第四十七篇 入门机器学习——分类的准确性(Accuracy)
Posted xuezou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第四十七篇 入门机器学习——分类的准确性(Accuracy)相关的知识,希望对你有一定的参考价值。
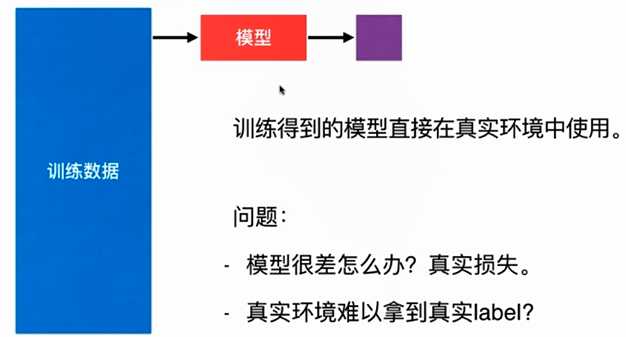
No.1. 通常情况下,直接将训练得到的模型应用于真实环境中,可能会存在很多问题
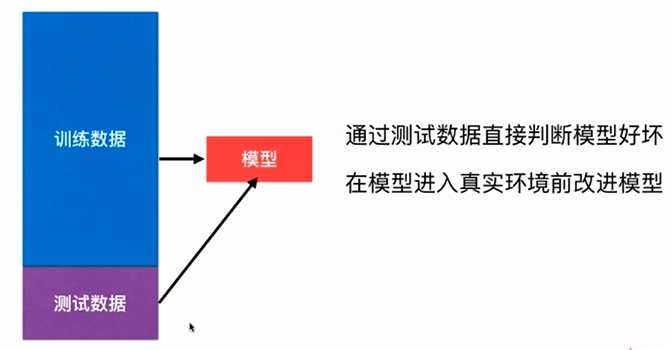
No.2. 比较好的解决方法是,将原始数据中的大部分用于训练数据,而留出少部分数据用于测试,即,将数据集切分成训练数据集和测试数据集两部分,先通过训练数据集得到一个模型,然后通过测试数据集来检验模型的性能是否满足我们的要求,根据测试结果的好坏判断模型是否需要进行改进和优化
