k8s实践
Posted freshmans
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s实践相关的知识,希望对你有一定的参考价值。
内网中k8s的相关配置
kubernetes是以pod而不是docker容器为管理单元的,在k8s创建pod时,还会通过 启动一个名为 google_container/pause的镜像来实现pod的概念,该镜像文件存在谷歌镜像库http://gcr.io中,需要一台能上internet的服务器将其下载并导出,push到私有docker registry中
修改每台node的kubelet服务的启动参数,加上 --pod_infra_container_images参数,指定为私有docker Registry中pause镜像的地址
[[email protected]_node1 ~]# cat /etc/kubernetes/kubelet KUBELET_ARGS="--cluster_dns=10.254.10.2 --pod_infra_container_image=gcr.io/google_containers/pause-amd64:3.0"
#注: --pod_infra_container_image的值根据实际pause的地址进行修改,一版传到内网私有registry上去后直接写内网地址即可
如果以上地址不能用,换成如下
--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0
重启kubelet服务
systemctl restart kubelet
k8s集群网络配置
-
flannel(覆盖网络)
拓扑图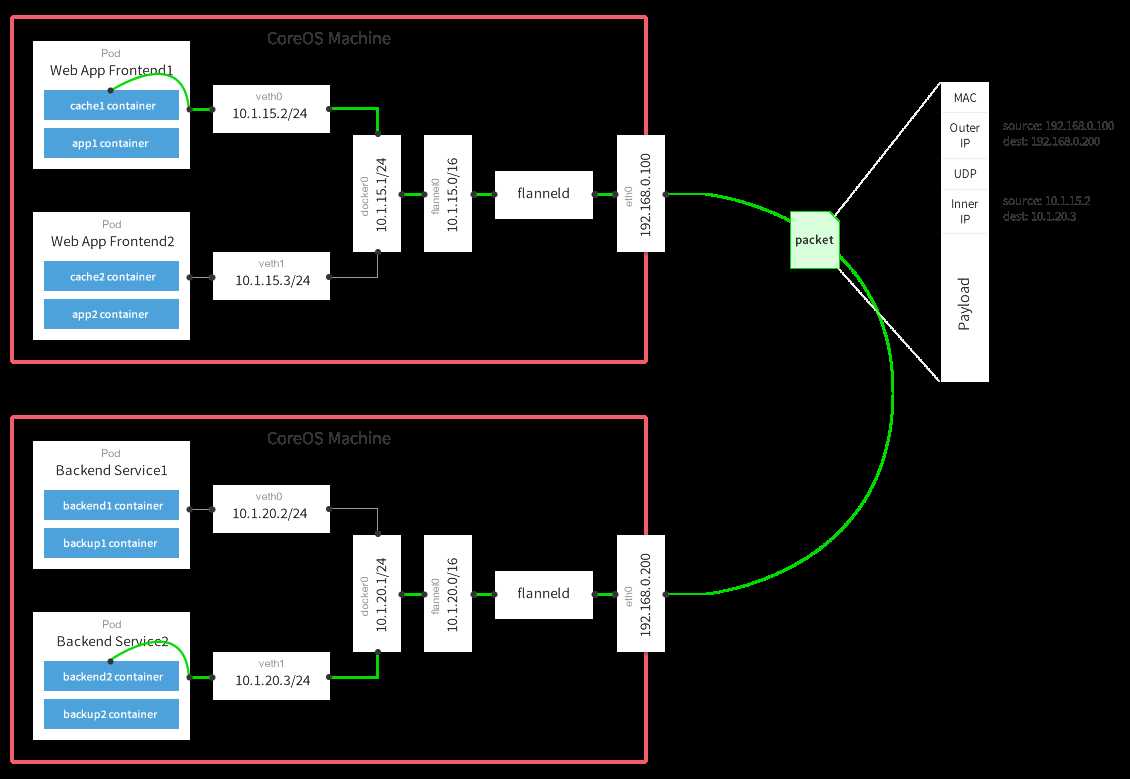
基础原理
#A主机
1、容器直接使用目标容器的ip访问,默认通过容器内部的eth0发送出去。
2、报文通过veth pair被发送到vethXXX。
3、vethXXX是直接连接到虚拟交换机docker0的,报文通过虚拟bridge docker0发送出去。
4、查找路由表,外部容器ip的报文都会转发到flannel0虚拟网卡,这是一个P2P的虚拟网卡,然后报文就被转发到监听在另一端的flanneld。
5、flanneld通过etcd维护了各个节点之间的路由表,把原来的报文UDP封装一层,通过配置的iface发送出去。
6、报文通过主机之间的网络找到目标主机。
##B主机
7、报文继续往上,到传输层,交给监听在8285端口的flanneld程序处理。
8、数据被解包,然后发送给flannel0虚拟网卡。
9、查找路由表,发现对应容器的报文要交给docker0。
10、docker0找到连到自己的容器,把报文发送过去。
flannel采用覆盖网络(overlay Network)模型来完成对网络的打通
①、安装etcd
由于flannel使用etcd作为数据库,所以需要预先安装好etcd,这里略过,看 k8s集群安装有详细步骤
②、安装flannel
需要在每台node上安装flannel,安装方法见 k8s集群安装文档
③、配置flannel
[[email protected]_node2 ~]# systemctl status flanneld #通过这条命令查看flannel的启动文件 ● flanneld.service - Flanneld overlay address etcd agent Loaded: loaded (/usr/lib/systemd/system/flanneld.service; enabled; vendor preset: disabled) Active: active (running) since 二 2018-07-10 18:01:45 CST; 6 days ago Main PID: 50935 (flanneld) Memory: 8.8M CGroup: /system.slice/flanneld.service └─50935 /usr/bin/flanneld -etcd-endpoints=http://192.168.132.148:2379 -etcd-prefix=/atomic.io/network 。。。。。。 [[email protected]_node2 ~]# cat /usr/lib/systemd/system/flanneld.service #查看启动文件。