unit 1.基础语法
Posted happy-sir
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了unit 1.基础语法相关的知识,希望对你有一定的参考价值。
本章内容
1.python大致思维导图构想
2.安装环境
3.基础语法
Python大致思维导图构想
该学习之路的旅程,大体将会参照Alex老师的Python自动化全栈开发的视频的路线走。正如我前言所讲,我开始编写自己的博客是受Alex的启发。但是我可能不会完全按照视频的天数来编写博客,因为我写博客要的不仅是学后的知识整理,还希望能够帮我复盘,快速回忆知识点。因为IT行业要不断的更新,但是总不能不能捡一个扔一个吧。我也是刚刚开始,如果你也刚开始或则发现我说的你也认同,那么让我们一起探寻一个高效的方法吧!
首先,因为刚开始,Python的整个思维导图无法一下子拼全,所以让我们一步步来凑齐下面这张导图(集齐真的可以召唤神龙):
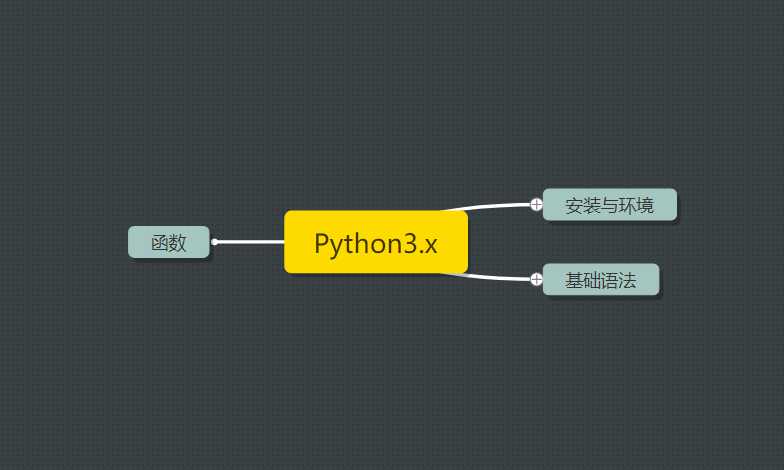
图1.1
安装环境
安装的教程很多,在廖雪松老师的博客中有比较全面的文档教程,可以参照搭建环境哦。图1.2中的结构是关于执行python代码的两种方式。
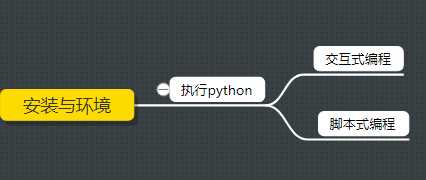
图1.2
基础语法
基础语法中有很多内容,所以我们先看看包含哪些部分再一一介绍。

图1.3
注释本身就很简单,也没有要分析的地方。python里的变量的命名和以前学过的语言几乎是一样的。但是在python里变量有这样一个特点: 1)不需要声明,但是使用前必须赋值了;(与C语言比较,如果没学过C,记住就行了。)
输入输出
输入 常用的就是读取键盘输入 1)input(‘ 提示输入的内容‘) 简单输入
2)使用getpass模块中的getpass方法 ,getpass.getpass(‘提示输入的内容‘) 用于输入密码这种屏幕上不显示的内容。
输出 在菜鸟教程中的输出讲了很多,特别细,我也不知道用在什么地方,让我们先使用很简单的,不要在一些入门的小东西上死扣,这样容易入门死。
1)print() 输出一些字符串,数字类数据。 连接 str和numer类型的数据要用逗号,中间会用空格隔开;加号用于将两个字符串的变量连接起来输出,中间没有空格,如果用逗号就会加上空格。 print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end="":
2)print() 的格式化输出可以使用 <1> 旧式的格式化(类似C语言中的格式化输出) <2> .format的方法格式化输出


1 #Author: Happy yu 2 import getpass 3 4 _username=‘Happy yu‘ 5 _password=‘123456‘ 6 username=input(‘username:‘) 7 #使用密文形式输入密码的方式 8 password=getpass.getpass(‘password‘) 9 10 if _username==username and _password==password: 11 print(‘Welcome user {name} login...‘.format(name=username)) 12 else: 13 print(‘Invalid username or password!‘)
1 #Author: Happy yu 2 total=100 3 name=‘Happy‘ 4 print(‘%s get %d score!‘ % (name,total)) 5 print(‘{} get {} score!‘.format(name,total)) 6 print(‘{name} get {total} score!‘.format(name=name,total=total)) 7 print(‘{_name} get {_total} score!‘.format(_name=name,_total=total))
python3中的标准数据类型有六种,其中三种是可变数据。