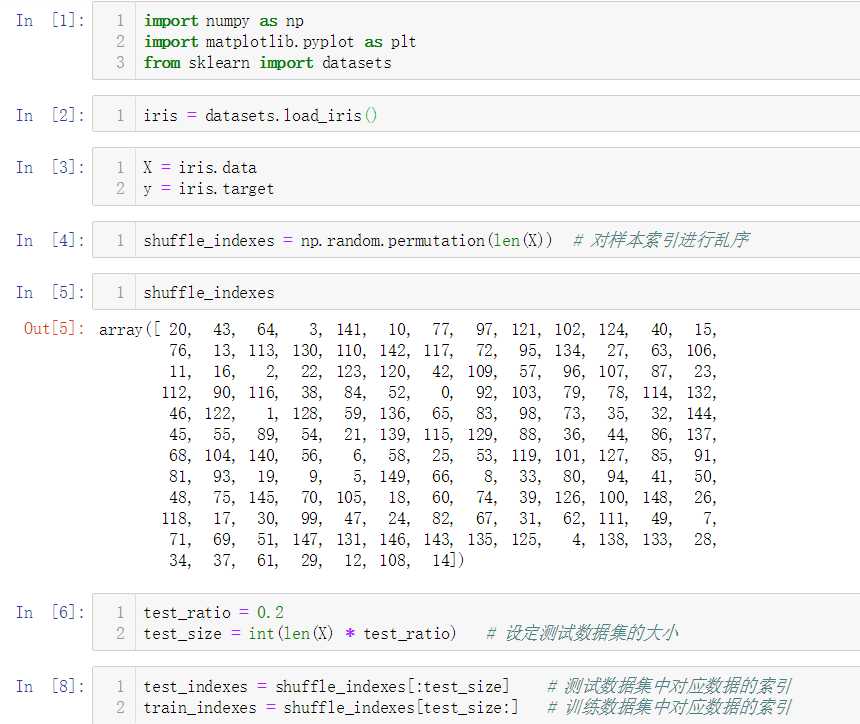
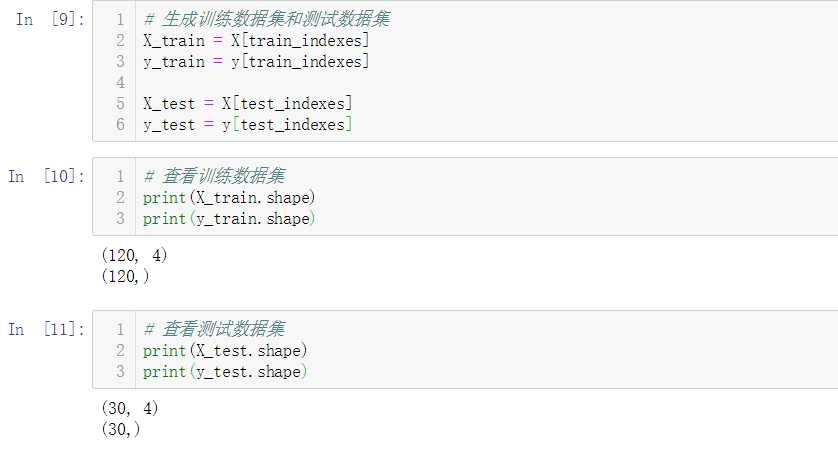
No.3. 我们通过鸢尾花数据集来测试kNN算法的分类准确性,首先是数据准备工作
No.4. 我们可以将上述过程封装到函数中
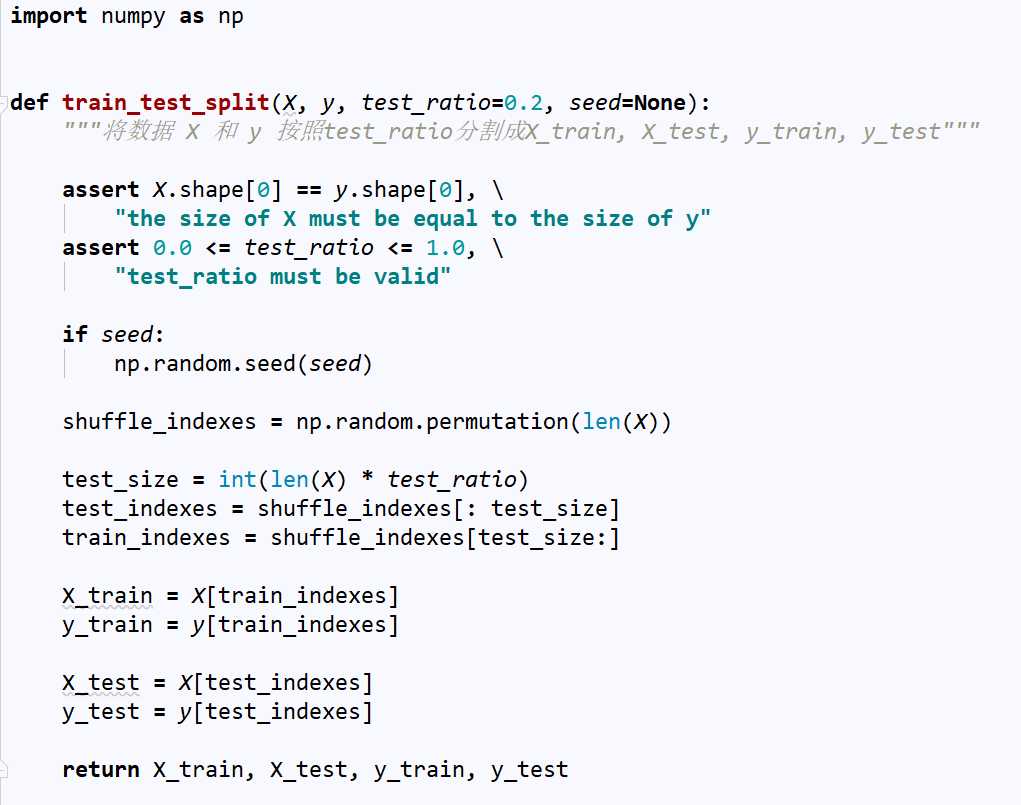
No.5. 调用我们封装的数据集切分函数
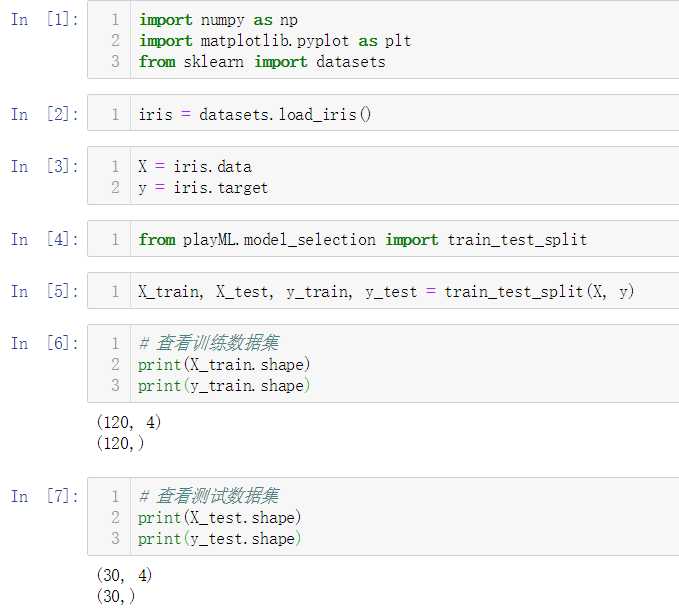
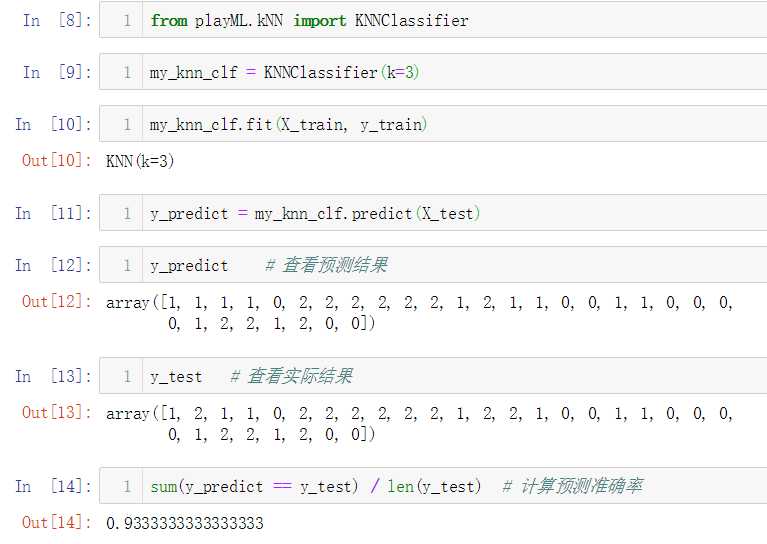
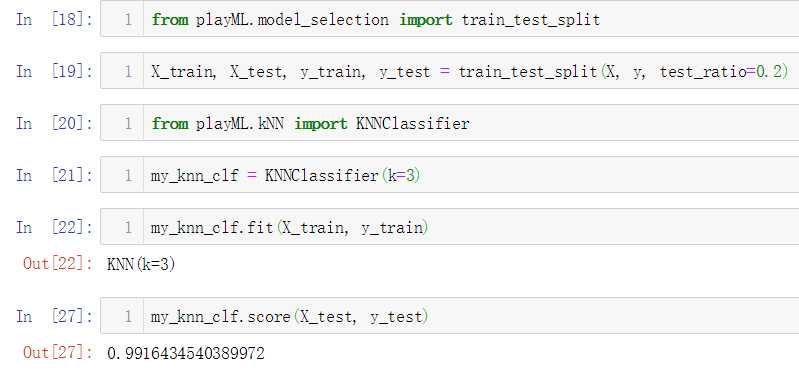
