互联网广告系统综述七特征
Posted zhangbojiangfeng
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了互联网广告系统综述七特征相关的知识,希望对你有一定的参考价值。
互联网广告系统综述七特征
https://blog.csdn.net/guohecang/article/details/52858550
声明:
1)该博文是整理自网上很大牛和专家所无私奉献的资料的。具体引用的资料请看参考文献。具体的版本声明也参考原文献
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应,更有些部分本来就是直接从其他博客复制过来的。如果某部分不小心侵犯了大家的利益,还望海涵,并联系老衲删除或修改,直到相关人士满意为止。
3)本人才疏学浅,整理总结的时候难免出错,还望各位前辈不吝指正,谢谢。
4)阅读本文需要互联网广告业的基础(如果没有也没关系了,没有就看看,当做跟同学们吹牛的本钱)。
5)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。请直接回帖,本人来想办法处理。
描述完系统,模型等方面,就到了花费互联网广告算法工程师的最大精力的点了,就是特征工程,这是一个持久战斗的点。
流程复杂,而且各种机器学习的方法都可以在这里用上,有效果,有产出,有指标。当然,玩砸的也不少,打击总是很多的。
前面那么多的工作,都可以在系统搭建完成后,变化都不会特别大,剩下还可以变化的,就是预估ctr的时候的那个x了,这个x就是由特征组成,对ctr预估起到决定性作用的是选用的特征。
下面就特征工程的一些相关的点说一下。
特征工程真是艰苦的战役。包括想特征,特征生成,分析特征,特征加工,离线指标评估,线上效果评估,特征上线等,中间夹杂着各种工作。
下面一一来说一下吧。
什么样的特征适合用来预估ctr?这个问题是很多广告算法工程师的需要考虑的。
机器学习算法最多会大谈模型,对于特征的讨论很少涉及。真正的应用中,多数数据挖掘工程师的工作都是在想特征,验证特征。
想特征是一个脑力加体力的活,需要不少的领域的知识,更让人郁闷的是,工业界并没有一整套想特征的办法,工业界有的只是验证特征的办法。对于互联网广告业,就简单说说通用特征怎么来的吧。
首先说年龄这个特征,怎么知道它跟点击率有关系?现在直观的解释是,年轻人普遍喜欢运动类的广告,30岁左右的男人喜欢车,房子之类的广告,50岁以上的人喜欢保健品的广告。可以看到,选择年龄作为特征的理由是基于对各个年龄段的人喜欢的不同类型的东西的一个粗略的划分,是一个很主观的东西。
再说性别这个特征,直观的感觉是,男性普遍喜欢体育类的,车类的,旅游类广告,女性普遍喜欢化妆品,服装类的广告。这也可以看到,选择性别作为特征也是基于相似的理由,就是认为男性和女性大体会喜欢不同的东西。
对于地域这个特征,这下就学问多了,华南的人在比较喜欢动漫和游戏,华北的人喜欢酒品和烟?
在广告方面的特征,广告的图片大小,广告前景色背景色真的能影响人的点击吗?这其实都是一种猜测。图片里面是一个明星还是一个动物之类的因素也可以考虑。
总之,想特征的这个事情基本没多大谱,只能天南地北地想象,还要多了解各行各业的知识,以便想到更多的特征,哪怕某个特征跟人关系并不大,也得好好验证一番。这基本上跟男人为回家晚想借口一样,得有借口要想着怎么解释得好听点,没借口就要想借口。
想到了特征,就要分析、验证和进行判断。
1.2分析特征
再说年龄这个特征,怎么知道它跟点击率有关系?