- 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
-
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
数字 因为变量不需要声明,所以数字使用就很灵活了,(使用起来)表面上不再有各种整型,浮点型等数据格式的区别。
字符串 用单引号或双引号括起来的单个或多个字符。字符串有很多操作方法,我们直接上代码,直截了当。要看出什么效果,我就不贴图了,你可以直接复制,运行对应看结果就可以了哦。里面不包括所有的用法,删除了一些重复和不常用的操作,所以只要掌握以下的操作够够的了。
1 #Author: Happy yu
2 name="my name is Happy_yu"
3 names="my name is {name}"
4 print(name)
5
6 print(name.capitalize()) #首字母大写
7 print(name.upper()) # 全部大写
8 print(name.lower()) #全部大写
9 print(name.title()) #所有的首字母大写
10 print(name.count(‘a‘))
11 print(name.center(40,‘*‘)) #字符串(居中)+‘*‘=40个字符
12 print(name.encode(‘utf-8‘))
13 print(name.endswith(‘com‘)) #判断结尾字符,用与判断字符格式
14 print(name.find(‘name‘)) #返回从左开始查找字符的第一个字符位置
15 print(name[name.find(‘name‘):8])
16 print(names.format(name=‘happy‘)) #格式化输出
17 print(‘1234‘.isdigit()) #string 中是否只有数字
18 print(‘aasda‘.isalpha()) #string 中是否只有字母
19 print(‘+‘.join([‘1‘,‘2‘,‘3‘,‘4‘])) #将列表中的元素用 ‘+‘ 连接起来
20 print(‘ 1234
‘.strip()) #消除前后以及字符中间的换行 空格
21 p=str.maketrans("abcdef","123456") #制作密钥
22 print(name.translate(p)) #用密钥加密
23 print(name.replace(‘m‘,‘M‘,1))
24 print(name.split(‘y‘))
25 print(‘KoBe‘.swapcase())
元组 :如:(1,2,[‘lebron‘],{‘name‘:‘kobe‘})
特点:不可变列表,顾名思义,元组不能进行增删改,但是元组也是可以查的,方法与列表一样。所以元组使用起来更加的安全,但是这种情况要分清楚了:元组中一个元素是列表。先看代码:
1 #Author: Happy yu
2
3 t1=(1,‘happy‘,2)
4 t2=(1,[‘kobe‘],3)
5 #t1[1].append(‘kobe‘) #这个错误的
6 t2[1].append(‘lebron‘) #正确 原因:元组不可变,但是元组里的列表里的
7 #内容可变,这个作为元组元素的列表不可变
8 t2[1]=23 # 所以这个就错了
9 print(t2)
列表 如:[3,‘lebron‘,{‘name’:‘kobe‘}]
特点: 1) 可变的有序的集合,可以进行增删改查等操作,2) 列表里的数据类型可以是任何数据类型(元组忘了说) 3)列表里可嵌套列表,构成二维列表。
1 #Author: Happy yu
2 import copy
3
4 names=[‘happy‘,‘lebron‘,‘kobe‘,‘jordan‘,‘brook‘]
5 #--->1-name2=names[0:-1:2] #list的切片
6 names.sort()
7 print(names)
8 #--->2- 复制一份
9 #name2=names
10 #names[0]=‘george‘ #结果不同于 a=5,b=a,a=2 ==>b没有跟着a变化
11 names.append([‘westbrook‘,‘George‘])
