线程间通信与协作方式之——volatile关键字
Posted smartchen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了线程间通信与协作方式之——volatile关键字相关的知识,希望对你有一定的参考价值。
上两篇文章我向大家介绍了一些线程间的基本通信方式,那么这篇文章就和大家聊聊volatile关键字的相关知识。这个关键字在我们的日常开发中很少会使用到,而在JDK的Lock包和Concurrent包下的类则大量的使用了这个关键字,因为它有如下两个特性:
1.确保内存可见性 2.禁止指令重排序
接下来就针对这两点特性来进行分析,我会尽量用最能够被理解的语言去阐述相关知识点。
什么是可见性
在多线程环境中一定会出现这种情况:多个线程需要访问主内存地址中的同一个数据。假如没有volatile关键字,那么线程A在对该数据做出修改后,紧接着线程B马上就读取该数据,此时线程A和线程B中的数据已经是不同的了(线程B读取到的还是原先未被线程A修改的数据),导致后续的操作得到的结果可能和想象中的结果不同。这种情况当然是需要去避免发生的,而volatile关键字在这里就能解决这个问题:如果被访问的数据使用了volatile关键字修饰,那么当某个线程修改完该数据后,必定需要先将这个最新修改的值写回主内存中,从而保证下一个读取该变量的线程取得的就是主内存中该数据最新的值。
我们从CPU层面看一下是如何支持volatile确保内存可见性这个特性的:
现在大家电脑的处理器一般都是i3、i5、i7的处理器,而这些处理器内部是有多个核心的(也就是大家平常所说的双核、四核、六核等等),每个核心都拥有自己的缓存,可以参考下面这张图片:
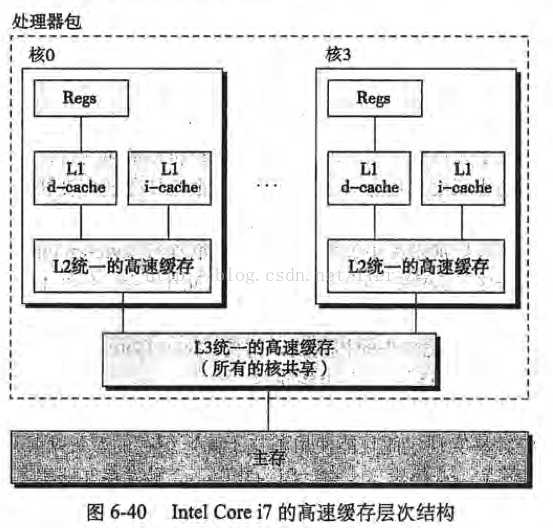
CPU执行一次指令的步骤如下:
1.程序相关数据加载到主内存
2.指令相关数据被加载到缓存
3.执行指令,并将计算结果存储在缓存中
4.将缓存中的数据写回主内存
这种执行步骤在单线程下是没有任何问题的,但是在多线程并发操作的情况下就会出现不可预期的结果。试想下面这种情况:
1.核心0中的某个线程读取一个字节,该字节会存储在核心0的缓存中以供下次直接使用
2.此时核心3的某个线程同样读取这个字节,那么该字节同样会被缓存在核心3的缓存中,此时核心0与核心3缓存的是一样的数据
3.然后核心0的线程修改了这个字节,并将修改后的结果存储在核心0的缓存中,此时核心3的线程获得了执行权。
4.核心3的线程开始执行指令,发现自己的缓存中存在该字节的数据,然后就会直接拿这个字节进行计算。但是,此时核心3的缓存中这个字节依旧还是核心0的线程修改之前的数据!!!
此时,问题就出现了,核心3的线程并没有取到该字节最新的数据,而是拿旧的数据去进行计算,那么计算后的结果就会出现偏差。
OK,问题已经抛出,那么CPU是如何解决这个问题的呢?其实就是通过一个lock指令来解决。什么是lock指令?这个概念就比较底层了,感兴趣的童鞋可以去搜索一下IA-32手册,这本手册里有详细的讲解了什么是lock指令以及lock指令具体做了什么。
我在这里就简单归纳一下lock指令的几个作用:
1.锁总线/锁缓存行。
2.lock指令会强制让线程在对缓存中某个数据做出修改后,必须先将修改后的结果同步写回主内存,然后其他的线程必须先从主内存中读取最新的数据,然后再执行指令。
3.类似于内存屏障的效果。
上面的lock指令的几个作用中,想必第1点和第3点童鞋们不是很清楚其中的概念。第3点涉及到了java内存模型的相关知识,这部分内容我会在JVM虚拟机专题中细讲,此处就先针对第1点解释一下。
总线的定义:CPU缓存和内存交换数据的介质。只要是CPU缓存想要和内存交换数据,必然要通过总线。
而早期的lock指令是这样做的:当一个CPU缓存想要往内存中写数据时,lock指令会锁住整条总线,即整条总线只能为该CPU缓存服务。那么此时如果其他的CPU缓存也想要把自己的数据写到内存中怎么办呢?对不起只能等当前这个CPU缓存和内存交换完数据后释放了总线的执行权,下一个CPU缓存才能继续获得总线的执行权,从而能够从主内存中读取最新的数据,执行指令后将最新的结果往内存中写。可以看到早期的lock指令的这种做法效率是非常低的,同一时刻只能有一个CPU缓存与内存进行数据交换。那么怎么解决效率低的问题呢?现代的处理器使用了一种最主流的协议——缓存一致性协议。
缓存一致性协议的定义:当CPU中的某个核心想要将执行完指令后的结果写回主内存时,必须先向总线申请获取权限。一旦获取了权限,那么这个线程就能和主内存进行数据交换,并且此时其他CPU核心正在不断“嗅探”总线,而一旦嗅探到更新数据的这块内存地址发生了改变,其他的CPU就会立即将自己缓存中这块内存地址缓存的数据设置为无效。而当下次执行指令需要用到这块内存地址的缓存数据时,就会因为缓存已经无效从而必须去主内存中加载最新的数据,然后才执行具体的指令。这种方法同一时刻只会锁定主内存中发生了变化的内存地址对应的缓存行,不会把整个总线锁住,其他缓存行还是可以进行数据交换的。
