazy类型,当遇到action行动类型的算子时,才会触发执行。
总结下划线的用法:
1、导包时,导入包中所有内容 import scala.io.Source._
2、将数列(集合)转换成参数序列 val result=sum(1 to 10:_*)
3、表示Spark算子操作的每一个元素 lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
八、异常
在Scala中, 异常处理和捕获机制与Java是非常相似的。
try {
throw new IllegalArgumentException("x should not be negative")
} catch {
case _:IllegalArgumentException => println("Illegal Argument!")
} finally {
print("release resources!")
}
try {
throw new IOException("user defined exception")
} catch {
case e1:IllegalArgumentException => println("illegal argument")
case e2:IOException => println("io exception")
}
九、数组
若数组长度固定使用Array,若数组长度不固定则使用ArrayBuffer
1、定长数组的两种创建方式
1》val nums=new Array[Int](10); //10个整数的数组 2》val array=Array("hello","jack")
省略关键字new创建数组的方式,实际上调用的是 Array.scala中的apply()方法。源码如下:
def apply[T: ClassTag](xs: T*): Array[T] = {
val array = new Array[T](xs.length)
var i = 0
for (x <- xs.iterator) {
array(i) = x;
i += 1 }
array}
2、变长数组:数组缓冲
注:scala.collection.mutable._ 可变 scala.collection.immutable._ 不可变
对于那种长度按需要变化的数组,Java有ArrayList,Scala有ArrayBuffer
变长数组ArrayBuffer使用时要导包 import scala.collection.mutable.ArrayBuffer
var arr1=ArrayBuffer[Int]()
变长数组操作:1、arr1+=1 2、arr1+=(2,5,6) 3、arr1 ++=Array(3,4)
4、arr1.trimEnd(5) 返回值为空,需再次调用arr1来查看删除后的数据
5、arr1.insert(1,3,4) 指定1的位置添加3,4元素

6、arr1.remove(3)

7、arr1.remove(3,2) 指定位置删除指定数量的元素

3、变长数组与定长数组之间的转换
变长数组→定长数组:.toArray (不改变原来的数组,系统会自动创建一个新的arry)
定长数组→变长数组:.toBuffer
4、遍历数组
until是RichInt类的方法, 返回所有小于( 不包括) 上限的数字。

5、数组常用算法
,除了sum求和,max最大值,min最小值以外还有如下:

