Spring为何需要三级缓存解决循环依赖,而不是二级缓存?
Posted androidstarjack
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring为何需要三级缓存解决循环依赖,而不是二级缓存?相关的知识,希望对你有一定的参考价值。
点击上方关注 “终端研发部”
设为“星标”,和你一起掌握更多数据库知识
文章来源:http://u6.gg/k53gg
在使用 Spring 框架的日常开发中,bean 之间的循环依赖太频繁了,Spring 已经帮我们去解决循环依赖问题,对我们开发者来说是无感知的。
下面具体分析一下 Spring 是如何解决 bean 之间循环依赖,为什么要使用到三级缓存,而不是二级缓存。
bean 生命周期
首先大家需要了解一下 bean 在 spring 中的生命周期,bean 在 Spring 的加载流程,才能够更加清晰知道 Spring 是如何解决循环依赖的。
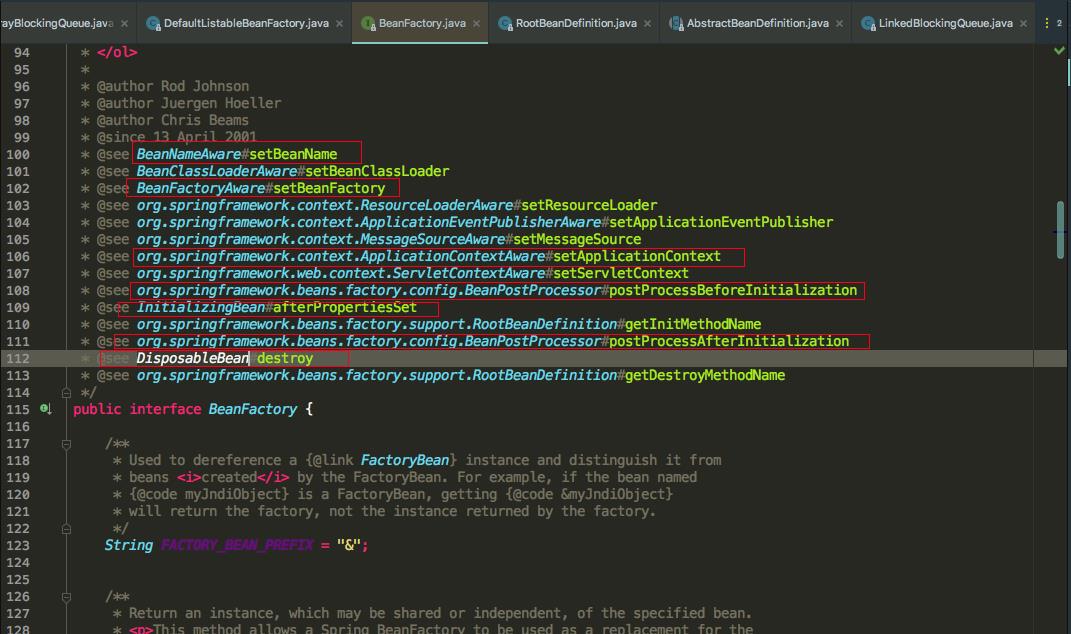
我们在 Spring 的 BeanFactory 工厂列举了很多接口,代表着 bean 的生命周期,我们主要记住的是我圈红线圈出来的接口,再结合 Spring 的源码来看这些接口主要是在哪里调用的。
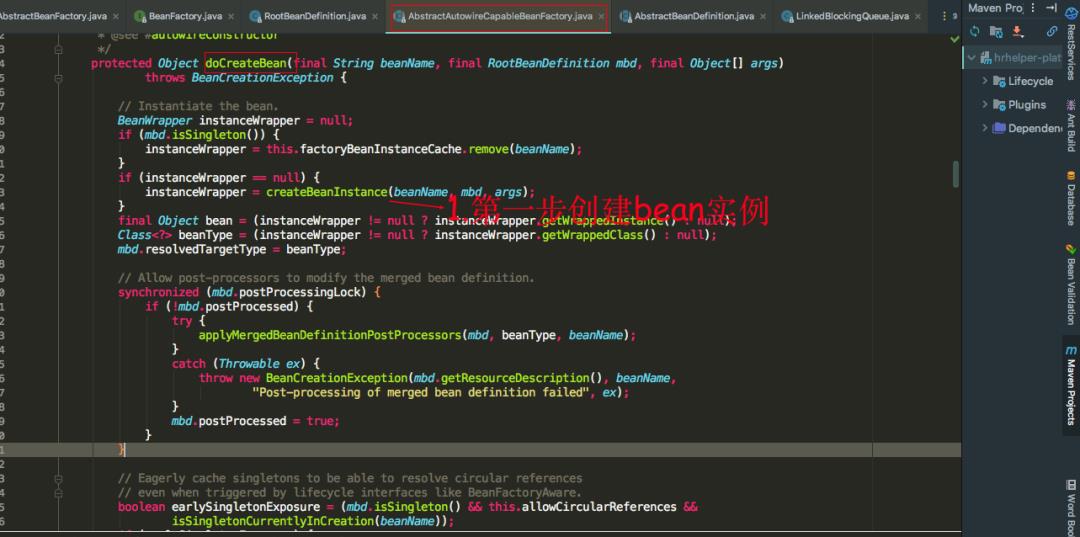
AbstractAutowireCapableBeanFactory 类的 doCreateBean 方法是创建 bean 的开始,我们可以看到首先需要实例化这个 bean,也就是在堆中开辟一块内存空间给这个对象。
