这就是搜索引擎—检索排序链接分析
Posted 木叶叶叶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这就是搜索引擎—检索排序链接分析相关的知识,希望对你有一定的参考价值。
这个系列的文章是一只试图通过产品角度出发去理解复杂庞大搜索引擎的汪写出来的,不足之处很多,欢迎广大技术、非技术同学阅读后指正错误,我们一起探讨共同进步。
本篇主要介绍搜索引擎的检索模型和搜索排序。就是利用某种检索模型从海量数据中挑选“好的”网页经过排序后生成最终结果推送给用户。搜索结果排序是是搜索引擎最核心的部分,决定了搜索引擎质量好坏。排序中最重要的两个因素是查询内容相关性和网页链接情况。
一、内容相关性
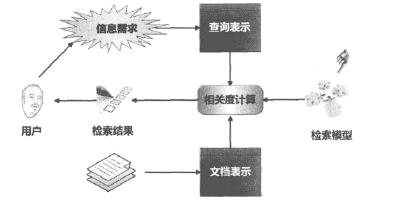
判断相关性依赖于搜索引擎使用的检索模型。下图是内容相似性计算框架,用户发出搜索请求,检索模型根据请求计算网页相关性返回检索结果,可以看出检索模型对内容相关性起着决定性作用。
1.1常用的检索模型
1.1.1 布尔模型(boolean model)
文档与查询query二者包含单词做布尔运算,判定query与文档的相似性。这种方法输出结果只有相关和不相关,过于粗糙,实际中应用较少。
1.1.2 空间向量模型(vector space model)
思想:将文档看做由t维特征组成的向量,常用单词作为特征,每个特征根据一定依据计算权重,最终带权重的特征构成文档,以此来表示网页的 主要内容。通过计算文档特征与查询特征向量之间的cosine值来计算相似性。
特征权值的计算一般采用Tf*IDF框架。TF代表词频,Tf越大则该词的权重越大。IDF代表逆文档频率因子,代表单词在文档集合里的频率。特征词出现在越多文档,则IDF权重越小,IDF代表了单词所带信息量的多少。Tf*IDF框架一般吧TF权值和IDF权值相乘得到特征的权值。
缺点:cosine值会对长文档进行抑制。
1.1.3 概率检索模型
由概率排序原理推导出来,具体原理么看懂,但这个是目前效果最好的模型之一,okapi BM25这一经典概率模型在商业搜索引擎页面排序中广泛使用。
1.1.4 语言模型
为每个文档建立不同的语言模型,判断由文档生成用户查询的可能性,按照生成概率高低排序。我理解为将文档中的单词分组,类似于从不同盒子里抽红球、白球的问题,计算从不同组抽单词组成用户query的概率。语言模型代表了单词或单词序列在文档中的分布情况。
1.1.5 机器学习
机器学习排序系统由4个步骤组成:人工标注训练数据、文档特征提取、学习分类函数、实际搜索系统中采用机器学习模型。人工标注数据目前常用用户点击记录来模拟。机器学习排序原理如下:

其中的机器学习系统又有三种常见方法,如下,
单文档方法:机器学习系统对文档打分,打分结果即为搜索结果。相似性判断是二元的,即要么相关要么不相关。
文档对方法:侧重在于对任意两个文档组成的文档对<Doc1,Doc2>的顺序关系是否合理进行判断。
文档列表方法:将查询对应的所有搜索结果列表整体作为机器学习训练的实例。
1.2 检索质量评价标准
通常来说检索使用精准率和召回率来评判,精准率是指一次搜索结果中相关文档所占的比例;召回率指一次搜索结果中包含的相关文档占整个集合中所有相关文档的比例。
对于搜索引擎来,精准率更多重要,因为引擎处理海量数据,查找所有相关文档较难;此外搜索结果一部分即可满足用户需求。常用搜索引擎精度评估指标为P@10和MAP。
