基于SVM的字母验证码识别
Posted xfydjy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于SVM的字母验证码识别相关的知识,希望对你有一定的参考价值。
 基于SVM的字母验证码识别
基于SVM的字母验证码识别
摘要
本文研究的问题是包含数字和字母的字符验证码的识别。我们采用的是传统的字符分割识别方法,首先将图像中的字符分割出来,然后再对单字符进行识别。首先通过图像的初步去噪、滤波、形态学操作等一系列预处理过程,我们能够将图像中的噪点去除掉。为了将字符分割开来,我们利用Kmeans聚类算法对图像中的像素点聚成五类,分别代表五个字符,结果表明Kmeans算法的聚类准确度能够达到99.2%。对字符分割完成之后,我们采用支持向量机的算法对字符进行识别,通过调节参数能够使得准确率达到93%左右。
一、问题描述
验证码目前在互联网上非常常见,从学校的教务系统到12306购票系统,充当着防火墙的功能。但是随着OCR技术的发展,验证码暴露出的安全问题越来越严峻。目前对验证码的识别算法研究已经比较成熟,有了许多优秀的验证码识别算法。尤其是近年来深度学习的兴起,一般的验证码已经没有了任何识别难度。抱着学习的态度,我们还是从最基础的传统算法来开始研究。
我们从某验证码识别比赛中获取到验证码数据集,该数据集包括10000个验证码样本,序号0000~9999,每个验证码图片,包含5个英文字母或数字字符。mappings.txt为该数据集的标签,每一行对应一个样例,其中:第一列为样例的序号;第二列为样例图片中的字符内容,英文字符统一转化为大写。验证码样本如图1所示:
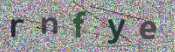
图1验证码样本
二、问题分析
传统的图像识别方法一般需要经过以下几个过程:图像预处理、图像分割、字符识别。由于图像中会存在干扰噪点或者干扰线,这对于字符的分割和识别会造成极大的困难。因此图像预处理的任务就是去除掉噪点,只保留有用的字符部分。由于一个样本中都包含了许多字符,要做到直接进行端对端的识别非常困难。而通过字符分割我们就能够够得到字符识别样本库,有了这样的样本之就可以构建将其作为训练集训练分类器从而将字符分割。综合考虑自身能力以及所学的知识,我们决定使用svm算法来作为字符识别的分类器。Svm的好处在于已经有现成的框架可以使用,并且处理大量数据时svm的效果比较好。
三、图像预处理
对于图像的预处理,一般流程为:灰度化—二值化—初步去噪—滤波—形态学处理(二次去噪)—二值化(二次)—字符分割—字符归一化。
3.1灰度化
灰度化即将彩色图像图像转化为灰度图像,这样就能将三通道的彩色图像转化为单通道的图像。图像灰度化处理之后能够使得后续的处理更加方便,灰度化的一般公式为:
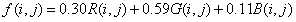
灰度化中我们使用的图像工具箱为PIL库中的Image模块,灰度化的python实现代码为:
imgry=img.convert(‘L‘)
灰度化后的图像:

图2 灰度化后的图像
3.2 图像二值化
图像二值化是指将灰度图像转化为只包含0-1的黑白,0代表黑色,1代表白色。首先我们需要确定好阈值,将大于阈值的转化为白色,小于阈值的转化为黑色。利用photoshop图像处理工具可以看到阈值变化对于图像二值化效果影响,通过试验我们最终确定128是比较合适的。二值化同样使用Image模块,实现代码如下:
def get_table(threshold=128),def Get_BiImg(img)利用这两个函数即可。
最后得到的二值化的图像图3所示,我们可以看这是图像只有黑白两种颜色,并且主要字符非常突出。

图3 二值化后的图像
3.3初步去噪
从图像中可以看出二值化后的图像干扰噪点大部分成散点分布,而字符的轮廓经二值化处理之后较为明显。因此我们可以采用计算每个像素点周围的黑点个数的方法来作为判断是否为噪点的标准。根据图像的特点,我们有以下经验:如果某个点的位置周围点少于3个则可以认为是噪点。程序实现代码为:
def Get_ClearImg(img)
经过初步去除噪点之后的图像如下:
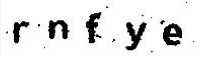