只好去看看每个年龄段的人在各个广告上面的表现,比如经过跑数据分析,发现20~30岁之间的男性用户对车、房子之类的广告点击率比较高,而50岁以上的用户对保健品的广告点击率比较高。这就有了区分性了,说明年龄这个特征是对点击率是有预测能力的。
再说性别这个特征,去把每个性别对各个广告的点击率跑出来。根据结果,发现男性用户体育类的,车类的广告点击率比较高;而女性用户则对化妆品,服装类的广告点击率比较高。这就说明了性别这个特征对点击率是有预测能力的,因为有区分性。
实际分析过程中发现,性别这个特征比较有效,手机平台这个特征也比较有效,地域和年龄这两个特征有一定效果,但没有前两个那么明显,跟他们的使用方式可能有关,还需要进一步挖掘。
实际使用中也发现,实时广告ctr这个特征也很有效,这个特征的意思就是当前的广告正在投放,已经投放了一部分了,这部分的点击率基本可以认为是这个广告的点击率了,也可以认为是这个广告的质量的一个体现,用来预估一个流量的ctr是很有效的。
1.3特征加工
想到了特征,分析过了,发现是有效的,就想直接上线?没那么容易,对于很多特征来说,还是需要经过加工的,因为很多特征在加工后在线上的效果提升都很明显(当然,没加工过的特征也能起到一定的效果,只是没有发挥最大作用而已)。
特征加工目前用到三个主要的工艺:二值化,交叉,平滑,离散化
1.3.1二值化
假设暂定有实时广告ctr,用户年龄,性别三个特征想要使用。
反馈ctr是一个浮点数,直接作为特征是可以的,假设1号特征就是反馈ctr。
对年龄来说就不是这样了,因为年龄不是浮点数,而且年龄的20岁跟30岁这两个数字20,30大小比较是没有意义的,相加相减都是没有意义的,在优化计算以及实际计算ctr是会涉及这两个数字的大小比较的。如w.x,在w已经确定的情况下,x的某个特征的值是20,或者30,w.x的值相差是很大的,哪怕用逻辑化公式再比较,得到的值也是比较大的,但是往往20岁的人跟30岁的人对同一个广告的兴趣差距不会那么大。解决这样的情况的方法就是,每个年龄一个特征,如总共只有20岁到29岁10种年龄,就把每个年龄做一个特征,编号是从2到11(1号是广告的反馈ctr),如果这个人是20岁,那么在编号为2的特征上的值就是1,3到11的编号上就是0。这样,年龄这一类特征就有了10个特征,而且这10个特征就是互斥的,这样的特征称为二值特征。
对于性别来说也是,两种性别,分别编号到12、13号特征上就完成了二值化了。
1.3.2交叉
二值化看起来就能解决两个特征的差没有意义的问题了,但是够了吗?
比如一个人是20岁,那么在编号为2的特征上面,它一直都是1,对篮球的广告是1,对化妆品的广告也是1,这样训练的结果得到的编号为2的权重的意义是——20岁的人点击所有的广告的可能性的都是这个权重,这样其实是不合理的。
有意义的应该是,这个20岁的人,当广告是跟体育相关的时候,它是一个值;当广告跟保健品相关的时候,它又是另一个值这样看起来才合理。
因为特征需要根据人和广告的关系不断变化,才能使得一个人对不同的广告预估出不同的ctr来,如果特征不能跟着广告变化,那么一个用户对所有广告都预估出同一个值来,也是不行的。
基于跟上面同样的道理,性别这个特征也是一样的,假如也做了上面的离散化操作,编号是12和13,12是男性,13是女性。这样的话,对于一个男性/体育广告组合来说,编号12的特征值为1,男性/化妆品的组合的编号12的特征值也是1。这样也是不合理的,主观看过去都不合理。
怎么做到合理呢?以上面的性别的例子来说。编号12的特征值不取1,取值为该广告在男性用户上面的点击率,如对于男性/体育广告的组合,编号12的特征的值为男性在体育广告上面点击率,这样,编号为12的特征就变成了一个浮点数,这个浮点数的相加减是有意义的,这个浮点数的值越大,意味着这个性别的用户对该广告越感兴趣。这样过后,同一个用户,对不同的广告主,编号为12的位置的值都不一样了。而且这样可以不用编号为13的特征了,直接拿性别/广告的组合的点击率作为编号12的特征的值,两种性别都考虑到了。其实也就是说,经过组合后,年龄和性别各自又变回了一个特征,这个特征的值会随着不同的广告变化的,这个值跟广告有关。
这样的做法称为特征的交叉,现在就是性别跟广告的交叉得到的特征值。还有很多其他的方式可以进行交叉,目前应用起来效果比较好的就是广告跟性别的交叉特征,广告跟年龄的交叉特征,广告跟手机平台的交叉特征,广告跟地域的交叉特征。如果做得比较多,可能会有广告主(每个广告都是一个广告主提交的一个投放计划,一个广告主可能会提交多个投放计划)跟各个特征的交叉。
1.3.3平滑
经过上面的处理,很多特征变成了交叉的特征,而且特征值是一个广告过去一段时间的点击率(ctr)。
这个值是一个浮点数,计算的方式是交叉特征下的历史点击数/历史展示数,用字母表达是click/pv。
这个往往是很多问题的,如广告只投放了一次,就被点击了一次,点击率就是100%了,这个值是相当大的,只是肯定不可信,因为点击率一般百分之几就不得了了;又比如广告投放了100次,点击了1次,点击率1%,这样又可信了吗?假如pv为0呢?难道点击率就无穷大?
