5.4.4 表
Posted zhouwansheng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5.4.4 表相关的知识,希望对你有一定的参考价值。
5.4.4 表
和所有关系数据库管理系统一样,SQL Server 2008把数据存储在称为“表”的对象中。 正如第1章所述,本书假定您至少熟悉关系数据库的概念,所以这里不会花太多时间去解
释什么是表或如何创建它们。和 SQL Server 2008数据库管理员相关的是如何维护和保护表 以优化数据库的性能和安全性。第6 章会详细讨论安全性,所以本章仅讨论数裾表的维护,
但首先需要了解一点背景资料。
1 .表排序规则
如前所述,创建数据库时,可以配置不同于服务器的排序规则支持。对于包含字符数
据的表列来说也是如此。每个列都可以具有不同的排序规则设置。例如,AdventureWorks Cycles公司想要使来自世界各地的客户都可以使用自己的语言浏览和搜索产品目录。为实
现这一功能,我们使用下列脚本构建了一 ^ GlobalProductDescription表:
USE AdventureWorks2008
GO
CREATE TABLE Production.GlobalProductDescription( ProductDescriptionlD int IDENTITY(1,1) NOT NULL, EnglishDescription nvarchar(400) COLLATE SQL_Latinl_Genera1_CP1_CI_AS NULL, FrenchDescription nvarchar(400) COLLATE French_CI_AS NULL, ChineseDescription nvarchar(400) COLLATE Chinese_PRC_CI_AI NULL, ArabicDescription nvarchar (400) COLLATE Arabic_CI_AS NULL, HebrewDescription nvarchar(400) COLLATE Hebrew_CI_AS NULL, ThaiDescription nvarchar(400) COLLATE Thai_CI_AS NULL, ModifiedDate datetime NOT NULL)
现在,可以使用业务需求中定义的语言排序规则排序和搜索每一列。不过不要误解。
SQL Server绝对不是什么通用的翻译器。它只是提供了一个框架来存放多种语言。您需要 准备产品描述的正确翻译并把它们放到合适的列中,另外还要处理任何因为tempdb的排序 规则导致的排序规则不兼容性。要了解有关排序规则的更多信息,可参见第2 章。
2 .表体系结构
如第4 章所述,SQL Server使用8KB的数据页存储信息。表中的所有数据都存储在这 些数据页中,但数据在页中的组织方式会因表的创建方式和在表创建后所进行的操作而有
所不同。默认情况下,所有数据以称为堆的无组织的方式进行存 储 。SQL Server并不尝试 组织或是以任何方式排序数据,也不维护页间的链接。下列代码创建了一个以这种方式存
储的表:
CREATE TABLE Employee( Employeeld int IDENTITY,
FirstName nvarchar(25) NOT NULL, MiddleName nvarchar(25) NULL, LastName nvarchar(25) NOT NULL,
H ireD ate sm alldatetim e
)
虽然这种安排对于把数据添加到表中很有用,但是如果试图在表中查找一个特定的行
或一组行时,这不是一个最优的解决方案。考虑图书馆的例子。如果您在管理一个图书馆,
把所有的书按它们进来的顺序放在书架上,完全不考虑其类型、作者或标题,那么可以很
容易地放置这些书。然而,当要找某-本书时,您将不得不搜寻所有的书架。这也正是SQL
Server在堆中查找记录时的工作方式。在本章后面,我们将介绍索引,并了解它们如何帮 助解决此问题,但首先讨论将表分成更小的块所起的作用。
3 .分区表
SQL Server将所有数据页存放在称为分区的逻辑单元中。除非明确分隔,否则表一般 存储在定义于单个文件组上的单个分区中。不过,通过跨多个由文件组定义管理的文件横
向分区表,SQL Server可以把大型表划分为较小的可管理单元。
仅 SQL Server 2008企业版和开发人员版有表分区功能。 例如,可以物理划分一个有着数百万行的事务表,将本年度的所有事务和 上 一 年的事