图4 初步去噪后的图像
从图中4可以看出经过初步去除之后已经去除了大部分的噪点,但是还有仍然存在很多噪点。因此需要进一步处理。
3.4 图像的形态学操作
图像的形态学操作简单来说就是基于形状的一系列图像处理操作,通过将结构元素作用于输入图像来产生输出图像,详细介绍可以在网上查到。图像形态学上的处理主要有:腐蚀(erosion)、膨胀(dilation)、开操作(oening)、闭操作(closing).对于进行过初步处理之后的图像,我们首先去除还有没有删除的孤立的小噪点族。幸运的是skimage库已经给我们准备好了一个函数:
remove_small_objects(img,min_size=15,connectivity=1)
这个函数可以直接帮助我们删除面积小于min_size的图像。我们首先计算图像中的连通区域,通过设定阈值来决定多小的连通区域可以删除掉。通过多次试验,我们发现面积为15时效果较好,既不会误删也不会漏删。最终我们得到的结果如下:
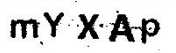

图5 形态学操作后的图像
可以看出图像中的大部分噪点已经被去除,但是仍然有些噪点。
在此基础上继续进行形态学出处理,首先进行腐蚀能够去除掉比较窄的线条。如果在进行胀,我们就能恢复到跟原来图像差不多的状态。实际上开操作就是先腐蚀后胀两步操作的整合。经过测试发现边长为3的正方形作为算子,效果最佳。最终的结果如下:


图6二次形态学操作后的图像
主要操作代码:
dst=morphology.remove_small_objects(biImg,min_size=15,connectivity=1)#去除小区域面积
dst=dst*1.0#转化为非逻辑型图像
dst1=sm.opening(dst,sm.square(3)) #开运算
四、字符分割
经过一系列的操作,我们最终去除了大部分的干扰点。但是在操作过程中也有部分字符出现了裂缝。对于字符的分割,主要的方法有连通区域法、积分投影法,还有聚类消除法。由于字符存在不连续性,前两种方法暂时没有想出合适的操作。因为字符断裂开后相差不是很远,并且每张图像上的字符都为5个,所以如果采用Kmeans对数据点进行聚类的话,这些断裂或不联通的字符会聚成一类,这样就实现了字符的分割。这里我们直接用了sklearn库中的Kmeans函数。
最终的字符聚类如图7所示:


图7 部分字符聚类结果
经过50张图的测试,除两张图分割错误之外,其余都完全正确。
分类错误的图:

图8 字符定位错误的图像
在出现问题之后,我们认为可能是最初的中心点位置没有选好,但是经过更改质心初始化的方法也不能成功解决。这里还有待改进,但总体来说还是不错,定位准确率能够达到99.2%,所以暂时这样继续下去。
五 字符分割
通过聚类我们已经能够找出字符的位置,只需要找到最小包含字符的矩形就行,也就是找到这个矩形的对角线坐标即可。但是这里存在一个问题就是聚类之后的字符顺序并不是按照图片上的顺序来的,而是随机的,因此还需要对字符子图重新排序,我们以左上角的x坐标作为排序的标准。
排序之后对图像分割之后如下:


图9 字符分割的结果
可以看出字符已经被很好的分割开来了,但是由于大小不同对于后面的识别有很大困难。因此还需要将字符尺寸进行归一化,我们选定大小为30*20.结果如下:


