第二十七篇 玩转数据结构——集合(Set)与映射(Map)
Posted xuezou
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第二十七篇 玩转数据结构——集合(Set)与映射(Map)相关的知识,希望对你有一定的参考价值。
1.. 集合的应用
-
集合可以用来去重
-
集合可以用于进行客户的统计
-
集合可以用于文本词汇量的统计
2.. 集合的实现
-
定义集合的接口
-
Set<E> ·void add(E) // 不能添加重复元素 ·void remove(E) ·boolean contains(E) ·int getSize() ·boolean isEmpty()
-
集合接口的业务逻辑如下:
-
public interface Set<E> { void add(E e); void remove(E e); boolean contains(E e); int getSize(); boolean isEmpty(); }
- 用二分搜索树作为集合的底层实现
-
public class BSTSet<E extends Comparable<E>> implements Set<E> { private BST<E> bst; // 构造函数 public BSTSet() { bst = new BST<>(); } // 实现getSize方法 @Override public int getSize() { return bst.size(); } // 实现isEmpty方法 @Override public boolean isEmpty() { return bst.isEmpty(); } // 实现contains方法 @Override public boolean contains(E e) { return bst.contains(e); } // 实现add方法 public void add(E e) { bst.add(e); } // 实现remove方法 public void remove(E e) { bst.remove(e); } }
- 用链表作为集合的底层实现
-
public class LinkedListSet<E> implements Set<E> { private LinkedList<E> list; // 构造函数 public LinkedListSet() { list = new LinkedList<>(); } // 实现getSize方法 @Override public int getSize() { return list.getSize(); } // 实现isEmpty方法 @Override public boolean isEmpty() { return list.isEmpty(); } // 实现contains方法 @Override public boolean contains(E e) { return list.contains(e); } // 实现add方法 @Override public void add(E e) { if (!list.contains(e)) { list.addFirst(e); } } // 实现remove方法 @Override public void remove(E e) { list.removeElement(e); }
- 用二分搜索树实现的集合与用链表实现的集合的性能比较
-
import java.util.ArrayList; public class Main { public static double testSet(Set<String> set, String filename) { long startTime = System.nanoTime(); System.out.println(filename); ArrayList<String> words = new ArrayList<>(); if (FileOperation.readFile(filename, words)) { System.out.println("Total words: " + words.size()); for (String word : words) { set.add(word); } System.out.println("Total different words: " + set.getSize()); } long endTime = System.nanoTime(); return (endTime - startTime) / 1000000000.0; } public static void main(String[] args) { String filename = "pride-and-prejudice.txt"; BSTSet<String> bstSet = new BSTSet<>(); double time1 = testSet(bstSet, filename); System.out.println("BSTSet, time: " + time1 + " s"); System.out.println(); LinkedListSet<String> linkedListSet = new LinkedListSet<>(); double time2 = testSet(linkedListSet, filename); System.out.println("LinkedListSet, time: " + time2 + " s"); } }
- 输出结果:
-
