机器学习Hands On Lab
Posted xiashiwendao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习Hands On Lab相关的知识,希望对你有一定的参考价值。
fetch_data
fetch_mldata默认路径是在scikit_learn_data路径下,mnist的mat文件其实直接放置到scikit_lean/mldata下面即可通过fetch_mldata中获取;当然路径信息其实是fetch_home函数中定义的;
洗牌训练数据
为了避免数据的有序对于训练的影响,有的时候需要对于数据进行随机排列;比如对于7万个手写数字的样本,前60000个做训练集,这6万个需要通过np.random.permutation(60000)来进行随机重排,也成为洗牌(shuffle)。但是这种洗牌主要用于样本本身不具备顺序性;但是对于一些样本之间具有关联系,比如具有时间排序联系(股票,天气)则尽量避免洗牌操作,因为训练的本身就是具有训练时序性。
唉,在做手写体测试的时候,每次执行从洗牌到训练到验证(sdg_clf.predict([some_digit]))的时候发现经常执行结果不一样,有的时候能够识别some_digit为5,有的则识别不出来。
scores和predict的差别
注意模型的scores和predict的差别,前者其实是对于样本可能是某个值的一种可能值;后者则是直接根据X预测y,在分类算法里面,predict返回的就是分类类别,里面本质上是计算某个用例在各个分类中的概率,选择概率最大的那个;
用decision_function来代替predict,前者返回的内容scores;scores现在我的理解是对于二元/多元计分,通常是根据分值最大的那个分类作为predict的返回值(所以predict在内部实现是是先调用decision_function,然后再自行判断类别),所谓分值的阈值也是判断是否的分割线;那么对于多分类的处理是怎样的呢?
>>> cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")
其中分值(scoring)的种类如下表所示:
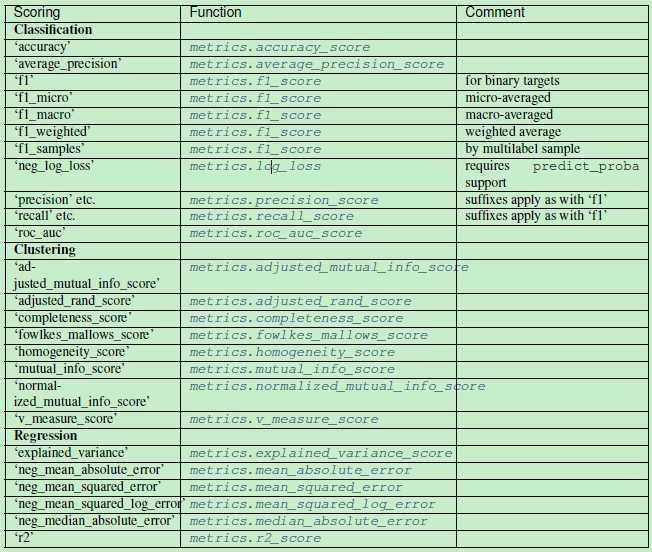
参考:
http://scikit-learn.org/stable/modules/model_evaluation.html
ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42))
这个random_state是做什么的?一个算法只要指定了random_state,就可以保证每次产生的随机数都是一致的,可以保证多次运行产生的模型一致;很多时候是测试阶段为了获取稳定测试效果会如此处理;在生产环境很多场景是需要随记的;主要还是看应用场景,是否需要random_state。
以上是关于机器学习Hands On Lab的主要内容,如果未能解决你的问题,请参考以下文章