12 name2=names.copy() #复制的那份不会跟着变化 只限于第一层列表 浅copy
13 names[-1][-1]=‘george‘
14 names.append(‘acl‘)
15 print(names)
16 print(name2)
17
18 name2=copy.deepcopy(names)
19 names[-2][-1]=‘George‘
20 print(names)
21 print(name2)
22
23
24 ‘‘‘--->3- 增删改查
25 #增
26 names.append(‘lrying‘)
27 print(names)
28 names.insert(2,‘leonard‘)
29 print(names)
30 #删
31 #names.remove(‘brook‘)=names.pop(-2)
32 #del names[-2]
33 #改
34 names[-2]=‘westbrook‘
35 print(names)
36 #查
37 print(names.index(‘lebron‘))
38 print(names[names.index(‘lebron‘)])
39 ‘‘‘
增删查改的操作很简单,尤其要注意的是复制列表,有很多坑点。三种复制,在代码里都出现了,有赋值型,浅copy,深copy。主要是区别复制后,其中一个的改变,对另一个产生的影响。
字典 如:{‘name‘:‘lebron‘,1:23,‘western‘:{ ‘laker‘:{ } } }
特点:1) 可变的无序的集合,可以增删查改;2) 采用的是 key-value 的存储方法,正如第一点无序,所以查找都是通过Key值;3) 字典里可以嵌套字典,做练习时用来做了四级菜单;4) 查找快速,顾名思义。
1 #Author: Happy yu 2 3 cavaliers={‘141001‘:‘lebron‘,‘141002‘:‘love‘,‘141003‘:‘kervor‘} 4 5 #字典的keys 6 ## print(cavaliers.keys()) 7 #字典的values 8 ## print(cavaliers.values()) 9 10 #增 11 ## cavaliers[‘141004‘]=‘irving‘ ##增加一个 12 ## cavaliers.setdefault(‘141004‘,‘irving‘) ## key不重复时,功能同上 13 ## cavaliers.setdefault(‘141001‘,‘irving‘) ## key重复时,不会覆盖值之前的值 14 15 #删 16 ## cavaliers.pop(‘141001‘) 17 ## del cavaliers[141001] 18 19 #改 20 ## cavaliers[‘141001‘]=‘irving‘ 21 ## lakers={‘181001‘:‘clarkson‘,‘181002‘:‘nance‘,‘141003‘:‘irving‘} 22 ## cavaliers.update(lakers) #合并两个字典,key重复的替换 也属于增 23 24 #查 25 ## ‘141005‘ in cavaliers #标准用法 26 ## cavaliers.get(‘141005‘) 27 ## cavaliers[‘141005‘] #若果不存在,程序会报错,不建议使用 28 print(cavaliers)
主要注意点 1)使用 update() 合并两个字典的方法来实现增和改;2)使用 setdefault() 的方法来实现增。
集合 如:定义时:set( [1,3,5,7,9] ) 或 {1,3,5,7,9}
特点:1) 无序性,无重复性,所以使用集合的特性轻松实现去重;2) 集合属于可变数据,但是集合里的元素不可变,这里的不可变指的时不能像列表和字典那样直接赋值替换;要想改变就要先删除这个数,然后再添加想改成的数。
3) 可以实现增和删的操作,4)有一些集合特有的操作,正如数学上的集合:并集,交集,差集和相对差集。