这里贴一张缓存行对应的几种状态,大家可以和上面的缓存一致性协议的各种情形进行对比:

现在我们再回看之前在图6-40下提出的问题,因为有缓存一致性协议存在,核心0的线程获取总线执行权将最新结果写回主内存时,核心3就会嗅探到这部分内存地址数据发生了改变,那么核心3就会将自己这部分的缓存置为无效。
等下次核心3的线程需要执行指令时,就会先从主内存中获取最新的数据,然后再执行。缓存一致性就是通过这种方式保证了线程间数据可见性。
什么是重排序
简单说,重排序就是编译器和处理器为了提高执行效率,会对程序中的指令自动重新排序。所以实际上JVM执行指令时的顺序并不是和我们在程序中定义的一致的。而重排序在单线程下没有任何问题,因为无论怎么重新排序只要保证最后的执行结果是正确的就行。但是在多线程环境下,就有可能因为重排序导致某个线程取到的结果其实并不是最新结果从而使后续的计算结果和预期不一致。volatile为了解决这个问题,就提供了一种“禁止指令重排序”的功能。
那么volatile是怎么做的呢?我们知道多线程环境下之所以出现问题,就是因为某个线程的读操作先于另一个线程的写操作发生,而这种情况出现就是因为指令重排序的问题。那么只要让这种读、写操作不会被指令重排序,不就ok了吗?
所以volatile做出了一种硬性规定,即所有涉及到有volatile变量修饰变量参与的读、写操作,都不允许和其他的指令进行重排序。volatile读指令和volatile写指令都会在该条指令前后插入一层“屏障”,来防止它们被JVM重排序。这样就能够保证volatile修饰的变量发生了改变后,后续所有的线程读取到的一定是最新的数据,即所谓的“禁止重排序”。
什么时候使用volatile变量?
上文讲了volatile的两个特性,那么什么时候使用volatile变量呢?我个人是推荐只有在下面这种情况才需要使用volatile变量:程序需要通过某个布尔类型的变量来判断执行逻辑,在多线程环境下这个变量应该使用volatile变量修饰。如下面代码所示:
1 volatile boolean flag; 2 ..... 3 while(!flag){ 4 doSomeThing(); 5 }
注意:为什么仅在这种情况下推荐使用volatile变量?因为这和volatile的一个特性有关,大家必须要牢牢记住:volatile只能保证可见性,但却不能保证原子性!!!如上面这种对布尔类型变量的读写本身就是原子性的操作,所以使用volatile变量保证可见性后,就能保证flag变量永远是最新的状态。但是,如a++这种操作,使用volatile修饰变量a并不能保证其在多线程环境执行下结果一定是正确的!因为a++并不是一个原子性的操作,它其实包含了3步指令:1.获取当前a变量的值;2.使该值自增1;3.将自增后的结果写回a变量。在这种情况下volatile只能保证第一步“获取当前a变量的值”时获取到的值是最新的,但不能保证某个线程在执行这3步指令时不会被另一个线程打断。设想下面这种情况:
1.假设a变量为1,一开始A线程执行了第1步和第2步,此时CPU分配给A的时间切片完毕,A缓存的值为2,然后B线程获取了执行权。
2.B线程同样执行了第1步和第2步,但在执行第3步之前又被A抢回了执行权,此时A将缓存中的2回写给a变量,a此时的值为2。
3.A执行完成后,B又抢到了执行权,此时问题出现了:B缓存的值也是2,但它并没有重新读取a的值,而是直接执行了第3步,将自己缓存中的2回写给了a变量,那么a最终的值就是2。
可以看到,尽管两个线程都执行了a++的操作,但是最终的结果确不是3而是2(相当于有一次线程执行无效),这在业务上可就是一个大问题了!因为我们日常应用中的代码都是组合式的代码,即一个业务必定是由一组代码合作完成的,很少很少出现一个业务可以仅仅由简单的原子性操作就能完成的情况。那么这种情况怎么办呢?这里就需要另外一个工具来处理了,也是我们下篇文章讲解的知识点——synchronized关键字。
OK,volatile的相关知识到这里就全部介绍完毕了,希望大家从本文中学到了东西。本文大量内容都参考了博客园(五月的仓颉)大神的“就是要你懂之volatile关键字解析”这篇文章,看看大神写的知识,然后自己在思考,我觉得是一种不错的学习方式。下篇文章将会讲解我们最常用的锁——synchronized关键字的用法和特性。
以上是关于线程间通信与协作方式之——volatile关键字的主要内容,如果未能解决你的问题,请参考以下文章