6、数组的quickSort()快速排序方法scala.util.Sorting.quickSort(array)
十、高阶函数
filter :把一个函数作为参数的函数
for(i <- 0 until arr1.length if(arr1(i)%2==0)) print(arr1(i)+" ")
array.filter(m=>m%2==0) 这里的m可以省去简写成 array.filter(_%2==0)
m=>m%2==0 匿名函数 m=>{m%2==0}
算子: spark中的算子有一部分是和scala中的高阶函数是一致的,
但是有一部分是scala中没有的,比如reducekey
简写用下划线代替m: val rdd=lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
lines.flatMap(m=>m.split(" ")).map(word=>(word,1)).reduceByKey((x,y)=>x+y)
十一、映射(Map)1、Scala映射就是键值对的集合Map。默认情况下,Scala中使用不可变的映射。
如果想使用可变集合Map,必须导入scala.collection.mutable.Map
不可变:
val map=Map("tom"->20,"jack"->23,"marray"->22)
val map2=Map(("tom",20),("jack",23),("marray",22))
可变:
val map3=scala.collection.mutable.Map(("tom",20),("jack",23),("marray",22))
val map4=new scala.collection.mutable.HashMap[String,Int]
映射这种数据结构是一种将键映射到值的函数。 区别在于通常的函数计算值, 而映射只是做查询。
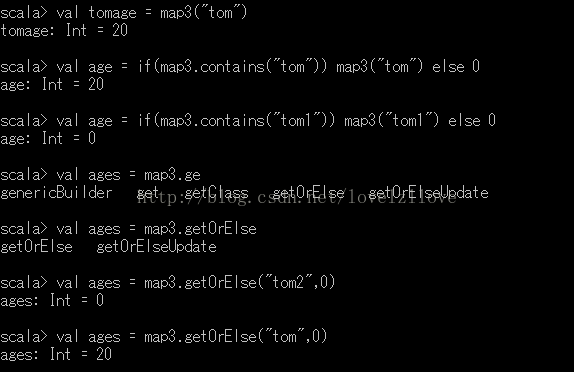
2、获取映射中的值
注:1》如果映射并不包含请求中使用的键, 则会抛出异常。
2》要检查映射中是否有某个指定的键, 可以用contains方法。
3》getOrElse方法, 若包含相应的键, 就返回这个键所对应的值, 否则返加0。
4》映射.get(键)这样的调用返回一个Option对象, 要么是Some(键对应的值), 要么是None。
3、修改Map的元素
更新可变Map集合:
1》更新Map的元素 ages(www.quyingyulecs.com "Leo") = 31
2》增加多个元素 ages += ("Mike" -> 35, "Tom" -> 40)
3》 移除元素 ages -= "Mike"
更新不可变Map集合:
1》 添加不可变Map的元素, 产生一个新的集合Map, 原Map不变
val ages2 = ages + ("Mike" -> 36, "Tom" -> 40)
2》移除不可变Map的元素, 产生一个新的集合Map, 原Map不变
val ages3 = ages - "Tom"
4、遍历Map操作
//遍历map的entrySet for ((key, value) <- ages) println(key + " " + value)
// 遍历map的key for (key <- ages.keySet) println(key)
// 遍历map的value for (value <- ages.values) println(value)
// 生成新map, 反转key和value for ((key, value) <- ages) yield (value, key)
5、SortedMap和LinkedHashMap
// SortedMap可以自动对Map的key的排序
val ages = scala.collection.immutable.SortedMap("leo" -> 30, "alice" -> 15, "jen" -> 25)
// LinkedHashMap可以记住插入entry的顺序
val ages = new scala.collection.www.dasheng178.com/ mutable.LinkedHashMap[String, Int]
ages("leo") = 30
ages("alice") = 15
ages("jen") = 25
6、Java Map与Scala Map的隐式转换
import scala.collection.JavaConversions.mapAsScalaMap
val javaScores = new java.util.HashMap[String, Int]()
javaScores.put("Alice", 10)
javaScores.put("Bob"www.mhylpt.com, 3)
javaScores.put("Cindy", 8)
val scalaScores: scala.collection.mutable.Map[String, Int] = javaScores
===========================================================
import scala.collection.JavaConversions.mapAsJavaMap
import java.awt.font.TextAttribute._
val scalaAttrMap = Map(FAMILY -> "Serif", SIZE -> 12)
val font = new java.awt.Font(scalaAttrMap)
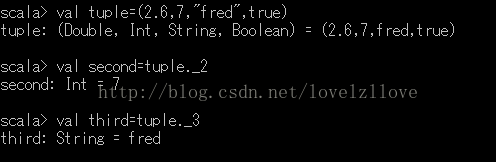
7、元组(tuple)
概念:元组是不同类型的值的聚集,对偶是元组的最简单形态,元组的索引从1开始,而不是0
Tuple拉链操作:
Tuple拉链操作指的就是zip操作,zip操作是Array类的方法, 用于将两个Array, 合并为一个Array
比如 Array(v1)和Array(v2), 使用zip操作合并后的格式为Array((v1,v2)),合并后的Array的元素类型为Tuple。例子如下:
val students = Array("Leo", "Jack", "Jen")
val scores = Array(80, 100, 90)
val studentScores = students.zip(scores)
for ((student, score) <- studentScores) println(student + " " + score)
注:如果Array的元素类型是Tuple, 调用Array的toMap方法, 可以将Array转换为Map
如,studentScores.toMap
以上是关于Scala学习之路----基础入门的主要内容,如果未能解决你的问题,请参考以下文章