No.6. 调用自己封装的KNNClassifier类,测试其分类准确性
No.9. 查看一下数据集的详细描述信息
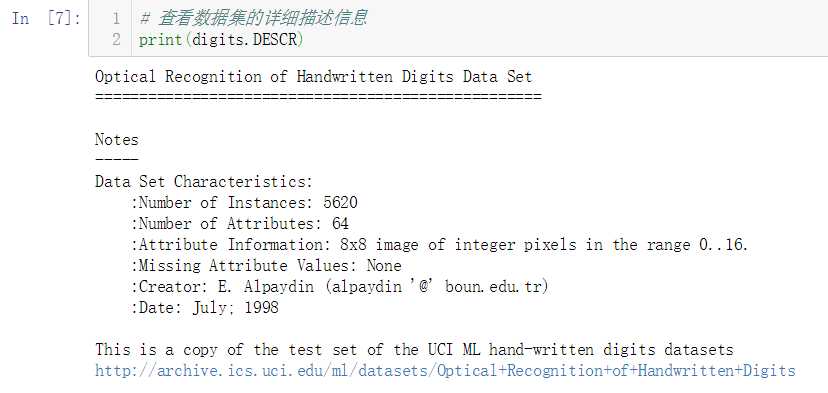
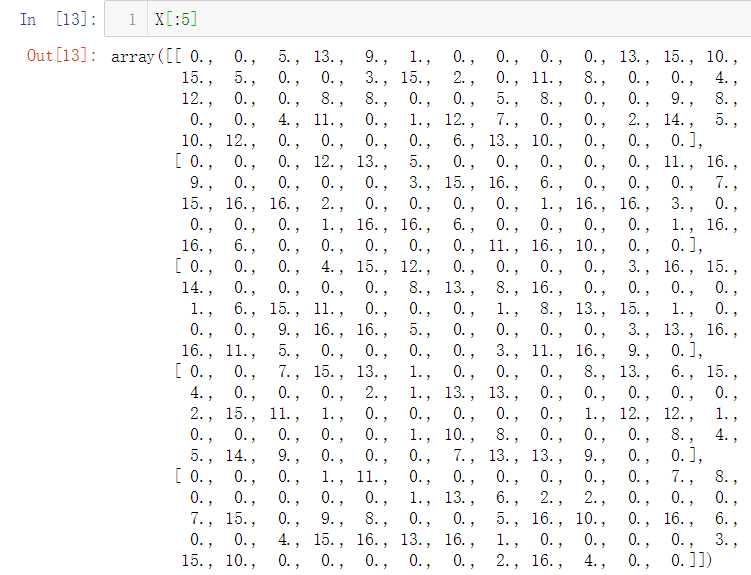
从上面的描述信息中可以了解到,这个数据集共有5620个数据实例,每个实例有64个属性(特征),这64个属性实际组成了8x8像素的图片,每个像素点的取值范围是0-16,这个数据集共分为10个类别,即0-9这10个数字。另外需要注意的一点是,这个数据集只是原数据集的一个简化副本,它实际上只存储了不到2000个数据实例。
No.10. 我们具体查看一下数据集的特征