图10 归一化后的字符
经过标准化之后的字符大小都一样,极大地方便了后续的识别步骤。
六、字符识别
经过预处理之后,将所有图像都进行了分割,得到一系列的大小一暗影的字符图片。经过200张图片的测试,经过预处理之后总的时间为78秒。大概一个小时就能够将所有图像处理完成。
6.1特征提取
我们选取的特征是投影特征,计算在水平方向和垂直方向的黑点个数,然后组成新的特征向量,结果为50维的特征向量。然后经过对文件名的操作,直接读取标签。这样我们就得到所有字符的特征向量和标签。
6.2 单样本字符识别
我们采用支持向量机作为分类器,svm的详细介绍可以参考之前关于支持向量机的算法报告。利用sklearn可以很方便的调动svm算法,并且能够实现多分类。我们选取200张图片作为训练集,得到1000个字符的字符训练集;以1000张验证码作为测试集,得到5000张字符的训练集。下面是在这些数据集上的测试结果,其中参数C表示的是最大间隔,gamma表示的是核函数的σ值。
表1 Svm字符识别算法运行结果
|
方法 |
C |
gamma |
错误率 |
|
svm |
10 |
0.00001 |
90.24% |
|
0.00002 |
91.92% |
||
|
0.00005 |
92.92% |
||
|
0.0007 |
91.14% |
||
|
0.0009 |
90.52% |
||
|
0.0001 |
93.28% |
||
|
0.0003 |
92.56% |
||
|
0.0007 |
91.14% |
||
|
0.002 |
85.78% |
||
|
0.004 |
74.56% |
||
|
0.01
|
51.10% |
||
|
0.04
|
11.20% |
||
|
0.2 |
3.84% |
6.3 结果分析
从上面的结果我们可以看出svm算法的准确率随参数的变化情况,当gamma为0.0003时准确率为92.56%最高。而随着gamma的增大,准确率会逐渐下降。对于单字符的验证码识别,这样的效果还是很不错的,毕竟字符类型有30多种。但是这样的结果如果用在整个验证码图像上则会使得准确率急剧下降。
七、总结
从最终结果出发,虽然我们对单字符的识别能够达到93%左右,但是这样的结果在实际操作效果是不够好的。通过分析我们不难发现,主要问题在于数据预处理过程的字符分割和特征的选取。虽然字符分割效率很高,但是一旦出现错误那么预测的结果就会完全错误。而由于样本种类较多,但是所选的特征数目较少或者不合适,这样也在很大程度上影响了算法的效果。因此在后面我们继续针对这两个地方进行研究,以期取得更好的结果。
八、代码
###————本模块主要用于预处理图像并把切割的图保存在trainImg中————#####
#verificationCode.py
import itertools from PIL import Image from PIL import ImageFilter from PIL import ImageEnhance import scipy.ndimage as ndi from skimage import morphology as sm#形态学操作 import matplotlib.pyplot as plt from skimage import io,color,transform,filters,segmentation,measure,morphology from sklearn.cluster import KMeans import numpy as np import time #——————————模式1:0-1二值化————————# #图像二值化 def get_table(threshold=128): table = [] for i in range(256): if i < threshold: table.append(0) else: table.append(1) return table def Get_BiImg(img): imgry=img.convert(‘L‘) table=get_table() biImg=imgry.point(table, ‘1‘) return biImg #初步去除噪声 def Get_ClearImg(img): ##### 去除散点 for j in range(img.height): for i in range(img.width): #消除周围黑点小于3的噪点(散点) x=[i-1,i,i+1] y=[j-1,j,j+1] DCTS=itertools.product(x,y)#笛卡尔积 count=0 for p in DCTS: try:#边界点的想x,y会出现问题,代价是边界点默认为噪点 if img.getpixel(p)==0: count+=1 except: continue if count<=4:#包括自己四个点 img.putpixel((i,j),1) clearImg=img return clearImg def get_label(filename=‘testLabels.txt‘):#获取测试集标签 #filename=filename#文件名 fr=open(filename) labels=[] for line in fr.readlines(): line=line.strip() line=line.split(‘,‘) labels.append(line) return labels def getIlabel(Labels,i): cropLabel=[Labels[i][1][j] for j in range(len(Labels[i][1]))] return cropLabel def get_feat_label(imgName):#输入如:‘0005_3_k.jpg‘ img=Image.open(imgName)#读取图片 img=Get_BiImg(img)#转化为2值图片 rowArr=[]#存储特征向量 height=img.height#高度 width=img.width#宽度 for j in range(height):#获取图片的特征 count=0#计算黑点个数 for i in range(width): if img.getpixel((i,j))==0: count+=1#如果为黑点则计数加1 rowArr.append(count) str1=imgName.split(‘.