pride-and-prejudice.txt Total words: 125901 Total different words: 6530 BSTSet, time: 0.109504342 s pride-and-prejudice.txt Total words: 125901 Total different words: 6530 LinkedListSet, time: 2.208894105 s
- 通过比较结果,我们发现,用二分搜索树实现的集合的比用链表实现的集合更加高效
3.. 集合的时间复杂度分析
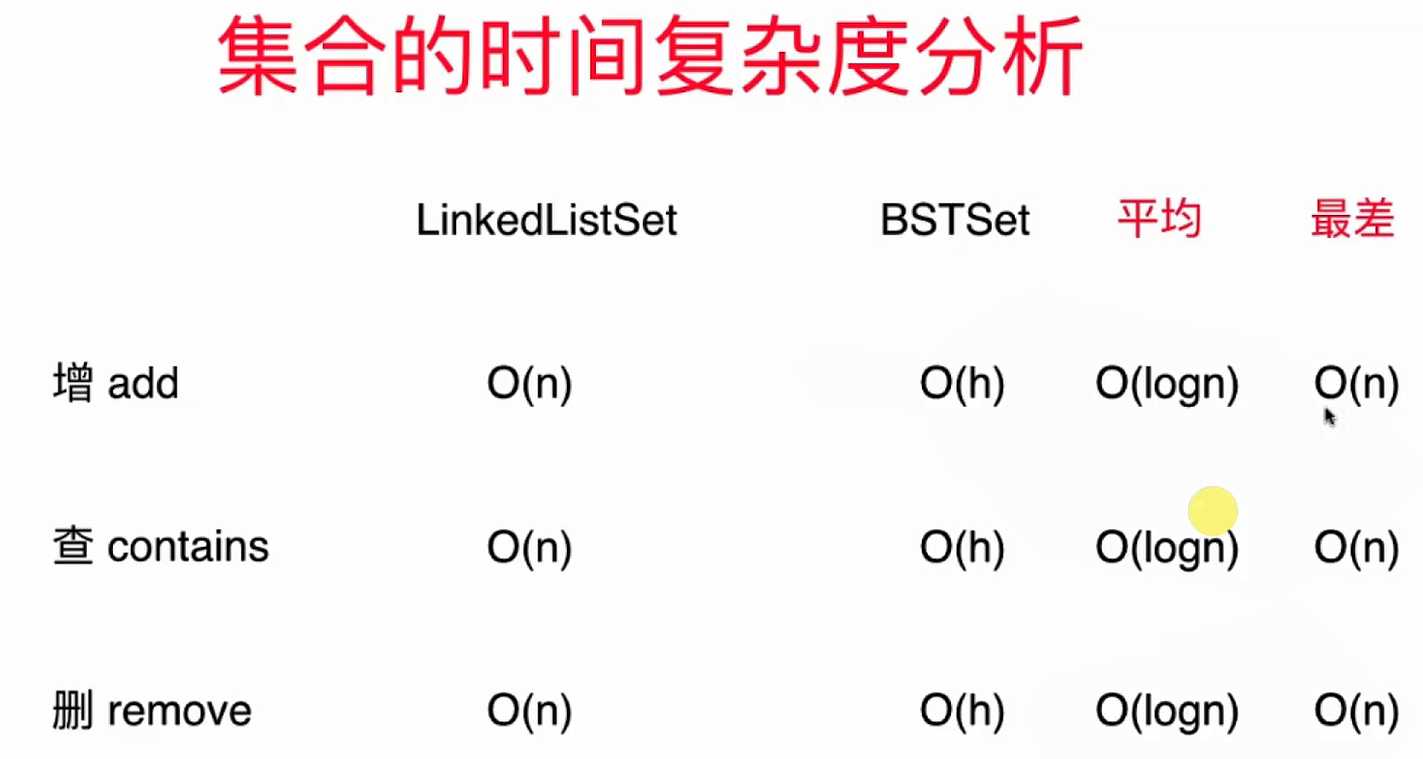
- 上图中"h"是二分搜索树的高度
- 当二分搜索树"满"的时候,性能是最佳的,时间复杂度为O(logn);当二分搜索树退化为链表的时候,性能是最差的,时间复杂度为O(n)

4.. 映射(Map)
- 映射是存储(键,值)数据对的数据结构(Key, Value)
- 根据键(Key),寻找值(Value)
5.. 映射的实现
- 定义映射的接口
-
Map<K, V> ·void add(K, V) ·V remove(K) ·boolean contains(K) ·V get(K) ·void set(K, V) ·int getSize() ·boolean isEmpty()
- 映射接口的业务逻辑如下
-
public interface Map<K, V> { void add(K key, V value); V remove(K key); boolean contains(K key); V get(K key); void set(K key, V value); int getSize(); boolean isEmpty(); }
- 用链表作为映射的底层实现
-
public class LinkedListMap<K, V> implements Map<K, V> { private class Node { public K key; public V value; public Node next; public Node(K key, V value, Node next) { this.key = key; this.value = value; this.next = next; } public Node(K key) { this(key, null, null); } public Node() { this(null, null, null); } @Override public String toString() { return key.toString() + " : " + value.toString(); } } private Node dummyHead; private int size; // 构造函数 public LinkedListMap() { dummyHead = new Node(); size = 0; } // 实现getSize方法 @Override public int getSize() { return size; } // 实现isEmpty方法 @Override public boolean isEmpty() { return size == 0; } private Node getNode(K key) { Node cur = dummyHead; while (cur != null) { if (cur.key.equals(key)) { return cur; } cur = cur.next; } return null; } // 实现contains方法 @Override public boolean contains(K key) { return getNode(key) != null; } // 实现get方法 @Override public V get(K key) { Node node = getNode(key); // return node == null ? null : node.value; if (node != null) { return node.value; } return null; } // 实现add方法 public void add(K key, V value) { Node node = getNode(key); if (node == null) { dummyHead.next = new Node(key, value, dummyHead.next); size++; } else { node.value = value; } } // 实现set方法 public void set(K key, V newValue) { Node node = getNode(key); if (node == null) { throw new IllegalArgumentException(key + " doesn‘t exist."); } else { node.value = newValue; } } // 实现remove方法 public V remove(K key) { Node node = getNode(key); if (node == null) { throw new IllegalArgumentException(key + " doesn‘t exist."); } Node prev = dummyHead; while (prev.next != null) { if (prev.next.key.equals(key)) { break; } prev = prev.next; } if (prev.next != null) { Node delNode = prev.next; prev.next = delNode.next; delNode.next = null; size--; return delNode.value; } return null; } }
