HDFS之深入简出
Posted chenligeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS之深入简出相关的知识,希望对你有一定的参考价值。
分布式文件系统HDFS
一:概述
1.HDFS设计目标
2.HDFS核心组件
3.HDFS副本机制
4.HDFS环境搭建
5.HDFS shell命令 java api
6.HDFS读写流程
7.HDFS优缺点
二:
思考:如何创建一个分布式文件系统
重点:文件以多副本的方式进行存储

缺点:文件不管多大都存在一个节点上
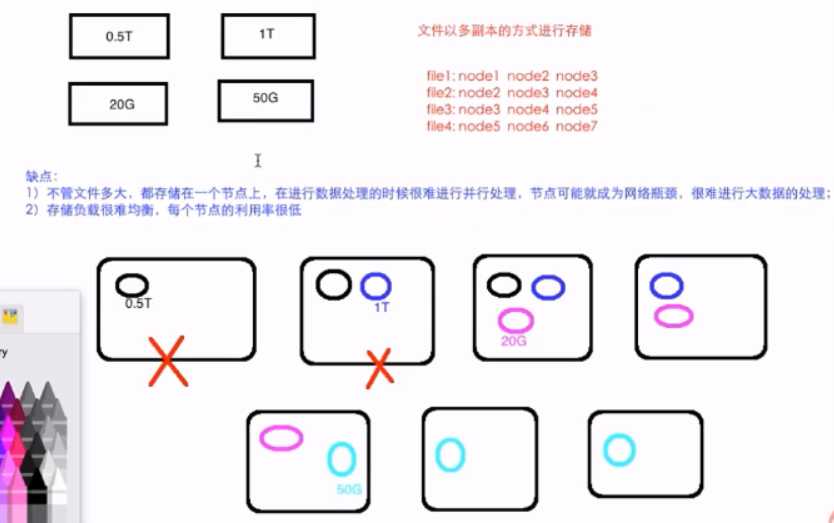
1.缺点不管文件多大,在进行数据处理的时候很难进行并行处理,节点有可能成为网络瓶颈,很难进行大数据处理
2.负载均衡很难,每个节点利用率很低
二:分布式文件系统HDFS,来源于Google的GFS论文
发表在2003年,HDFS是GFS的克隆版
1.HDFS是非常巨大的分布式文件系统
2.运行在普通的廉价的机器上面
3.易扩展,为用户提供不错的文件的存储服务(130M的文件,拆分成128M和2M,一般情况还有3个副本)
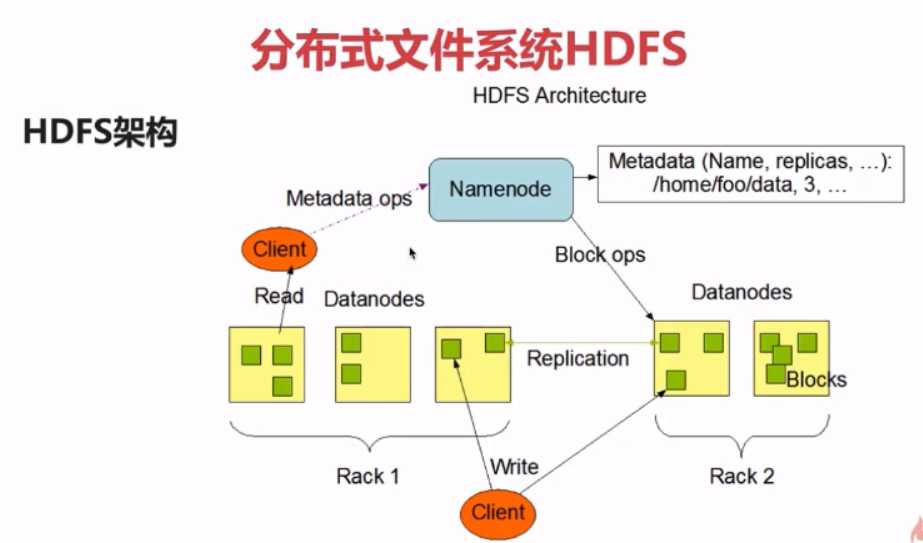
1.架构
1个Master(NameNode/NN)带N个Slaves(DataNode/DN)
HDFS/YARN/HBase
重点:一个文件将会被拆分成多个Block
blocksize:128M
130M ==> 将会被拆分成2个Block: 128M 和 2M