1 #Author: Happy yu 2 3 list_1=[1,3,4,5,7,9] 4 list_2=[2,4,6,8,9,10] 5 print(list_1,type(list_1)) 6 list_1=set(list_1) 7 print(list_1,type(list_1)) 8 list_2=set(list_2) 9 list_3=list_1|list_2 10 print(list_3) 11 #增 因为集合的无重复性 所以反复添加无效 12 #list_1.add(11) 13 #list_1.add(11) 14 #list_1.update(11) 是错误的 15 #list_1.update({11}) 正确的 16 # list_1.update((1,2,3,)) 正确的 17 #list_1.update([11,987]) 正确的 18 #list_1.update({‘1‘:123,‘2‘:12}) 只会将key添加进集合中 19 #print(list_1) 20 # 删 21 #print(list_1.pop()) #随机删除一个 22 #list_1.remove(3) #选择性删除 集合中没有就会报错 23 #list_1.discard(1) #选择性删除 集合中没有也不会报错 推荐使用 24 #print(list_1) 25 #集合的运算 26 #list_1.isdisjoint(list_2) 判断两个集合的交集是否为空集 27 #list_1.union(list_2) 将list_1 与 list_2 求并集 28 #list_1.union(list_2) ==> list_1|list_2(符号表示法) 29 #list_1.intersection(list_2) #对两个集合求交集 30 #list_1.intersection(list_2) ==> list_1& list_2(符号表示法) 31 #list_1.difference(list_2) 求list_1中 与 list_2中的差集 32 #list_1.difference(list_2) ==> list_1-list_2(符号表示法) 33 #list_1.symmetric_difference(list_2) 求list_1 和 list_2中的交集的补集 相对差集 34 #list_1.symmetric_difference(list_2) ==> list_1^list_2(符号表示法) 35 36 #list_1.issubset(list_3) #判断list_1是否是list_3的子集 等同于 list_3.issuperset(list_1) 37 #list_1.issubset(list_3) ==> list_1<=list_3(符号表示法) 38 #list_3.issuperset(list_1) ==> list_1>=list_3(符号表示法) 39 40 print(list_1.symmetric_difference(list_2))
文件
文件操作,就是用代码来实现你自己去文件里操作,当然没有人直接进文件操作灵活。所以对文件操作的步骤:1.打开文件;2读和写操作文件的内容;3关闭文件。文件中还有几个重要的概念:光标位置,字符,行等在文件中的作用。这个文件的链接是Alex博客中的关于文件的文档,关于文件的操作直接了当给出了易于理解的例子,一看就能明白如何用代码打开,读写和关闭文件等操作。
此外还有一些关于文件内容的具体操作,我提一些具体常用的操作 读操作:<1>readable() 判断文件是否可读 返回布尔值;<2>read()没有给参数时 和readall()一样读整个文件,如果有参数,它指的是字符个数;<3>readline() 是读文件的一行据;<4>文件中常用到读出一行,readline()和readlines()都有局限性,常用的就是直接使用文件句柄进行迭代读取。 写操作:<1>首先写操作有覆盖的情况,再打开文件时,一定注意默认都用‘a‘模式,不听就等着被炒鱿鱼吧!<2>写操作没有读那么复杂,就是write(),一般是写在末尾。在菜鸟教程中有关于文件的打开模式和主要的具体操作,还有个关于模式选择的流程图特别好用。建议先看Alex的例子和自动关闭文件的内容其他内容不用看了,具体操作看菜鸟教程中的详细介绍。文件操作的代码先不放在这,因为当时写的也不全,但是菜鸟里有详细的说明了。在下一节的作业中,两个地方用到了文件的读写,而且更加全面。