查看加载的配置问津 [Unit] Description=Flanneld overlay address etcd agent After=network.target After=network-online.target Wants=network-online.target After=etcd.service Before=docker.service [Service] Type=notify EnvironmentFile=/etc/sysconfig/flanneld EnvironmentFile=-/etc/sysconfig/docker-network ExecStart=/usr/bin/flanneld-start $FLANNEL_OPTIONS ExecStartPost=/usr/libexec/flannel/mk-docker-opts.sh -k DOCKER_NETWORK_OPTIONS -d /run/flannel/docker Restart=on-failure [Install] WantedBy=multi-user.target RequiredBy=docker.service [[email protected]_node2 ~]# cat /etc/sysconfig/flanneld|grep -v "^#|^$" #查看flannel配置文件 FLANNEL_ETCD_ENDPOINTS="http://192.168.132.148:2379" FLANNEL_ETCD_PREFIX="/atomic.io/network"
master端创建网络(只在master端执行)
etcdctl mk /atomic.io/network/config ‘{"Network": "10.1.0.0/16"}‘ #注意这里的蓝色字体部分要与node flanneld配置文件中的flannel_etcd_prefix名称一样
由于flannel将覆盖docker0网桥,所以如果docker服务已经启动,可尝试将docker服务停止,或者删除docker0网桥,详见 k8s集群安装博客
启动flannel服务
systemctl start flanneld
-
openswitch(虚拟交换机)
拓扑图
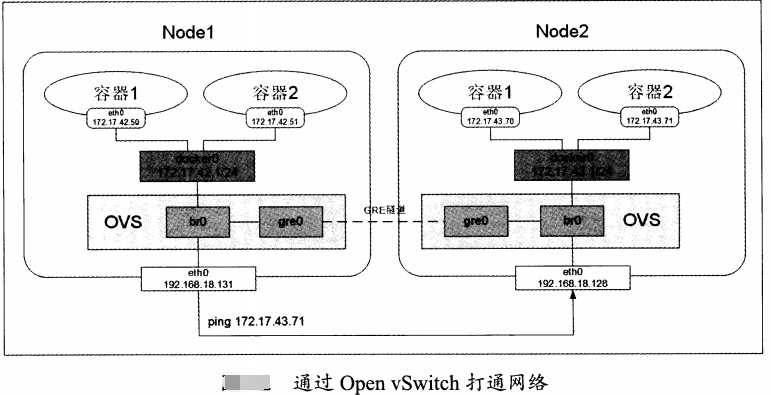
首先配置两个node的docker0网桥地址不同
| 节点名称 | ens33 ip | docker0 ip |
| node1 | 192.168.248.139 | 172.17.42.1 |
| node2 | 192.168.248.140 | 172.17.43.1 |
自定义 设置docker0 ip方法只需修改 daemon.json文件即可
[[email protected] ~]# cat /etc/docker/daemon.json {"bip": "172.17.42.1/24"} [[email protected] ~]# cat /etc/docker/daemon.json {"bip": "172.17.43.1/24"} #重启docker服务 systemctl daemon-reload systemctl restart docker
安装并启动openvswitch
yum install openvswitch
systemctl start openswitch
查看openswitch是否安装成功
#查看进程 service openvswitch stauts #查看相关日志 more /var/log/messages | grep openvswitch
创建网桥和GRE隧道(需要在每个node上建立ovs网桥br0,然后在网桥上创建一个GRE隧道连接对端网桥,最后把ovs网桥br0作为一个端口连接到docker0 这个linux网桥上)
注:node1和node2 操作相同,只是设置点对点ip的时候略有不同
node1 操作 ovs-vsctl add-br br0 #创建ovs网桥 ifconfig #查看有没有新建的br0网桥,如果没有重启openswitch ovs-vsctl add-port br0 gre1 -- set interface gre1 type=gre option:remote_ip=192.168.248.140 #remote为对端物理网卡的ip地址(eth0或ens33或其他) brctl addif docker0 br0 #添加br0到本地 docker0网桥
#启动docker0和br0网桥
ip link set dev br0 up ip link set dev docker0 up ip route add 172.17.0.0/16 dev docker0 #添加到主机的路由 node2 操作 ovs-vsctl add-br br0 ifconfig #查看有没有新建的br0网桥,如果没有重启 openswich ovs-vsctl add-port br0 gre1 -- set interface gre1 type=gre option:remote_ip=192.168.248.139 brctl addif docker0 br0 ip link set dev br0 up ip link set dev docker0 up ip route add 172.17.0.0/16 dev docker0
注:如果有多个node,需要建立n*(n-1)条 GRE隧道,组成一个网格结构