createBeanInstance 方法里面逻辑大概就是采用反射生成实例对象,进行到这里表示对象还并未进行属性的填充,也就是 @Autowired 注解的属性还未得到注入。
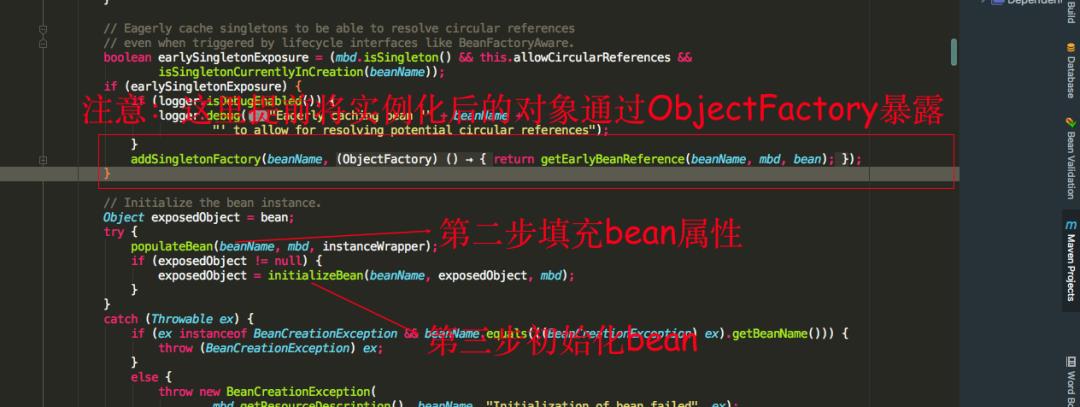
我们可以看到第二步就是填充 bean 的成员属性,populateBean 方法里面的逻辑大致就是对使用到了注入属性的注解就会进行注入。
如果在注入的过程发现注入的对象还没生成,则会跑去生产要注入的对象,第三步就是调用 initializeBean 方法初始化 bean,也就是调用我们上述所提到的接口。
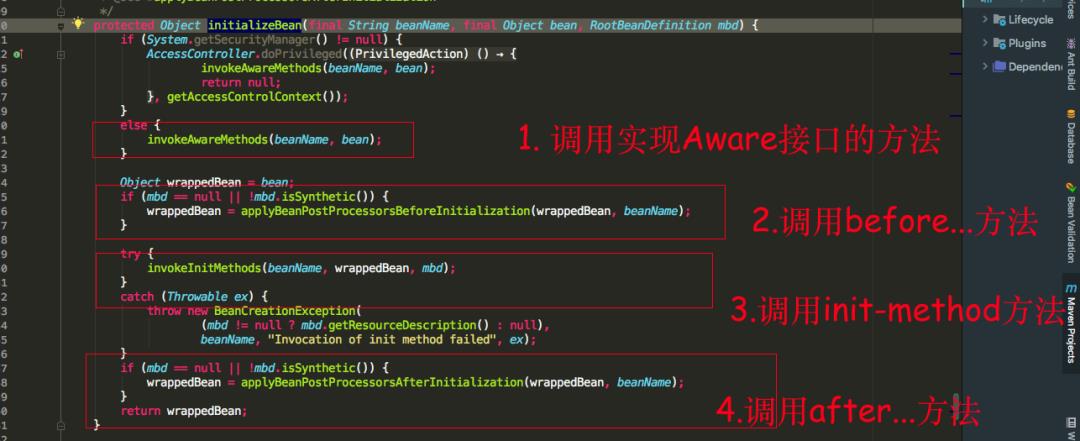
可以看到 initializeBean 方法中,首先调用的是使用的 Aware 接口的方法,我们具体看一下 invokeAwareMethods 方法中会调用 Aware 接口的那些方法。
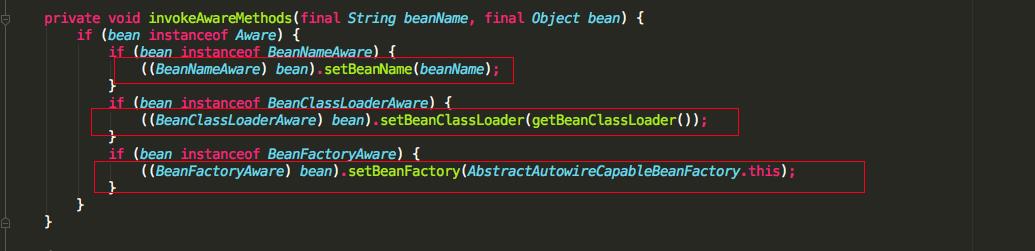
我们可以知道如果我们实现了 BeanNameAware,BeanClassLoaderAware,BeanFactoryAware 三个 Aware 接口的话。
会依次调用 setBeanName(), setBeanClassLoader(),setBeanFactory() 方法,再看 applyBeanPostProcessorsBeforeInitialization 源码。