关于这个问题雅虎出了个paper,能很好地解决这个问题,是用贝叶斯学派的方法的。
首先两个假设。
假设一,所有的广告有一个自身的ctr,这些ctr服从一个Beta分布。
假设二,对于某一广告,给定展示次数时和它自身的ctr,它的点击次数服从一个伯努利分布 Binomial(I, ctr)。
如果用r表示点击率,I表示展示,C表示点击。这两个假设可以用下面的数学表示。
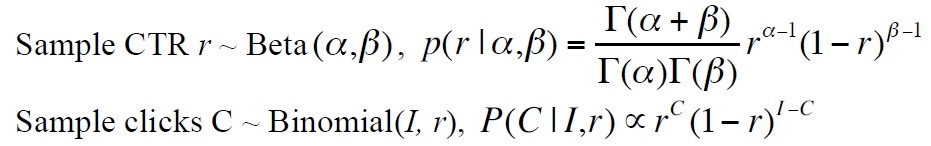
根据这两个假设,假如已经有了很多个广告投放数据,I1,C1,I2,C2……In,Cn,就可以根据这些投放数据列出似然函数
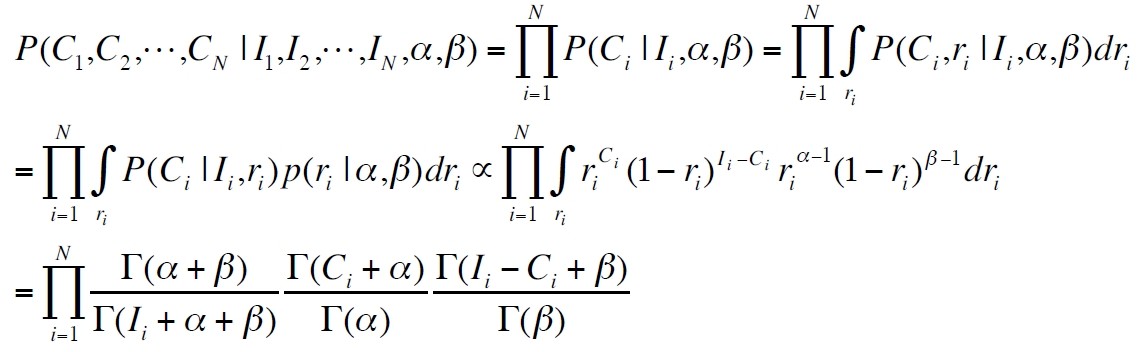
求解这个极大似然问题,得到两个参数alpha和beta,然后每个广告的点击率就可以利用这两个参数计算后验ctr(平滑ctr)了,公式如下:
r=(C + alpha) / (I + alpha + beta)
有了这个技术,上面说的那些交叉特征的特征值都用这个技术平滑了一下,就避免了出线1.0或者正无穷这种这么病态的特征值,因为一般都是很小的特征值。
事实证明,平滑技术很有效。
1.3.4离散化
假设还是实时广告ctr,用户年龄,性别三个特征,经过上一次交叉和平滑,现在得到了3个特征值,实时广告ctr编号为1,年龄与广告交叉特征编号为2,性别与广告交叉特征编号为3。现在就三个特征了了。
这三个特征直接训练logisticregression模型,可以吗?可以的,但是线上效果并不好。为啥?这倒是个问题。看看下面的解释。
如编号为1的那个特征,就是广告实时的ctr,假设互联网广告的点击率符合一个长尾分布,叫做对数正态分布,其概率密度是下图(注意这个是假设,不代表真实的数据,从真实的数据观察是符合这么样的一个形状的,好像还有雅虎的平滑的那个论文说它符合beta分布)。
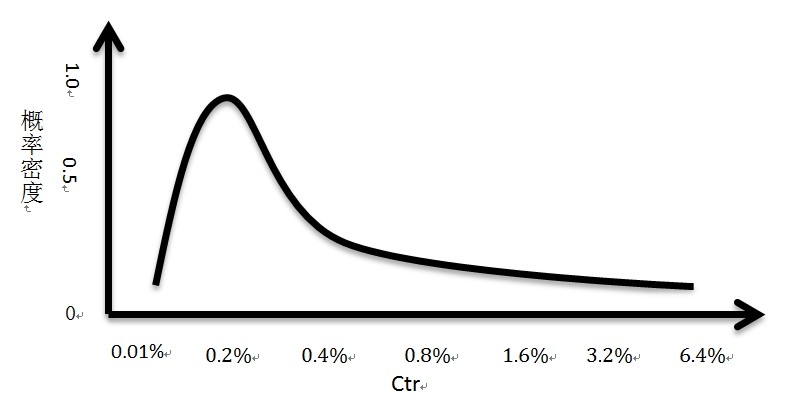
对于不同档次的点击率来说,重要程度是不一样的,比如在接近对数正态分布的那个拱附近(0.2%左右)的点击率,由于这类型的情况比较多,重要程度并不高,特征的权重需要小一点;但是对于接近那个长尾的那些点击率来说,这种情况比较少,重要程度高,特征的权重也应该大一点。下面是重要程度分布图。
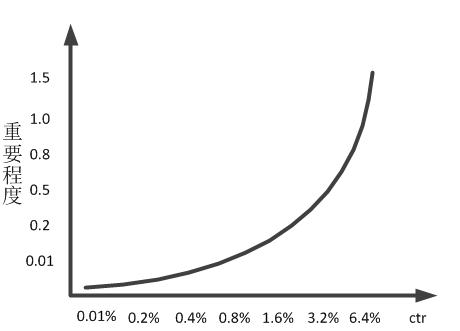
如果直接用ctr的那个浮点值作为特征,训练后,对这个特征,只有一个权重,没办法把重要程度区分开来,所以效果不好。
当然,点击率与重要程度不一定是完全的正相关性,有可能值越大特征越重要,也有可能值增长到了一定程度,重要性就下降了。这样的就是非线性的情况,利用一个线性的方式去拟合,效果自然打折扣。
解决的方法就是把ctr那个浮点值离散化。
百度有科学家提出了对连续特征进行离散化。他们认为,特征的连续值在不同的区间的重要性是不一样的,所以希望连续特征在不同的区间有不同的权重,实现的方法就是对特征进行划分区间,每个区间为一个新的特征。