查看添加情况并测试
[[email protected] ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:b0:88:b7 brd ff:ff:ff:ff:ff:ff inet 192.168.248.139/24 brd 192.168.248.255 scope global ens33 valid_lft forever preferred_lft forever inet6 fe80::e1d4:5d25:cb99:2fea/64 scope link valid_lft forever preferred_lft forever 3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP link/ether 02:42:d1:b3:15:a9 brd ff:ff:ff:ff:ff:ff inet 172.17.42.1/24 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:d1ff:feb3:15a9/64 scope link valid_lft forever preferred_lft forever 4: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000 link/ether ce:74:4c:34:b3:f9 brd ff:ff:ff:ff:ff:ff 5: br0: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UNKNOWN qlen 1000 link/ether 3a:fe:f3:1c:26:40 brd ff:ff:ff:ff:ff:ff inet6 fe80::dcc0:48ff:fed0:85f4/64 scope link valid_lft forever preferred_lft forever 6: [email protected]: <NOARP> mtu 1476 qdisc noop state DOWN qlen 1 link/gre 0.0.0.0 brd 0.0.0.0 7: [email protected]: <BROADCAST,MULTICAST> mtu 1462 qdisc noop state DOWN qlen 1000 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff 8: [email protected]: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65490 qdisc pfifo_fast master ovs-system state UNKNOWN qlen 1000 link/ether 4e:3b:c4:9c:31:79 brd ff:ff:ff:ff:ff:ff inet6 fe80::4c3b:c4ff:fe9c:3179/64 scope link valid_lft forever preferred_lft forever [[email protected] log]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:f3:1b:1c brd ff:ff:ff:ff:ff:ff inet 192.168.248.140/24 brd 192.168.248.255 scope global ens33 valid_lft forever preferred_lft forever inet6 fe80::2199:b4c3:7d80:32c1/64 scope link valid_lft forever preferred_lft forever 3: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP link/ether 02:42:7e:c0:fc:bf brd ff:ff:ff:ff:ff:ff inet 172.17.43.1/24 scope global docker0 valid_lft forever preferred_lft forever inet6 fe80::42:7eff:fec0:fcbf/64 scope link valid_lft forever preferred_lft forever 4: ovs-system: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN qlen 1000 link/ether b2:5a:cb:e5:e3:7a brd ff:ff:ff:ff:ff:ff 5: br0: <BROADCAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UNKNOWN