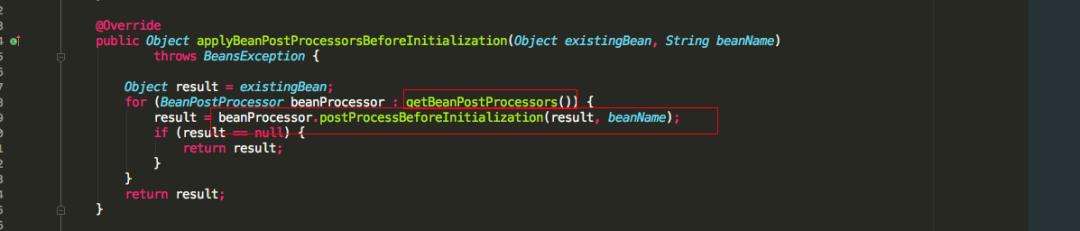
发现会如果有类实现了 BeanPostProcessor 接口,就会执行 postProcessBeforeInitialization 方法。
这里需要注意的是:如果多个类实现 BeanPostProcessor 接口,那么多个实现类都会执行 postProcessBeforeInitialization 方法,可以看到是 for 循环依次执行的。
还有一个注意的点就是如果加载 A 类到 Spring 容器中,A 类也重写了 BeanPostProcessor 接口的 postProcessBeforeInitialization 方法。
这时要注意 A 类的 postProcessBeforeInitialization 方法并不会得到执行,因为 A 类还未加载完成,还未完全放到 Spring 的 singletonObjects 一级缓存中。
再看一个注意的点:
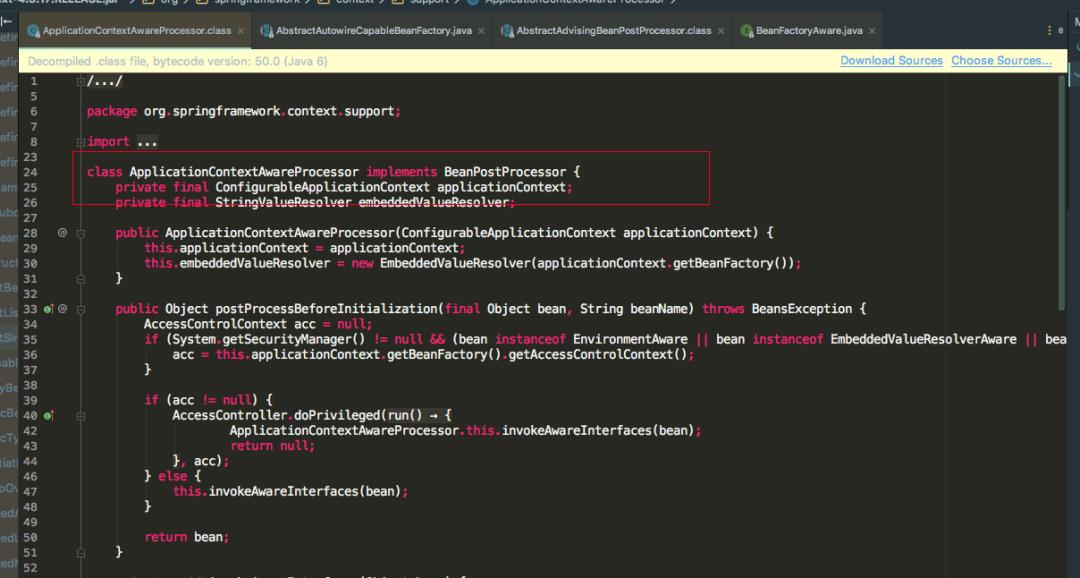
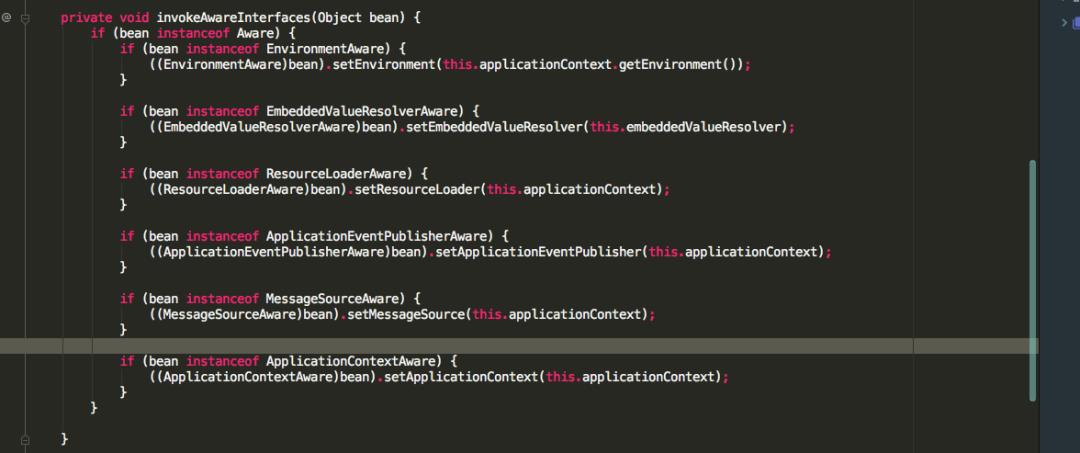
可以看到 ApplicationContextAwareProcessor 也实现了 BeanPostProcessor 接口,重写了 postProcessBeforeInitialization 方法,方法里面并调用了 invokeAwareInterfaces 方法。