- 用二分搜索树作为映射的底层实现
-
public class BSTMap<K extends Comparable<K>, V> implements Map<K, V> { private class Node { private K key; private V value; private Node left; private Node right; // 构造函数 public Node(K key, V value) { this.key = key; this.value = value; this.left = null; this.right = null; } // public Node(K key) { // this(key, null); // } } private Node root; private int size; // 构造函数 public BSTMap() { root = null; size = 0; } // 实现getSize方法 @Override public int getSize() { return size; } // 实现isEmpty方法 public boolean isEmpty() { return size == 0; } // 实现add方法 @Override public void add(K key, V value) { root = add(root, key, value); } // 向以node为根节点的二分搜索树中插入元素(key, value),递归算法 // 返回插入新元素后的二分搜索树的根 private Node add(Node node, K key, V value) { if (node == null) { size++; return new Node(key, value); } if (key.compareTo(node.key) < 0) { node.left = add(node.left, key, value); } else if (key.compareTo(node.key) > 0) { node.right = add(node.right, key, value); } else { node.value = value; } return node; } // 返回以node为根节点的二分搜索树中,key所在的节点 private Node getNode(Node node, K key) { if (node == null) return null; if (key.compareTo(node.key) < 0) { return getNode(node.left, key); } else if (key.compareTo(node.key) > 0) { return getNode(node.right, key); } else { return node; } } @Override public boolean contains(K key) { return getNode(root, key) != null; } @Override public V get(K key) { Node node = getNode(root, key); return node == null ? null : node.value; } @Override public void set(K key, V newValue) { Node node = getNode(root, key); if (node == null) throw new IllegalArgumentException(key + " doesn‘t exist!"); node.value = newValue; } // 返回以node为根的二分搜索树的最小元素所在节点 private Node minimum(Node node) { if (node.left == null) { return node; } return minimum(node.left); } // 删除掉以node为根的二分搜索树中的最小元素所在节点 // 返回删除节点后新的二分搜索树的根 private Node removeMin(Node node) { if (node.left == null) { Node rightNode = node.right; node.right = null; size--; return rightNode; } node.left = removeMin(node.left); return node; } // 实现remove方法 // 删除二分搜索树中键为key的节点 @Override public V remove(K key) { Node node = getNode(root, key); if (node != null) { root = remove(root, key); return node.value; } return null; } // 删除以node为根节点的二分搜索树中键为key的节点,递归算法 // 返回删除节点后新的二分搜索树的根 private Node remove(Node node, K key) { if (node == null) { return null; } if (key.compareTo(node.key) < 0) { node.left = remove(node.left, key); return node; } else if (key.compareTo(node.key) > 0) { node.right = remove(node.right, key); return node; } else { // 待删除节点左子树为空的情况 if (node.left == null) { Node rightNode = node.right; node.right = null; size--; return rightNode; // 待删除节点右子树为空的情况 } else if (node.right == null) { Node leftNode = node.left; node.left = null; size--; return leftNode; // 待删除节点左右子树均不为空 // 找到比待删除节点大的最小节点,即待删除节点右子树的最小节点 // 用这个节点顶替待删除节点 } else { Node successor = minimum(node.right); successor.right = removeMin(node.right); //这里进行了size--操作 successor.left = node.left; node.left = null; node.right = null; return successor; } } } }
- 用二分搜索树实现的映射与用链表实现的映射的性能比较
-
import java.util.ArrayList; public class Main { public static double testMap(Map<String, Integer> map, String filename) { long startTime = System.nanoTime(); System.out.println(filename); ArrayList<String> words = new ArrayList<>(); if (FileOperation.readFile(filename, words)) { System.out.println("Total words: " + words.size()); for (String word : words) { if (map.contains(word)) { map.set(word, map.get(word) + 1); } else { map.add(word, 1); } } System.out.println("Total different words: " + map.getSize()); System.out.println("Frequency of PRIDE: " + map.get("pride")); System.out.println("Frequency of PREJUDICE: " + map.get("prejudice")); } long endTime = System.nanoTime(); return (endTime - startTime) / 1000000000.0; } public static void main(String[] args) { String filename = "pride-and-prejudice.txt"; LinkedListMap<String, Integer> linkedListMap = new LinkedListMap<>(); double time1 = testMap(linkedListMap, filename); System.out.println("Linked List Map, time: " + time1 + " s"); System.out.println(); System.out.println(); BSTMap<String, Integer> bstMap = new BSTMap<>(); double time2 = testMap(bstMap, filename); System.out.println("BST Map, time: " + time2 + " s"); } }
- 输出结果
-
pride-and-prejudice.txt Total words: 125901 Total different words: 6530 Frequency of PRIDE: 53 Frequency of PREJUDICE: 11 Linked List Map, time: 9.692566895 s pride-and-prejudice.txt Total words: 125901 Total different words: 6530 Frequency of PRIDE: 53 Frequency of PREJUDICE: 11 BST Map, time: 0.085364242 s
- 通过比较结果,我们发现,用二分搜索树实现的映射的比用链表实现的映射更加高效
6.. 映射的时间复杂度
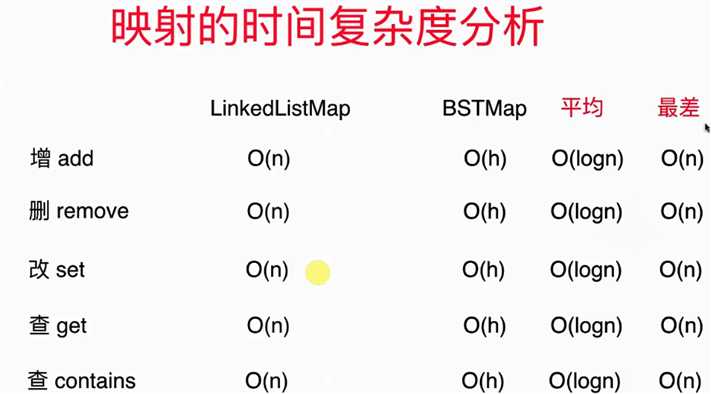
- 上图中"h"是二分搜索树的高度
- 当二分搜索树"满"的时候,性能是最佳的,时间复杂度为O(logn);当二分搜索树退化为链表的时候,性能是最差的,时间复杂度为O(n)
以上是关于第二十七篇 玩转数据结构——集合(Set)与映射(Map)的主要内容,如果未能解决你的问题,请参考以下文章