具体实现是使用等频离散化方式:1)对于上面的编号为1的那个特征,先统计历史记录中每条展示记录中编号为1的特征的值的排序,假设有10000条展示记录,每个展示记录的这个特征值是一个不相同的浮点数,对所有的展示记录按照这个浮点数从低到高排序,取最低的1000个展示记录的特征值作为一个区间,排名1001到2000的展示记录的特征值作为一个区间,以此类推,总共划分了10个区间。2)对特征编号重新编排,对于排名从1到1000的1000个展示记录,他们的原来编号为1的特征转变为新的特征编号1,值为1;对于排名是从1001到2000的记录,他们的原来编号为1的特征转变为新的特征编号2,值为1,以此类推,新的特征编号就有了1到10总共10个。对于每个展示记录来说,如果是排名1到1000的,新的特征编号就只有编号1的值为1,2到10的为0,其他的展示记录类似,这样,广告本身的ctr就占用了10个特征编号,就成为离散化成了10个特征。
另外的两个交叉ctr也是用这样的方式离散化成了10个特征,那样总共就有了30个特征。训练的结果w就会是一个30维的向量,分别对应着30个特征的权重。
实际的应用表明,离散化的特征能拟合数据中的非线性关系,取得比原有的连续特征更好的效果,而且在线上应用时,无需做乘法运算,也加快了计算ctr的速度。
1.4离线指标评估
特征想到了,分析完了,加工过了,就需要出些跟线上应用相关的东西流量,就是离线指标。
离线指标可以先评估单特征AUC,就是根据这个特征的取值情况,就是前面离散化之前的那个浮点值,跟真实的点击数据组合成一对数据,去计算AUC,如果AUC大于0.6,就已经算是一个很不错的特征了;如果很接近0.5,说明识别能力不强,还要继续加工或者放弃。
为了跟线上情况一致,要做的事情就是跟线上目前情况一样,先训练一个模型,再把测试样本经过模型,得到一堆预估的ctr,再根据这些ctr很真实点击情况对比,计算一些指标。
评估模型效果的方法有很多,主要有以下两个:
1. AUC,从排序的角度评估模型预估效果;
2. MAE(Mean Absolute Error)/MSE(Mean Squared Error),从准确率的角度评估模型预估效果;
AUC在其他的博文里面详细描述了,主要比较正负样本的序关系。
MAE就是看预估的ctr与真实的ctr的差的情况,估得越准确越小,MSE同理。
1.4线上效果评估
离线评估完后,只是对这个特征有了个期待,但是决定特征能否上线的还是在线的A/B Test,即随机选取两部分线上同质流量,一部分用基准模型A进行实际投放,一部分用加了新特征的模型B进行投放。如果后者对在线业务指标(如点击率、千次展现收益等)有正向效果,就认为是好模型,特征就是好特征,这个特征就可以上线了。
在A/B Test过程中,的如果模型B业务指标一直比模型A好,模型B就可以全量上线了,这样,新特征也全量上线了。到这,一个特征的上线过程就描述完了
新的业务策略上线同样也是用这种方法。
1.6特征生成
在前面说特征生成的时候,还是挺靠前的,但是为了描述的流畅性,就放到了最后。