但是当你看完Alex和菜鸟里的内容,你还是无法在一个文件里自如的既读又写。你看到这有没有思考过了? 没有就现在想想啊,大哥。我当时就想到了这个方法,就是将要读修改的文件,同时新建一个文件用于写,读到需要修改的地方就写你要替换的内容,就这样一边读一边写。
1 不敢回看 2 左顾右盼不自然的暗自喜欢 3 偷偷搭讪总没完地坐立难安 4 试探说晚安 多空泛又心酸 5 低头呢喃 6 对你的偏爱太过於明目张胆 7 在原地打转的小丑伤心不断 8 空空留遗憾 多难堪又为难
1 #Author: Happy yu 2 3 #功能:实现对文件内容的修改,最好的方法是新建一个文件用来保存修改后的文件 4 # 思路:文件里的内容,一条条读出来,对字符串进行判断,使用字符串的修改方式修改后,一条条写进新文件 5 f=open(‘file_test2‘,‘r‘,encoding=‘utf-8‘) 6 f_new=open(‘file_test_back‘,‘w‘,encoding=‘utf-8‘) 7 8 for line in f: 9 if ‘左顾右盼不自然的暗自喜欢‘ in line: 10 line=line.replace(‘左顾右盼不自然的暗自喜欢‘,‘我的心借了你的光是明是暗‘) 11 f_new.write(line) 12 f.close() 13 f_new.close()
不敢回看
我的心借了你的光是明是暗
偷偷搭讪总没完地坐立难安
试探说晚安 多空泛又心酸
低头呢喃
对你的偏爱太过於明目张胆
在原地打转的小丑伤心不断
空空留遗憾 多难堪又为难
数据运算(菜鸟教程里有详细内容)
算术运算符 用来处理加减乘除等运算,只强调注意这三个用法:取整(//),求模(%),求幂(**)。
关系运算符 用来判断相等,大小于等情况,所以也叫比较运算符,主要用于条件判断。
赋值运算符 用来实现将运算结果直接赋值给操作数,如C语言中的自加加,不举例了链接里有详细的例子。
位运算符 用来实现数的二进制位的运算,这个在做底层直接对硬件操作的时候常用,想我以前学51单片机的时候没有不用的。不过用python我们很少会用来做硬件开发的,所以了解一下有就行,到时候真的要用,记住跟C语言一模一样。
逻辑运算符 用来关联同时判断几个条件,一般和比较运算符一起使用。这里说明一下,菜鸟教程的表格中(a and b 返回b)就不要管了,我只关心布尔值,非0 为True。
成员运算符 用于判断一个数据是否在一个数据里,或者用于迭代,返回的是一个布尔值,常用来判断字符串,元组和列表等。菜鸟教程中只有判断是否在列表中的,所以补充一个在字符串中的例子:
1 #Author: Happy yu
2 s=‘Happy is very happy‘
3 s1=‘is‘
4 if s1 in s:
5 print(‘s中含有{}‘.format(s1))
6 else:
7 print(‘s中不含{}‘.format(s1))
身份运算符 我也没搞清在那会用到,但是学了之前很多数据的操作时,你有没有发现 isdigit(),isalnum()这些函数的使用,所以只要看到is开头的操作就是用判断其身份的,这里 isdigit()是超级常用的,所以必须记住它。
运算符的优先级 也比较多,也不用去记了,就要用到时来看看就好,用多了就记住了。
程序结构
条件判断:Python语句通过一条或多条的执行结果(布尔值),来执行代码块。条件判断的链接也是在菜鸟教程中有很详细全面的内容,里面对条件判断的结构,简单的条件判断例子(推测狗狗年龄),以及条件嵌套,还有条件判断的常用运算符,当通过一条执行一般只会用到比较运算或成员运算,如通过多条执行结果就会搭配逻辑运算一起使用。
循环语句结构:在链接里对Python有的循环语句都有说明。1)在while 循环语句中,特别注意一点就是 while...else...结构的语句,C语言中没有这么用过,但是确实会极大简化程序的代码。但是循环体始终只有在while判断的语句块中才有循环,如果执行else,说明循环条件已经不满足了,循环结束,else中的语句块只执行一次。注意:但是当我们使用break跳出循环时,是不会执行else语句中的内容的。看下面这个例子
