3 使用selenium模拟登录csdn
Posted xiaojieshisilang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3 使用selenium模拟登录csdn相关的知识,希望对你有一定的参考价值。
之前通过F12开发者模式调试,获取网站后台服务器验证用户名和密码的URL之后,再构造post数据的方式会存在一个问题,就是对目标网站的验证机制不明确,构造post数据除了用户名和密码之外,还可能有更复杂的协议。比如csdn的fkid机制,见上一篇博文。
2 模拟登录_Post表单方式(针对chinaunix有效,针对csdn失效,并说明原因)
使用selenium的好处是,能够直接模拟浏览器进行操作,然后填入用户名和密码,在登录成功以后,再把cookie保存下来。比之前的方式
urllib.request.Request(url,postdata)
好的太多。但是selenium有一个大问题,就是无法定位页面元素或者定位了以后无法与页面进行交互。笔者通过实战,总结出了两大杀器
- WebDriverWait能够定位元素
- 上一步能够定位元素以后,但是页面可能还属于不能交互的状态。这时再time.sleep(3)
就这样问题解决了。
使用selenium模拟登录csdn的代码
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 13 16:13:52 2018
@author: a
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
import time
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument(‘--headless‘)#无界面模式
#下面的代码是错误的使用方式
#browser = webdriver.Chrome(chrome_options=chrome_options,executable_path = "C:Program Files (x86)GoogleChromeApplicationchrome.exe")
#下面的代码是使用无界面模式
#browser = webdriver.Chrome(chrome_options=chrome_options)
browser = webdriver.Chrome()
print("xiaojie")
url="https://passport.csdn.net/account/login"
try:
browser.get(url)
target=browser.find_element_by_xpath(‘/html/body/div[3]/div/div/div[2]/div/h3/a‘)
print("target:",target)
target.click()
locator=(By.ID,‘username‘)
WebDriverWait(browser, 20, 0.5).until(EC.presence_of_element_located(locator))
username=browser.find_element_by_id(‘username‘)
print ("username:",username)
time.sleep(3)
username.clear()
username.send_keys(‘[email protected]‘)
password=browser.find_element_by_id(‘password‘)
print ("password:",password)
password.clear()
password.send_keys(‘XXXX‘)
submit=browser.find_element_by_xpath(‘//*[@id="fm1"]/input[8]‘)
print ("submit:",submit)
submit.click()
except Exception as e:
print (e)
finally:
print("over")
None
#browser.close()
必须按照Python3网络爬虫实战开发中安装好chrome浏览器对应的chromedriver。
下面是全部实验过程(不感兴趣的可以忽略)
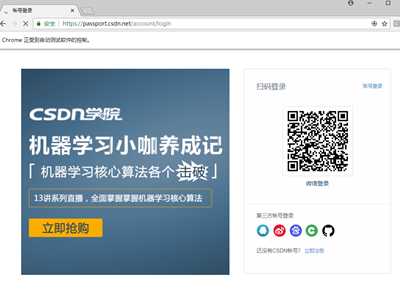
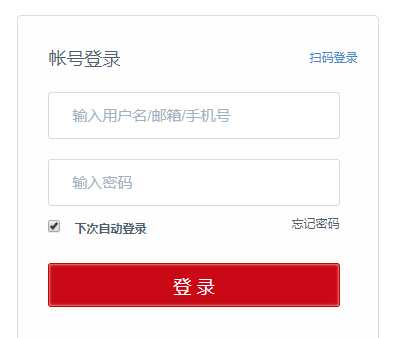
可以看到,要先点击账户登录,待页面刷新以后,再输入用户名、密码,点击登录按钮。
在点击账户登录以后,页面刷新的过程如果比程序执行的过程慢,就会导致你使用spyder的调试模式,能够正常登录,但是直接运行总是报出的错误:
Message: invalid element state: Element is not currently interactable and may not be manipulated
参照网上一些人的做法,使用WebDriverWait以后,并且能够使用下面的语句定位出用户名的输入框:
username=browser.find_element_by_id(‘username‘)
print ("username:",username)
但是,执行下面:
username.clear()
还是会报错。这就说明,即使WebDriverWait定位到页面元素,也一时不能交互。于是添加上:
time.sleep(3)
便解决了问题。
后续定位密码输入框以及登录按钮,并且产生交互,就不需要WebDriverWait和time.sleep了。因为用户名输入框和这两者是在一个页面。当用户名输入框定位和操作的问题解决了,后面的就自然也解决了。
以上是关于3 使用selenium模拟登录csdn的主要内容,如果未能解决你的问题,请参考以下文章