前面一直在说想特征,分析,加工啥的,就是没有说一个事情,特征怎么从离线数据中获取。其实不是这个工作不重要,而是这个工作又杂又繁琐。
一、先说实时广告ctr吧,其实这个是整整一个项目的结果。
步骤如下:
1、广告投放平台投放广告,结算系统产生投放日志和点击日志。
2、日志发送到收集系统。
3、实时计算程序实时读取日志,解析,获取其中的广告信息。
4、按照时间窗口进行统计pv,click。
5、写入线上存储器提供读取。
6、线上实时进行加工。
二、再说交叉特征
对于性别/广告主交叉特征。
这个也要根据实时的投放日志,根据用户id,从日志/数据仓库获取用户性别,再统计每个广告主在每个性别上的点击率,可以经过一些加工,写入线上存储器供线上程序读取。
上面两点,看起来简简单单几句话,却跨域了4个部门,需要各种的沟通合作,才能得到线上的数据。广告投放平台与结算系统,日志收集与实时计算,线上存储器,分别是由三个部门提供的服务。完成这些工作需要大量的沟通工作。
数据生成后验证正确性是很耗时间的,因为只能在某个时间点读出来,再根据日志里面时间戳去统计,两个对比,看看数据是否正确。
验证工作耗费比较大的精力,还要比较多的精力去调试,保证整个项目各个模块的稳定。还要根据其他一些数据建立数据监控。
特征工程还会遭遇其他方面的问题,如某个系统出问题,如结算系统,发送日志错误了,重复发送了,就会导致数据监控方面的报警。还容易遇到的问题是,线上存储器空间不足,导致有些特征导入失败,线上使用也出了问题等等。一时半会是说不完的,工程上的问题也会困扰算法的优化工作。
用linkin的ppt上的一页来说吧。

大致情况就是这样了。
一旦搭上特征工程这个贼船,就没得脱身的了。
没见到哪个书好好描述一下这个情况:数据不光变化,还是不稳定的变化,随时出现的脏数据让人猝不及防。
模型不断在更新,但是要选择一个好的模型,也是非常难的,有时候得人工介入。上面那页PPT真是“满纸荒唐言,一把辛酸泪”。不是身在其中,又如何体会费老大的劲搞出来的一个特征,在线上怎么都没有产生预期的效果,各种扒拉日志与分析;一个月也看不到什么像样的指标提升的尴尬事更是屡见不鲜。
致谢
多位互联网博主如@Rickjin等。
多位Linkedln研究员无私公开的资料。
参考文献
[1] ComputationalAdvertising: The LinkedIn Way. Deepak Agarwal, LinkedIn Corporation CIKM
[2] http://www.flickering.cn/uncategorized/2014/10/%E8%BD%AC%E5%8C%96%E7%8E%87%E9%A2%84%E4%BC%B0-2%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92%E6%8A%80%E6%9C%AF/腾讯的广点通的技术博客《逻辑回归技术》
文章来源:http://blog.csdn.net/mytestmy/article/details/40933235
以上是关于互联网广告系统综述七特征的主要内容,如果未能解决你的问题,请参考以下文章