即,这1797个数据实例都有对应的标签,标签共分为10个类别,分别为0, 1, 2, 3, 4, 5, 6, 7, 8, 9
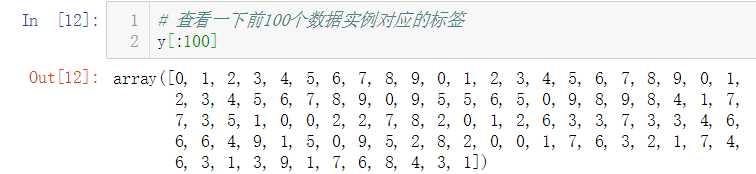
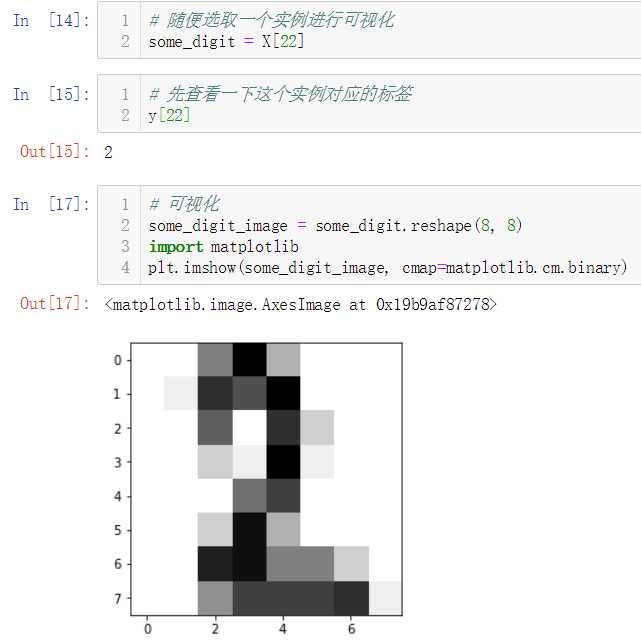
简单查看前100个数据实例对应的标签,发现这些数据并没有按照不同类别分类存放
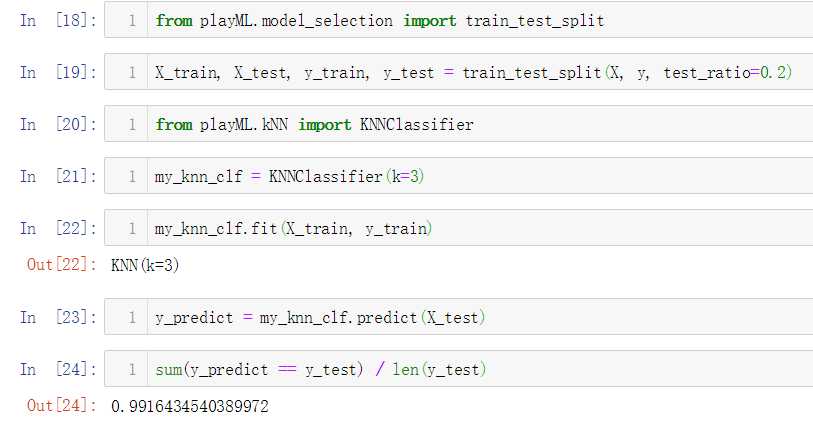
No.11. 调用我们实现的数据切分函数对数据集进行切分,再调用我们是实现的KNNClassifier类,测试其分类准确性
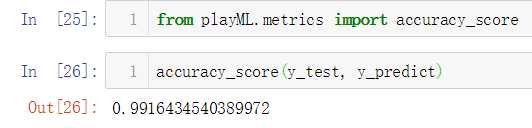
No.12. 上面在测试分类准确性的时候,计算准确性的过程还没有进行封装,我们将其封装如下:

测试一下封装好的函数:
No.13. 某些情况下,我们对预测值具体是什么并不感兴趣,我们可能只想知道我们模型预测结果的准确性,这种情况下,是没有必要手动计算一遍预测值的,我们可以封装一个接口,直接获取到模型预测结果的准确性,在kNNClassifier类中添加一个方法实现这个功能:

测试一下这个接口:
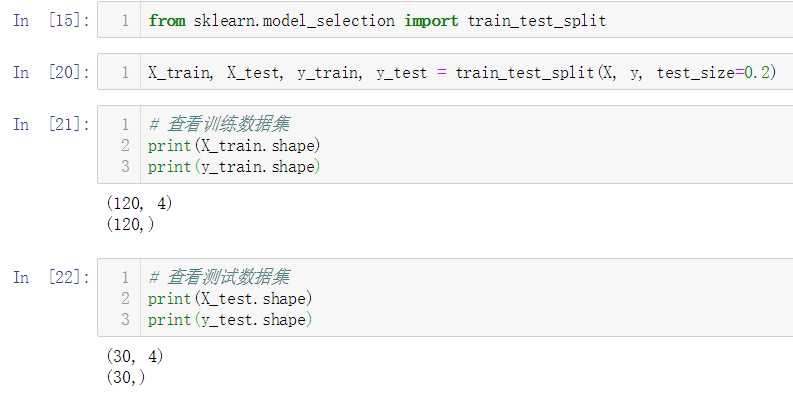
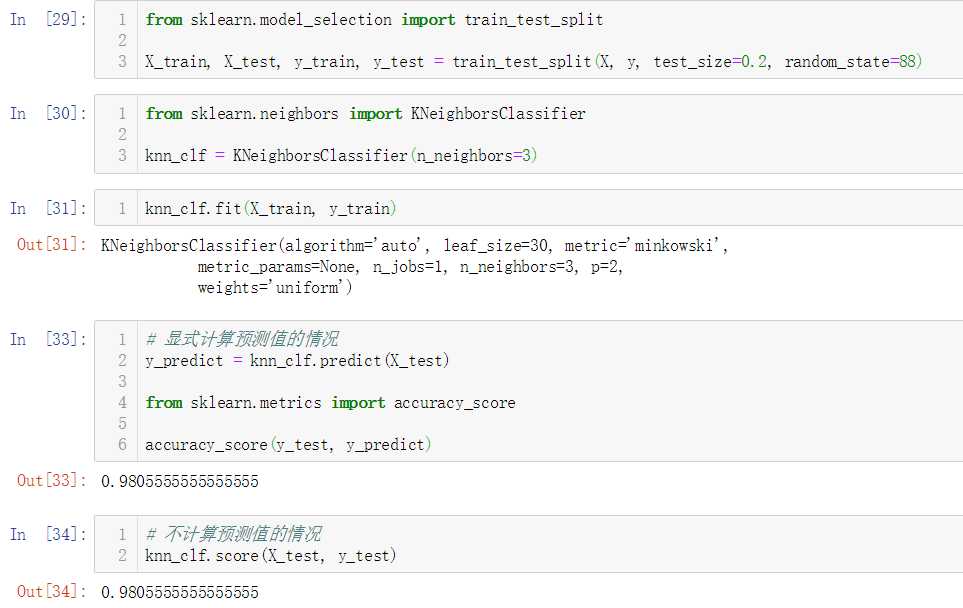
No.14. 调用sklearn提供的数据切分函数对数据集进行切分,再调用sklearn提供的KNeighborsClassifier类,测试其分类准确性
以上是关于第四十七篇 入门机器学习——分类的准确性(Accuracy)的主要内容,如果未能解决你的问题,请参考以下文章