而 invokeAwareInterfaces 方法也写着如果实现了众多的 Aware 接口,则会依次执行相应的方法。
值得注意的是 ApplicationContextAware 接口的 setApplicationContext 方法。
再看一下 invokeInitMethods 源码:
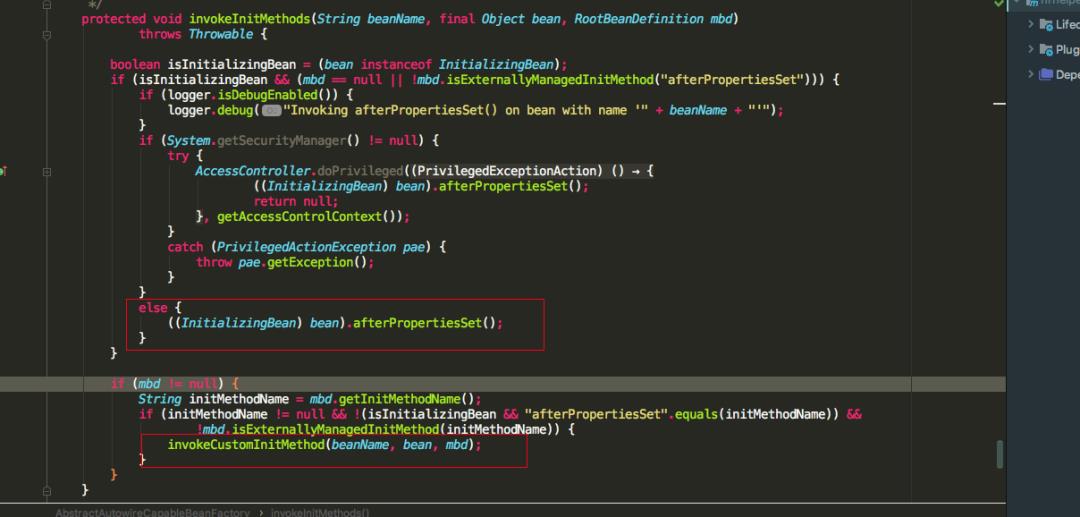
发现如果实现了 InitializingBean 接口,重写了 afterPropertiesSet 方法,则会调用 afterPropertiesSet 方法,最后还会调用是否指定了 init-method,可以通过标签,或者 @Bean 注解的 initMethod 指定。
最后再看一张 applyBeanPostProcessorsAfterInitialization 源码图:
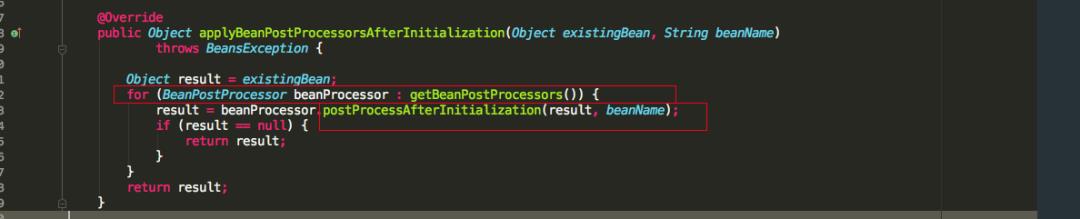
发现跟之前的 postProcessBeforeInitialization 方法类似,也是循环遍历实现了 BeanPostProcessor 的接口实现类,执行 postProcessAfterInitialization 方法。
整个 bean 的生命执行流程就如上面截图所示,哪个接口的方法在哪里被调用,方法的执行流程。
最后,对 bean 的生命流程进行一个流程图的总结:
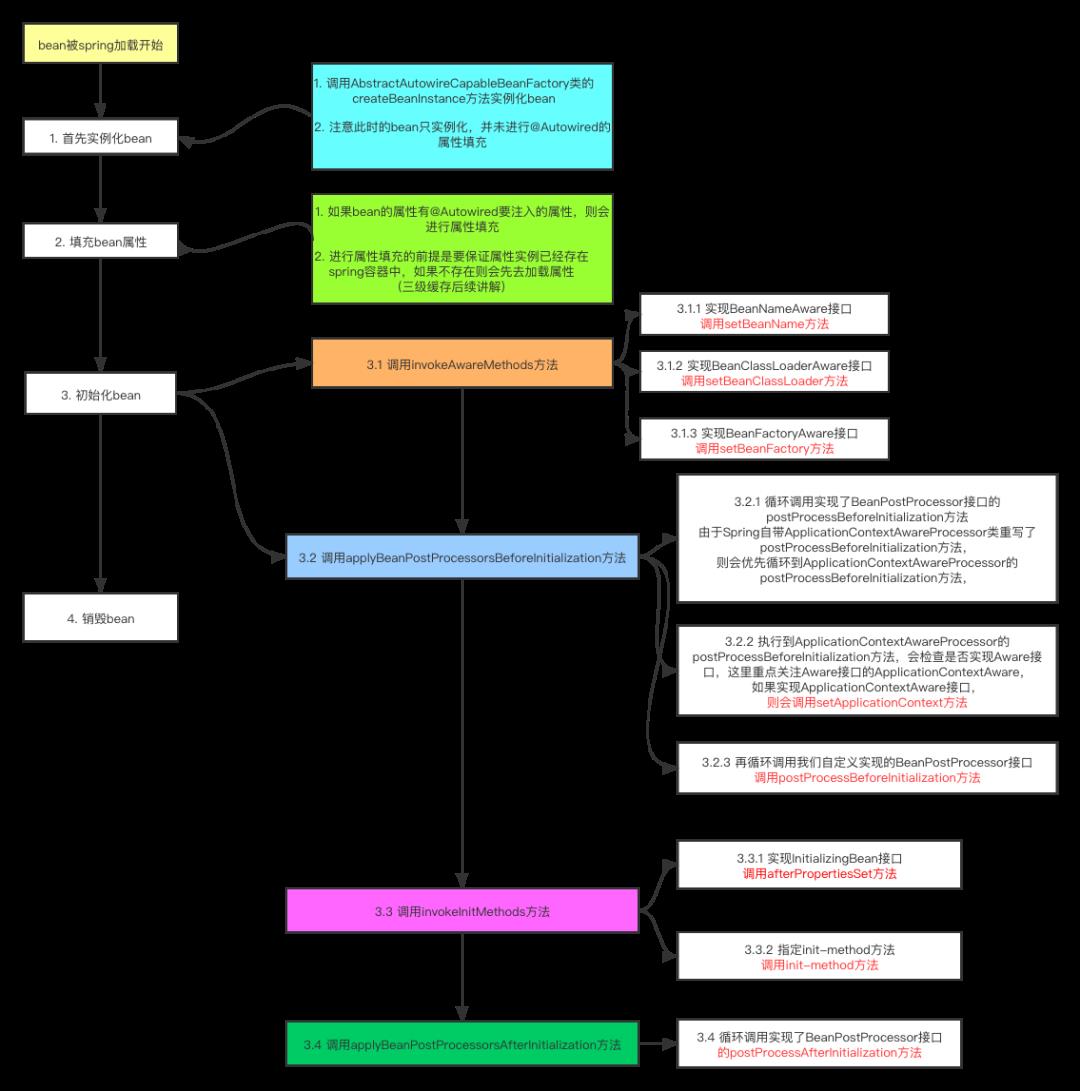
三级缓存解决循环依赖