务分开。这样,只需要扫描表的子集来选择、插入或更新本年度事务。
要说明物理表分区的好处并展示如何实现它们,必须首先创建一个要进行分区的表。可
以使用下列脚本创建dbo.Transactions表,用于存放测试数据。Transactions表的基本结构与
Production.TransactionHistory 表和 Production.TransactionHistoryArchive 表相同。
USE AdventureWorks2008 GO
CREATE TABLE dbo.Transactions( TransactionlD int NOT NULL, ProductID int NOT NULL, ReferenceOrderlD int. NOT NULL, ReferenceOrderLinelD int NOT NULL, TransactionDate datetime NOT NULL, TransactionType nchar(l) NOT NULL,
Q uantity in t NOT NULL,
ActualCost money NOT NULL, ModifiedDate datetime NOT NULL)
要填充这个新的Transactions表,可以使用UNION操作符,插入所有来自于TransactionHistory 表和 TransactionHistoryArchive 表的行。
USE AdventureWorks2008 GO
INSERT dbo.Transactions SELECT * FROM Production.TransactionHistory
UNION ALL
SELECT * FROM Production.TransactionHistoryArchive
在有了一个大小合适的表后,就可以对其执行一个査询以査看分区之前的性能。该表
总共包含202 696行。在表中的事务行里,2001年 有 12 711行,2002年有38 300行,2003
年 有 81 086行,2004年有70 599行。
--Pre Partition Statistics USE AdventureWorks2008
GO
DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
DECLARE @BeginDate AS datetime, QEndDate AS datetime SET @BeginDate =*2002-01-011 SET @EndDate =*2002-12-31‘
SELECT SUM(Quantity) AS TotalQuantity, SUM(ActualCost) AS TotalCost FROM dbo.Transactions WHERE TransactionDate BETWEEN @BeginDate AND QEndDate
该脚本使用DBCC DROPCLEANBUFFERS命令清除缓冲区缓存中的所有页。这样可
以知道需要多少次物理读取来将所有需要的数据放入内存中。它还使用SET STATISTICS
IO ON选项打开统计信息报告功能,然后查询dbo.Transactions表返回2002年的总销售量 和售出的总产品数。
该查询的结果如下所示:
TotalQuantity TotalCost 1472494 16427929.3028
(1 row(s) affected)
Table ’Transactions*. Scan count 1, logical reads 1408, physical reads 26, readahead reads 1407, lob logical reads 0, lob physical reads 0, lob read-ahead
reads 0 .
提示:
要看到如上所示的结果,必须以文本形式显示查询结果。方法是在运行查询前按下
CtrRT组合键。要切换至网格视图,可按Ctrl+D键并再次运行查询。 可以看到,为了满足查询的要求,SQL Server不得不扫描表。要找到符合WHERE子
句条件的38 300行,SQL Server不得不扫描全部202 696行。这一扫描会造成1408次逻辑
读取。
现在对表进行分区,把该表物理划分为多个文件,使所有的事务按年份分开,看会发
生什么情况。
在最理想的情况下,在往表中填充数据之前,您就知道想要物理分区它,但理想的情