NameNode:
NameNode是对文件系统的操作,而DataNode是对block的操作
NameNode:是对客户端请求和响应,和元数据(文件的名称,副本的系数,Block存放的DataNode)的管理
DataNode:
DataNode:1.存储用户文件对应的数据块(Block)
2.要定期向NameNode发送心跳信息,汇报本身及其所有block信息,健康状况

一个典型是,一台机器上运行一个NameNode,集群中的其他的机器,每一个都会运行一个DataNode
1个NameNode + N个DataNode
这个架构也并不排除在一台机器上运行多个DataNode,但是在生产环境上是不建议这么做
三:HDFS副本机制
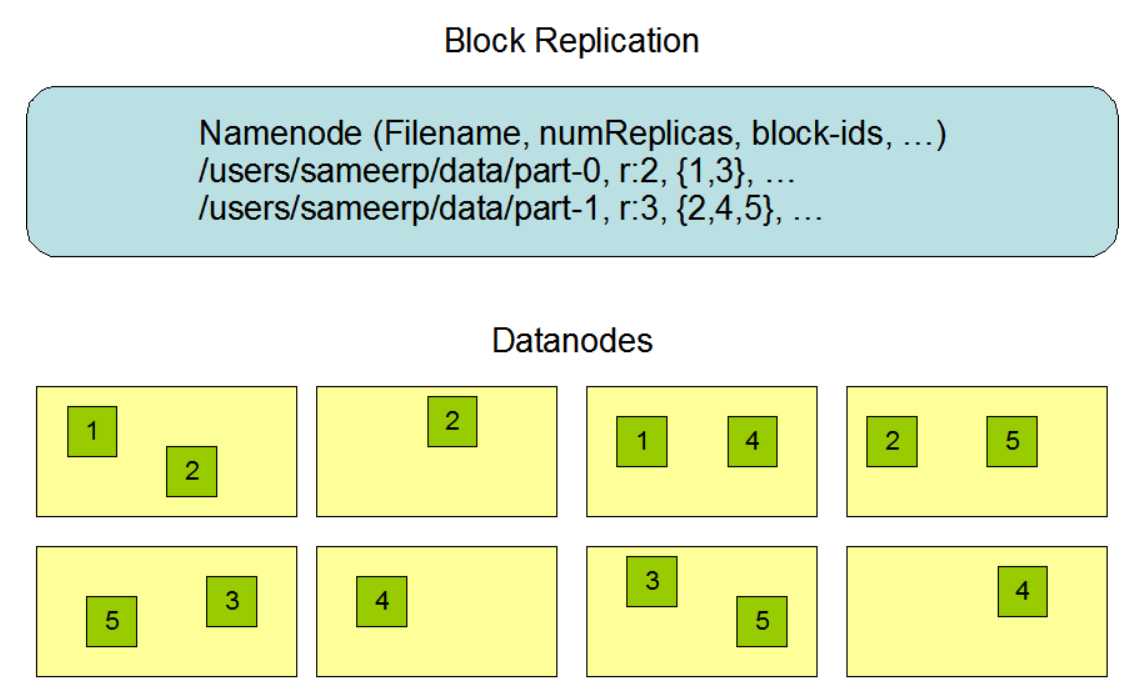
replication factor : 副本因子,副本系数
一个文件里面的所有的block前面的都是一样,只有最后一个不一样
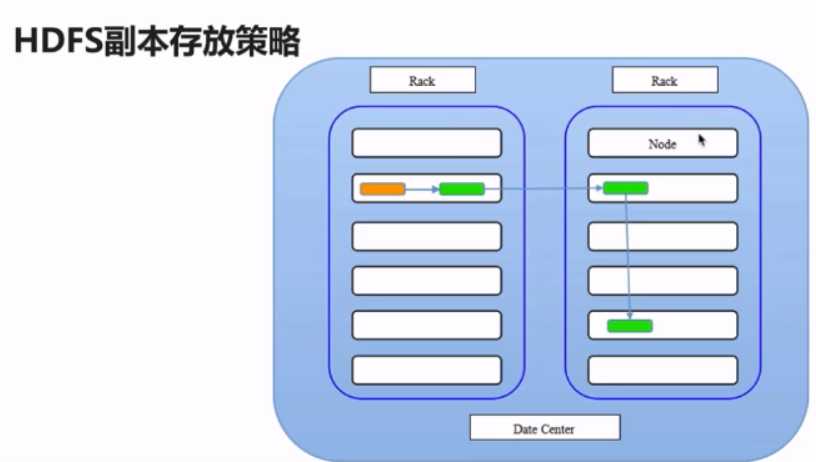
四:HDFS副本存放的策略
以上是关于HDFS之深入简出的主要内容,如果未能解决你的问题,请参考以下文章