上一小节对 bean 的生命周期做了一个整体的流程分析,对 Spring 如何去解决循环依赖的很有帮助。
前面我们分析到填充属性时,如果发现属性还未在 Spring 中生成,则会跑去生成属性对象实例。

我们可以看到填充属性的时候,Spring 会提前将已经实例化的 bean 通过 ObjectFactory 半成品暴露出去。
为什么称为半成品是因为这时候的 bean 对象实例化,但是未进行属性填充,是一个不完整的 bean 实例对象。
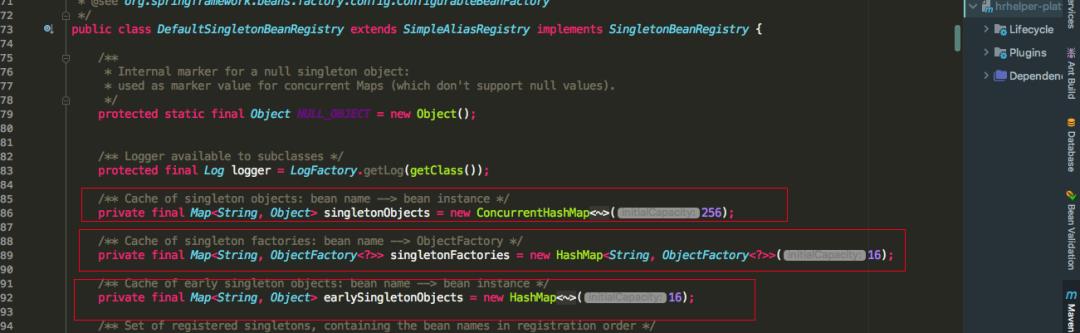
Spring 利用 singletonObjects,earlySingletonObjects,singletonFactories 三级缓存去解决的,所说的缓存其实也就是三个 Map。
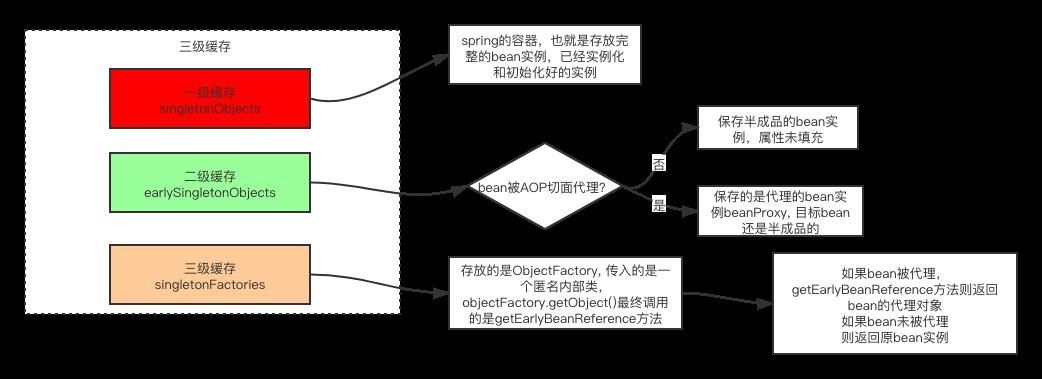
可以看到三级缓存各自保存的对象,这里重点关注二级缓存 earlySingletonObjects 和三级缓存 singletonFactory,一级缓存可以进行忽略。
前面我们讲过先实例化的 bean 会通过 ObjectFactory 半成品提前暴露在三级缓存中。
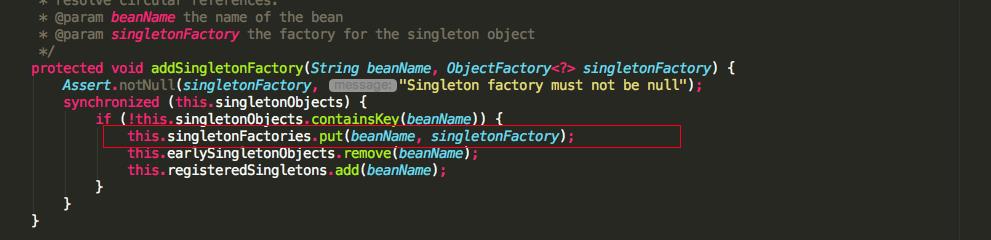
singletonFactory 是传入的一个匿名内部类,调用 ObjectFactory.getObject() 最终会调用 getEarlyBeanReference 方法。再来看看循环依赖中是怎么拿其它半成品的实例对象的。