况是相当少见的。在本例中,在创建好Transactions表之后,您决定要对它进行物理分区。 由于数据存储在堆中,所以必须创建一个新的分区表,把数据移至其中,然后删除原来的
表(本章后面将介绍一种更容易的实现方法)。
对表进行分区的第一步是创建文件组,它们将保存用于存储表分区的数据文件。从之
前对文件组的讨论可以知道,表不能指派给某一特定的文件,而只能指派给一个文件组。
在这个例子中,每个文件组将只包含一个文件。但是并不是必须这么做。分区可以存在于
多个文件上,也可以在一个文件上。
下面的脚本添加了 4 个各含一个文件的文件组来包含分区的事务表。您将按日期对
Transactions表进行分区:
USE MASTER
GO
ALTER DATABASE AdventureWorks2008 ADD FILEGROUP FGPre2002
GO
ALTER DATABASE AdventureWorks2008 ADD FILE
( NAME = 1AworksPre20021 , FILENAME = * E :SQLDataAworksPre2002.ndf
r
SIZE =20MB
, FILEGROWTH =20% )
TO FILEGROUP FGPre2002
GO
ALTER DATABASE AdventureWorks2008 ADD FILEGROUP FG2002
GO
ALTER DATABASE AdventureWorks2008 ADD FILE
( NAME = ,Aworks2002, , FILENAME = ,E ?? SQLDataAworks2002 . ndf,
r
SIZE =20MB
, FILEGROWTH =20% )
TO FILEGROUP FG2002
GO
ALTER DATABASE AdventureWorks2008 ADD FILEGROUP FG2003
GO
ALTER DATABASE AdventureWorks2008 ADD FILE
( NAME = ,Aworks2003‘ , FILENAME = ‘E :SQLDataAworks2003.ndf * , SIZE =20MB
, FILEGROWTH =20% >
TO FILEGROUP FG2003
GO
ALTER DATABASE AdventureWorks2008 ADD FILEGROUP FG2004AndAfter
GO
ALTER DATABASE AdventureWorks2008
ADD FILE
( NAME = *Aworks200 4AndAfter‘
? FILENAME = * E :SQLDataAworks2004AndAfter.ndf * , SIZE =20MB
, FILEGROWTH =20% )
TO FILEGROUP FG2004AndAfter
GO
提示:
该脚本假定存在一个E 驱动器和一个SQLData文件夹。要在您的环境中运行它,可能 需要更改驱动器号指派、
对 Transactions事务表进行分区的下一步是创建一个分区函数。分区函数为每个分区 确定边界。必须在创建时指定函数将处理的数据类型。所有数据类型都是有效的,但是这
不包括别名数据类型、CLR 类型,以及 text、ntext、image、xml、timestamp、varchar(max)、 nvarchar(max)或 varbinary(max)类型。例如,分区函数将指定值范围为1? 10 000、100 001?
1 000 000等。记住,在指定分区函数时,只能按单个值分区。
本例按日期进行数据分区,以根据针对该表执行的最频繁的查询把数据组织到一起。
运行下面的脚本创建一个分区函数,该函数可以按日期把表分成4 组记录。第一组是从
NULL至 2001年 12月 31日。第二组是从2002年 1月 1 日至2002年 12月 3 1 日。第三组
是从2003年 1月 1 日至2003年 12月 31日,而最后一组是从2004年 1月 1 日至INFINITY。
CREATE PARTITION FUNCTION YearFunction (datetime) AS RANGE RIGHT FOR VALUES (‘1/1/2002‘, ,l/l/2003, , ?1/1/2004,)
创建分区函数时,可以使用RANGE RIGHT或 RANGE LEFT选项。当分区所依据的
值为边界值时,它们可以用来确定行将存储在哪个分区中。例如,如果使用RANGE LEFT