qlen 1000 link/ether 36:f2:10:c9:48:45 brd ff:ff:ff:ff:ff:ff inet6 fe80::6810:75ff:feab:ca2f/64 scope link valid_lft forever preferred_lft forever 6: [email protected]: <NOARP> mtu 1476 qdisc noop state DOWN qlen 1 link/gre 0.0.0.0 brd 0.0.0.0 7: [email protected]: <BROADCAST,MULTICAST> mtu 1462 qdisc noop state DOWN qlen 1000 link/ether 00:00:00:00:00:00 brd ff:ff:ff:ff:ff:ff 8: [email protected]: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 65490 qdisc pfifo_fast master ovs-system state UNKNOWN qlen 1000 link/ether 12:07:43:72:34:d4 brd ff:ff:ff:ff:ff:ff inet6 fe80::1007:43ff:fe72:34d4/64 scope link valid_lft forever preferred_lft forever 测试,在node上ping 另一个node的 docker0网桥 [[email protected] ~]# ping 172.17.43.1 PING 172.17.43.1 (172.17.43.1) 56(84) bytes of data. 64 bytes from 172.17.43.1: icmp_seq=1 ttl=64 time=0.960 ms 64 bytes from 172.17.43.1: icmp_seq=2 ttl=64 time=15.9 ms [[email protected] log]# ping 172.17.42.1 PING 172.17.42.1 (172.17.42.1) 56(84) bytes of data. 64 bytes from 172.17.42.1: icmp_seq=1 ttl=64 time=2.34 ms 64 bytes from 172.17.42.1: icmp_seq=2 ttl=64 time=0.385 ms
-
直接路由
使用直接路由的方式,只要在每个node上的路由表中添加到对方docker0的静态路由转发规则
例
如: pod1所在 docker0 网桥的ip子网是 10.1.10.0,node地址为 192.168.132.131;pod2所在docker0网桥的ip子网为 10.1.20.0,node地址为 192.168.132.132 #node1上添加一条道node2的路由 route add -net 10.1.20.0(node2-docker0-IP) netmask 255.255.255.0 gw 192.168.132.132(node2-eth0-IP) #node2上添加一条道node1的路由 route add -net 10.1.10.0(node1-docker0-IP) netmask 255.255.255.0 gw 192.168.132.131(node1-eth0-IP)
-
calico
拓扑图
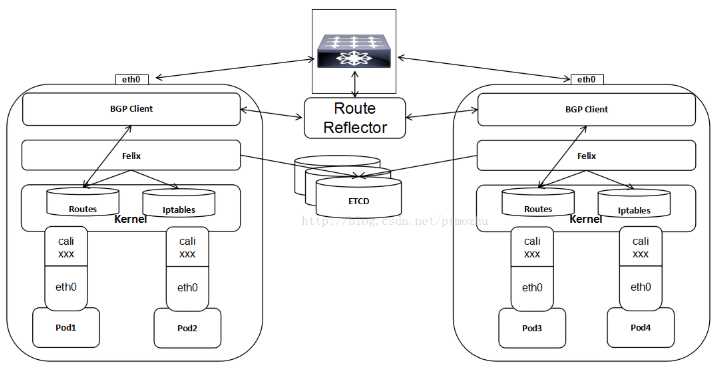
核心组件说明
Calico的核心组件包括:Felix、etcd、BIRD、BIRD。
Felix,即Calicoagent,跑在kubernetes的node节点上,主要负责配置路由及ACLs等信息来确保endpoint的连通状态;
etcd,分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
BGPClient(BIRD), 主要负责把 Felix写入 kernel的路由信息分发到当前 Calico网络,确保 workload(虚拟机、容器、pod等)间的通信的有效性;worklaod之间数据传输无需封包解包
BGPRoute Reflector(BIRD), 大规模部署时使用,摒弃所有节点互联的mesh模式,通过一个或者多个 BGPRoute Reflector 来完成集中式的路由分发;
#说明:
Calico在每一个计算节点利用linux kernel实现了一个高效的vRouter来负责数据转发,每个vRouter通过BGP协议负责把自己上运行的workload的路由信息负责在整个Calico网络内组播
通过基于iptables的ACLs来提供多租户的隔离
kubectl 语法
详见 k8s命令使用博客
以上是关于k8s实践的主要内容,如果未能解决你的问题,请参考以下文章