我们假设现在有这样的场景 AService 依赖 BService,BService 依赖 AService:
AService 首先实例化,实例化通过 ObjectFactory 半成品暴露在三级缓存中
填充属性 BService,发现 BService 还未进行过加载,就会先去加载 BService
再加载 BService 的过程中,实例化,也通过 ObjectFactory 半成品暴露在三级缓存
填充属性 AService 的时候,这时候能够从三级缓存中拿到半成品的 ObjectFactory

拿到 ObjectFactory 对象后,调用 ObjectFactory.getObject() 方法最终会调用 getEarlyBeanReference() 方法。
getEarlyBeanReference 这个方法主要逻辑大概描述下如果 bean 被 AOP 切面代理则返回的是 beanProxy 对象,如果未被代理则返回的是原 bean 实例。
这时我们会发现能够拿到 bean 实例(属性未填充),然后从三级缓存移除,放到二级缓存 earlySingletonObjects 中,而此时 B 注入的是一个半成品的实例 A 对象。
不过随着 B 初始化完成后,A 会继续进行后续的初始化操作,最终 B 会注入的是一个完整的 A 实例,因为在内存中它们是同一个对象。
下面是重点,我们发现这个二级缓存好像显得有点多余,好像可以去掉,只需要一级和三级缓存也可以做到解决循环依赖的问题???