选项,而日期值为边界值,那么该行将存储在边界左边的分区中。上面的脚本使用RANGE
RIGHT选项,所以向表中插入事务日期为2003年 1月 1 日的事务时,记录将放在第三组中。
创建了定义分区边界的函数之后,必须创建一个分区方案。分区方案用于确定分区的物理
存放位置。在定义分区方案时,指定的文件组数必须与分区函数中定义的分区数相同。运行下
列脚本创建一个分区方案,将 YearFunction创建的分区映射到之前创建的文件组。
CREATE PARTITION SCHEME YearScheme AS PARTITION YearFunction TO (FGPre2002, FG2002, FG2003, FG2004AndAfter)
如果想分区表,但将所有分区存储在同一文件组中,那么有两个选择:对每个分区重
复使用同一文件组名,或对单个文件组使用ALL TO选项,例如ALLTO([PRIMARY])。
也可在最后一个文件组后指定一个额外的文件组。这个文件组被标记为“下一”文件
组,可在创建另一分区时使用。
现在要做的只是创建实际分区表并将数据从原Transactions表中移至分区表中:
USE AdventureWorks2008
GO
CREATE TABLE dbo.PartitionedTransactions( Transaction!D int NOT NULL,
ProductID int NOT NULL, ReferenceOrderlD int NOT NULL, ReferenceOrderLinelD int NOT NULL, TransactionDate datetime NOT NULL, TransactionType nchar(l) NOT NULL, Quantity int NOT NULL, ActualCost money NOT NULL, ModifiedDate datetime NOT NULL) ON YearScheme(TransactionDate) GO
INSERT INTO dbo.PartitionedTransactions SELECT * FROM dbo.Transactions
在创建分区函数和分区方案时,要记住它们可用于分区任意多个表。YearFunctkm和
YearScheme可用于分区AdventureWorks2008数据库中具有datetime列的任意表。
要查看査询性能是否得到提升,可运行之前在Transactions表上运行过的查询:
--Post Partition Statistics DBCC DROPCLEANBUFFERS
SET STATISTICS IO ON
SELECT SUM(Quantity) AS TotalQuantity, SUM(ActualCost) AS TotalCost FROM dbo.PartitionedTransactions WHERE TransactionDate BETWEEN ?1-1-2002* AND ‘12-31-2002* The results of the query are as follows: TotalQuantity TotalCost 1472494 16427929.3028
(1 row(s) affected)
Table ‘PartitionedTransactions*. Scan count 1, logical reads 266, physical reads 5, read-ahead reads 259, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
物理分区表后,检索结果所需的逻辑读取数从1408降至266。I/O开销的减少会使CPU
使用率减少,从而使查询更有效率。记住,这一性能提升是体现在一个只有202 696行的表
上的。想象-下,如果该表包含10年的数以百万计的数据行,并且按年份定义分区,性能
提升会是怎样。在査询某个特定年份时,性能提升会更为显著。
虽然在SQL Server 2005中可以创建分区表,但唯一方式是使用代码。尽管我可以毫无
困难地编写脚本,但如果可使用GUI编写它则更好。SQL Server Management Studio现在不
仅能创建分区表,还可以为之生成脚本,从而可以在任何服务器上运行它。另一好处是它可
以恰当地执行操作,所以您不必担心创建一个新表和向其中移入数据的操作。让我们看一下