P@10:关注搜索结果前10个文档中相关比例。
MAP(mean averageprecision):多次查询的平均准确率。每个相关文档的理想排名除以实际排名得到的分数均值为ap指标,多组查询的ap值求平均即为Map指标。该方法能兼顾相关性和召回率。
二、网页链接分析
一个网页除了与用户输入query计算相关性外,自身也有质量高低,需要根据网页质量对相关性检索排序进行调整。而链接分析就是用来判断网页重要性的。
2.1 一些基本概念
常用网页链接分析模型有随机游走模型和子集传播模型。
随机游走模型(random surfer model):用户在一个页面打开该页面的任何一个出链的概率是相同的。不断重复出链过程,在相互有链接指向的页面之间跳转。而直接在浏览器中输入网址跳转称为远程跳转(teleporting)。

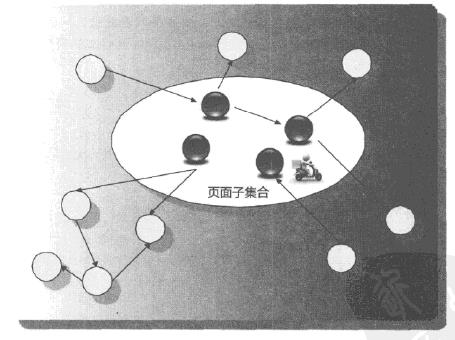
子集传播模型:将互联网网页按照规则划分为多个具有特殊属性的子集,给予子集内网页初始权值,然后按照链接关系将权值传递到其他网页。
2.2 常见链接分析算法
2.2.1PageRank算法
pagerank是谷歌开发的一套链接分析方法,具有很强的实用价值。Pagerank有两个基本假设,数量假设:一个页面接收到的其他网页指向的入链数量越多,这个网页越重要。质量假设:越质量高的页面指入,则页面越重要。
Pagarank算法思想:为每个网页赋予相同的重要性,通过迭代递归计算更新每个页面节点的pagerank得分,直到得分趋于稳定。
需注意链接陷阱(link sink)。链接相互指向,形成环形结构,从而形成链接陷阱。链接陷阱内页面pagerank的得分会越来越高。为解决该问题,为网页添加跳转至任意其他页面的概率,即远程跳转。相当于为每个页面增加了指向互联网任意页面的虚拟边,权值可以通过虚拟边向外传递,避免链接陷阱导致的问题。
2.2.2HiTS算法
两个基本概念Hub页面:很多指向高质量authority页面链接的网页,如hao123首页;Authority页面:与某个领域或话题相关的高质量网页,如搜索领域的google和百度首页。
两个基本假设:一个好的authority页面会被很多好的hub页面指向;一个好的hub页面会指向很多好的authority页面。Authority页面和hub页面是相互增强的关系。
算法思想:通过用户搜索获得排名靠前的网页,组成根集(root set),然后将与根集有直接链接指向关系的网页扩充进行形成扩展网页集合,每个网页设置hub和authority权值,利用相互增强关系等原则进行多次迭代计算,直到权值稳定,最终使用权值排序。
问题:计算效率低、主题漂移、易被作弊者操纵结果、结果不稳定。
其余链接分析算法:salas算法、主题敏感pagerank、hilltop算法、智能游走模型、偏置游走模型、PHITS算法、BFS算法。(没细看,有兴趣可以去看《这就是搜索引擎》这本书)。
就这样,搜索引擎利用网页内容相关性及网页链接情况得到网页排序推送给用户。至此(一)、(二)篇已经介绍了搜索引擎通过爬虫获取数据、建立索引并通过内容相关和链接分析对网页排序来响应用户的query请求,下一节将介绍搜索引擎的优化。
http://blog.csdn.net/youdianmuye/article/details/52106202
以上是关于这就是搜索引擎—检索排序链接分析的主要内容,如果未能解决你的问题,请参考以下文章