只要两个缓存确实可以做到解决循环依赖的问题,但是有一个前提这个 bean 没被 AOP 进行切面代理,如果这个 bean 被 AOP 进行了切面代理,那么只使用两个缓存是无法解决问题。
下面来看一下 bean 被 AOP 进行了切面代理的场景:4
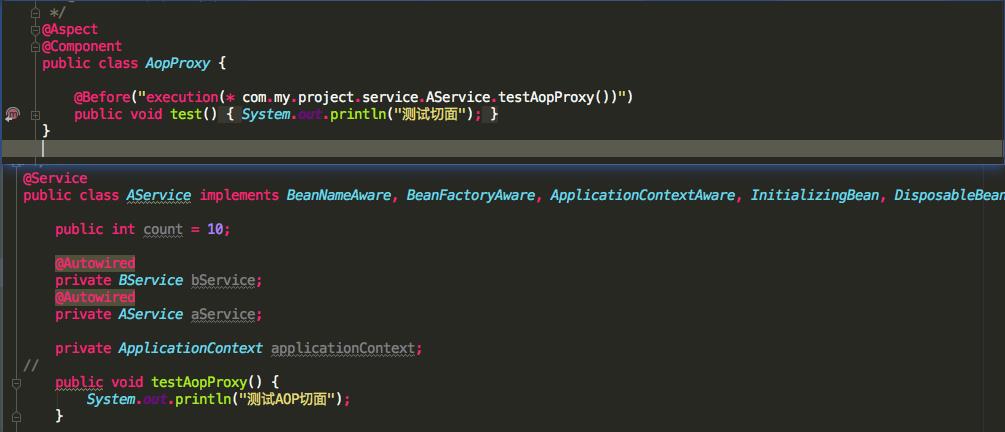
我们发现 AService 的 testAopProxy 被 AOP 代理了,看看传入的匿名内部类的 getEarlyBeanReference 返回的是什么对象。
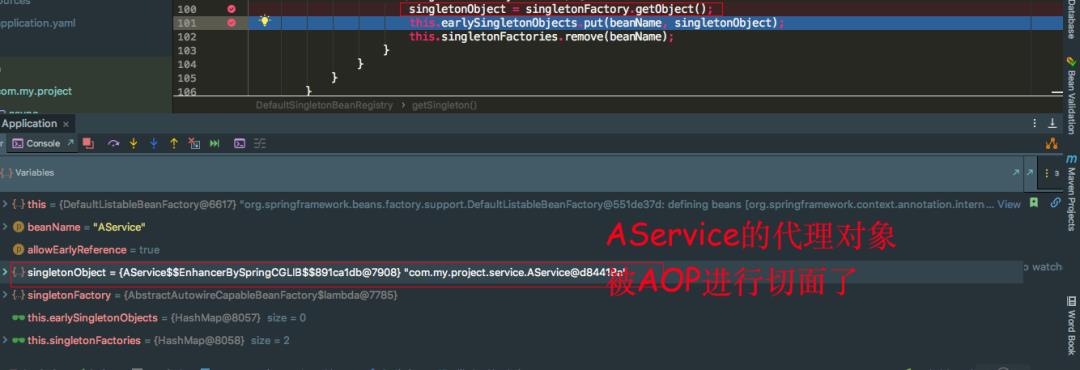
发现 singletonFactory.getObject() 返回的是一个 AService 的代理对象,还是被 CGLIB 代理的。
再看一张再执行一遍 singletonFactory.getObject() 返回的是否是同一个 AService 的代理对象。
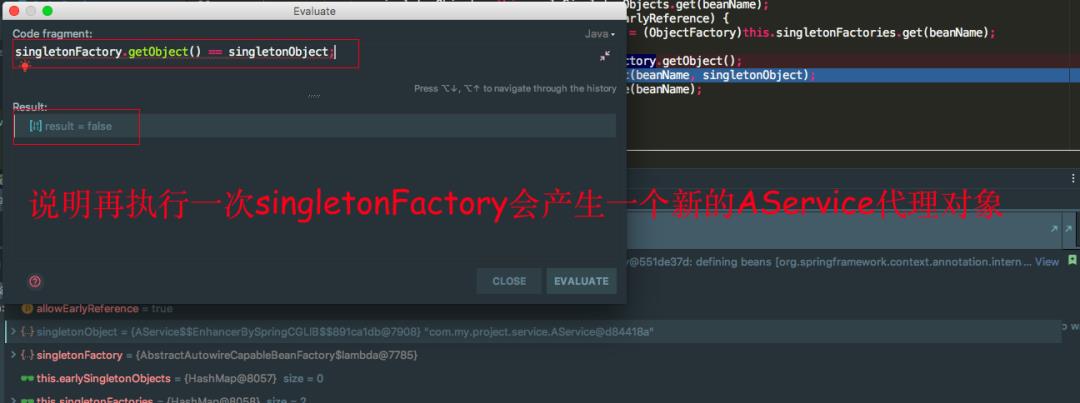
我们会发现再执行一遍 singleFactory.getObject() 方法又是一个新的代理对象,这就会有问题了,因为 AService 是单例的,每次执行 singleFactory.getObject() 方法又会产生新的代理对象。
假设这里只有一级和三级缓存的话,我每次从三级缓存中拿到 singleFactory 对象,执行 getObject() 方法又会产生新的代理对象。
这是不行的,因为 AService 是单例的,所有这里我们要借助二级缓存来解决这个问题。
将执行了 singleFactory.getObject() 产生的对象放到二级缓存中去,后面去二级缓存中拿,没必要再执行一遍 singletonFactory.getObject() 方法再产生一个新的代理对象,保证始终只有一个代理对象。
还有一个注意的点:
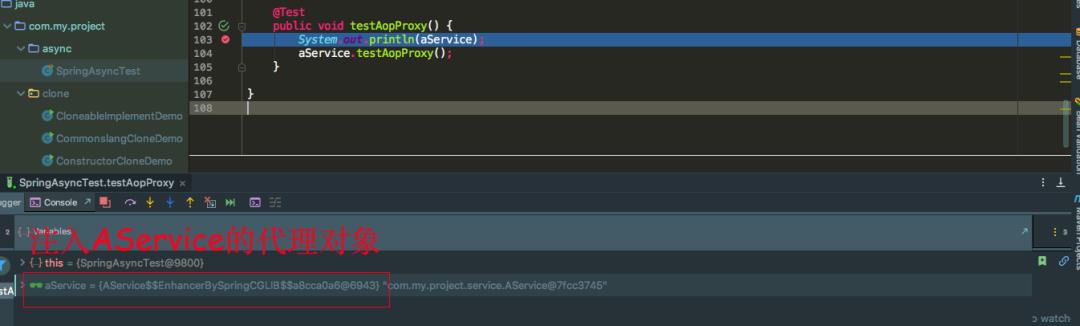
既然 singleFactory.getObject() 返回的是代理对象,那么注入的也应该是代理对象,我们可以看到注入的确实是经过 CGLIB 代理的 AService 对象。