对 AdventureWorks2008 数据库中的 Production.TransactionHistory 表进行分区的过程。
提不:
如果您按上一节的内容执行了操作,那么需要刪除表、分区函数和分区方案来学习下
一节。下列脚本可完成此任务:
IF EXISTS (SELECT * FROM sys.tables WHERE object_id = OBJECT_ID(’ dbo.PartitionedTransactions1)) DROP TABLE dbo.PartitionedTransactions
IF EXISTS
(SELECT * FROM sys?partition—schemes WHERE Name = ‘YearScheme‘) DROP PARTITION SCHEME YearScheme
IF EXISTS
(SELECT * FROM sys.partition_functions WHERE Name = ‘YearFunction1 ) DROP PARTITION FUNCTION YearFunction
要 通 过 SQL Server Management Studio对表进行分区,可右击想分区的表,选 择 “存 储 ” | “创建分区”命令,如 图 5-11所示。
使 用 “选择分区列”页面选择对表进行分区的列(如图5-12所示)。如前所述,只有特定
数据类型可用于分区列,向导将只显示有效类型的列。在这里,我们选择TmnsactionDate列。
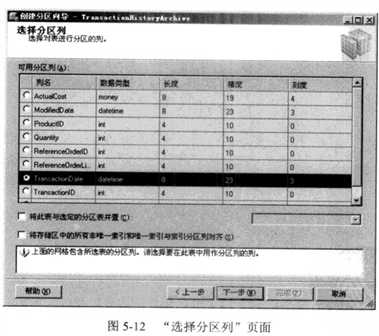
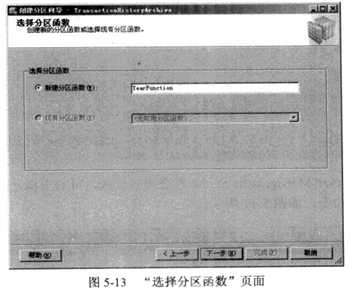
在 单 击 “下一步”按钮后,选择要使用的分区函数(见图5-13)。如果选择使用现有函
数,只能选择可用于在上一页面中选择的列的函数。如果数据库中没有为所选列的数据类
型定义的分区函数,那么需要创建一个新分区函数。输入新分区函数的名称,并 单 击 “下
一步”按钮。
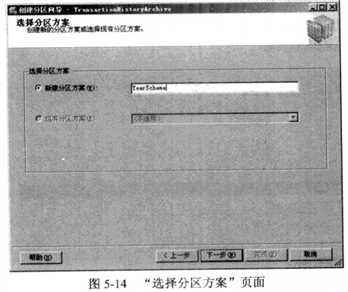
现在需要为表选择一个分区方案(如图5-14所示)。如果有一个分区方案,它为选择的
函数定义了合适数目的文件组,那么可以重用这个分区方案,否则需要创建一个新的分区
方案。单 击 “下一步”按钮继续。
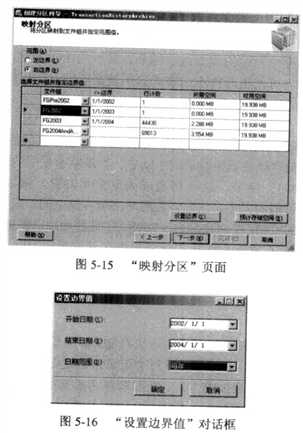
“映射分区”页面(见图5-15)用于定义分区函数的边界以及分区和文件组之间的映射。
如果分区列为 date、datetime % smalldatetime、datetime2 或 datetimeoffset,那 么 “设 置 边 界 ”
按钮将被启用。通 过指定“幵始H 期”、“结束日期”和 “日期范围”可以快速为分区函数
定义边界点。可以创建按天、月、季度、半年或年划分的分区。一旦定义了分区,需要将
它们映射到所需的文件组。文件组必须已经存在,不能在此时创建。在定义映射时,最后
一个文件组不会映射至边界点。该文件组不是标记为下 一 文 件组,而是标记为放置最后一个分区的文件组。图5-16显示了 “设置边界值”对话框。
现在可以创建对表进行分区的脚本、立即进行分区或安排以后执行分区操作(见图
5-17)

4 . 数据压缩
SQL Server 2008引入了压缩表、索引或分区中的数据的功能。这可以节省I/O请 求 , 因为每页上的数据越多,意味着读入内存的页更少。另外,由于有更多的数据存储到每个
数据页上,同样大的内存中存储的数据也就越多。较少的I/O和在内存中存储更多的数据
这两点往往能提髙性能。可使用两种不同模式启用数据压缩:行压缩或页压缩。
行压缩
行压缩是SQL Server 2005 SP2中引入的vardecimal存储格式的演变。在出现vardecimal
存储格式之前,十进制值存储在固定数量的空间中。十进制值使用的空间量基于为列定义的
小数位数,其范围为5?17字节。这经常造成大量空间浪费。例如,如果将一列定义为
decimal(15,15),那么不管值的大小,它都将占用9 字节存储空间。启用vardecimal存储格式 后只会占用足够存储值的空间。在 SQL Server 2008中,这种功能已扩展至所有定长数据类型。 现在,我们己经了解了 SQLServer如何将数据存储在表中,以及如何通过对数据进行 分区提髙性能,接下来看一下改进数据检索性能的另一种方法—— 索引。
以上是关于5.4.4 表的主要内容,如果未能解决你的问题,请参考以下文章