1 #Author: Happy yu 2 count=0 3 while count<10: 4 count+=1 5 print(count,‘count=‘,count) 6 if count==6: 7 break 8 else: 9 print(‘count已经等于10了!‘) 10 11 #最后一句不会打印出来,但是把条件判断的语句块注释掉试试呢
2)for 语句,用来迭代或则叫做遍历循环,也同样有for...else...结构语句,所以也同样有上述的问题,并且在教程里用一个找质数的方法来说明了这个问题,这个质数查找方法比在用C怨言写简洁很多啊。
关于continue和break的使用就不多说了,但是出现了个pass,这个pass和以前给变量占位的null有异曲同工之妙啊,这是个代码占位的,用来编写程序用来搭结构时用的。
编码
编码问题是一个特别重要的内容,有的文章写得特别复杂,就看看Alex的需知里的1,3和最下面的图就好,我也不知道为什么说是只有在py2中用。这里有张发展的图,看了我就好说重点了。
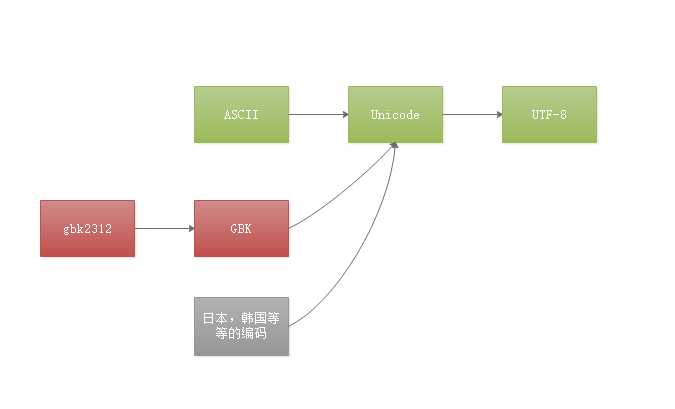
图1.4
美国人发明了计算机,他们用ASCII码就能表示所有的字符了,当中国和其他日本,韩国等国家也用电脑,可是ASCII码我们不能用,我们就自己编写了自己的编码,他们也编写他们的码,可是这样我们编写的软件就不能在日本用了,打开会出现乱码呀。这个时候国际组织就统一编码就有了nicode,所以unicode是兼容所有码的,并且所有的码都使用两个字节,但是问题又来了,美国人不高兴了,ASCII码他只用一个字节,现在内存会消耗以前的两倍。所以就又有了UTF-8码,也是现在主流使用的,英文字符占一个字节,中文要用3个字节。好像对我们来说很不好啊。anyway 不说了。下面把Alex中的那张图拷过来讲,方便一点。
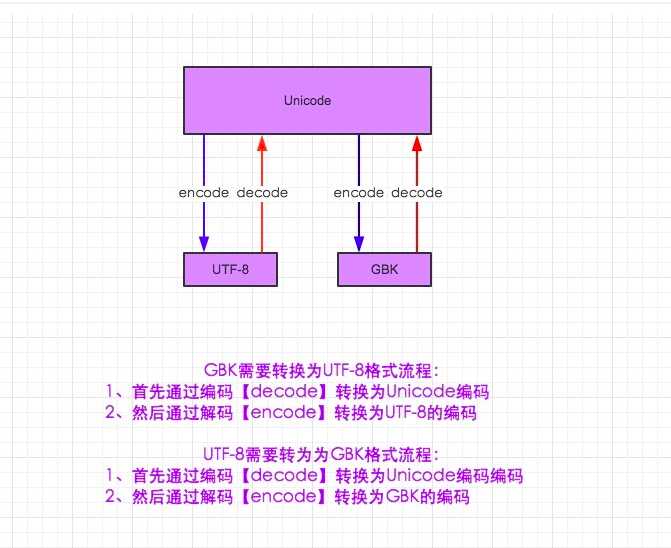
图1.5
所有的转码都要经过Unicode(原因上面讲过了),用我们的GBK来说明,对我们来说本来是GBK,为了去UTF-8,我们要先解码到Unicode,所以decode(‘gbk‘),括号里是‘GBK‘,是告诉编译器原本是什么码制,才能正确解码。然后再编码,我们的目标是UTF-8,所以用encode(‘utf-8‘),同理,要告诉编译器要编成什么码制。
1 #Author: Happy yu 2 s=‘你好‘ #python3 默认是 unicode 3 import sys 4 print(sys.getdefaultencoding()) #Return the current default string encoding used by the Unicode 5 6 print(s.encode(‘utf-8‘)) #unicode 只能编码,py3中encode会把string变成bytes 7 print(s.encode(‘utf-8‘).decode(‘utf-8‘)) #py3中decode会把bytes变成string 8 print(s.encode(‘utf-8‘).decode(‘utf-8‘).encode(‘gbk‘)) #GBK码制
这里有个根据当前文件编码,我用Pycharm是默认用的utf-8,当我改成GBK,文件的第一行也应该告诉编译器这个文件是用GBK编码。但是s的编码并不会随着文件编码改变,它始终都是unicode的编码。
最后对编码再做个小结,1)所有的转码都必定会经过unicode。
2)decode() 要说明之前的码制
3)encode()要说明要转为什么码
总结:我不再对上面的内容进行总结了,因为我写的内容本身就很精炼了。这也是第一篇内容,思维导图只是一个雏形,因为毕竟这个不像学教材有写好的目录,要一步步不走不断的修正。我的同学说我的博客写得还是太细,不过写这个博客还是花了很多时间,进度太慢了。希望有大家提建议,我会好好参考,进行修改。
以上是关于unit 1.基础语法的主要内容,如果未能解决你的问题,请参考以下文章