所以如果没有 AOP 的话确实可以两级缓存就可以解决循环依赖的问题,如果加上 AOP,两级缓存是无法解决的,不可能每次执行 singleFactory.getObject() 方法都给我产生一个新的代理对象,所以还要借助另外一个缓存来保存产生的代理对象。
总结
前面先讲到 bean 的加载流程,了解了 bean 加载流程对 Spring 如何解决循环依赖的问题很有帮助,后面再分析到 Spring 为什么需要利用到三级缓存解决循环依赖问题,而不是二级缓存。
网上可以试试 AOP 的情形,实践一下就能明白二级缓存为什么解决不了 AOP 代理的场景了。
在工作中,一直认为编程代码不是最重要的,重要的是在工作中所养成的编程思维。
写在最后的话
大家看完有什么不懂的可以在下方留言讨论,也可以私信问我一般看到后我都会回复的。最后觉得文章对你有帮助的话记得点个赞哦,点点关注不迷路
@终端研发部
每天都有新鲜的干货分享!
回复 【idea激活】即可获得idea的激活方式
回复 【Java】获取java相关的视频教程和资料
回复 【SpringCloud】获取SpringCloud相关多的学习资料
回复 【python】获取全套0基础Python知识手册
回复 【2020】获取2020java相关面试题教程
回复 【加群】即可加入终端研发部相关的技术交流群
阅读更多
用 Spring 的 BeanUtils 前,建议你先了解这几个坑!
lazy-mock ,一个生成后端模拟数据的懒人工具
在华为鸿蒙 OS 上尝鲜,我的第一个“hello world”,起飞!
字节跳动一面:i++ 是线程安全的吗?
一条 SQL 引发的事故,同事直接被开除!!
太扎心!排查阿里云 ECS 的 CPU 居然达100%
一款vue编写的功能强大的swagger-ui,有点秀(附开源地址)
相信自己,没有做不到的,只有想不到的在这里获得的不仅仅是技术!
喜欢就给个“在看”以上是关于Spring为何需要三级缓存解决循环依赖,而不是二级缓存?的主要内容,如果未能解决你的问题,请参考以下文章