‘)#分割路径 label=str1[0][-1]#获取标签 return rowArr,label imgCount=2000 t1=time.time()#开始计时 for i in range(imgCount): img=Image.open(‘testData\\{0:0>4.5s}.jpg‘.format(str(i+3000)))#读入原数据 #imgry=img.convert(‘L‘)#图像灰度化 #imgry.show() biImg=Get_BiImg(img)#图像二值化 clearImg=Get_ClearImg(biImg)#初步去除噪点 clearImg.save(r‘D:python CodeverificationCodeImg1\\testClearImg{0:0>4.5s}.jpg‘.format(str(i+3000))) —对字符进行形态学去噪————# #注意:此处开始使用的是skimage库而不是pIL,因为pIL库不提供形态学操作的工具。 #应当特别注意数据的类型变化 for i in range(imgCount): img=io.imread(‘Img1\\testClearImg\\{0:0>4.5s}.jpg‘.format(str(i+3000))) img_gray=color.rgb2gray(img) biImg=(img_gray<=128)#*1.0#转换成二值图像,*1是为了将逻辑型转化为float型 dst=morphology.remove_small_objects(biImg,min_size=15,connectivity=1)#去除小区域面积 dst=dst*1.0#转化为非逻辑型图像 #io.imshow(dst) #dst1=sm.erosion(biImg,sm.square(3)) #用边长为3的正方形滤波器进行腐蚀滤波 #dst2=sm.dilation(dst1,sm.square(5)) #用边长为5的正方形滤波器进行膨胀滤波 dst1=sm.opening(dst,sm.square(3)) #开运算 #dst3=sm.closing(dst3,sm.square(2)) #闭运算 dst2=morphology.remove_small_objects(dst1==1,min_size=15,connectivity=1)#去除小区域面积 dst3=dst2*1.0 #dst4=sm.dilation(dst3,sm.rectangle(1,3)) #用边长为5的正方形滤波器进行膨胀滤波 io.imsave(r‘D:python CodeverificationCodeImg1 estMorphologyImg{0:0>4.5s}.jpg‘.format(str(i+3000)),dst3) #io.imshow(dst3) #plt.show() labels=get_label(‘testLabels.txt‘)#获取标签 #————基于Kmeans的字符分割————# for i in range(imgCount): labelI=getIlabel(labels,i)#获取第i张图的标签 img = io.imread(‘Img1\\testMorphologyImg\\{0:0>4.5s}.jpg‘.format(str(i+3000))) img=color.rgb2gray(img)#灰度化 biImg=(img>=128)*1.0#转换成二值图像 row, col=img.shape idy,idx=np.where(biImg==1) wordIdx=[[idy[i],idx[i]] for i in range(len(idx))] #initArray=np.array([[np.percentile(idx,100*(i+2)/7),np.percentile(idy,100*(i+2)/7)] for i in range(5)]) label = KMeans(n_clusters = 5,max_iter=300).fit_predict(wordIdx)#获取各点的标签 ‘‘‘ #————显示结果————# for i in range(len(label)): x=idx[i];y=idy[i] biImg[y][x]=(label[i]+1)*50 io.imshow(biImg) plt.show() ‘‘‘ cropImg=[]#存储字符子图的位置 XX=[]#记录子图的位置 for j in range(5): cropIdx=np.where(label==j) minX=min(idx[cropIdx])#左上角X坐标 XX.append(minX) minY=min(idy[cropIdx])#左上角Y坐标 maxX=max(idx[cropIdx])#右下角X坐标 maxY=max(idy[cropIdx])#右下角Y坐标 Img=biImg[minY:maxY+1,minX:maxX+1] cropImg.append(transform.resize(Img,(30,20)))#尺寸归一化 #cropImg.append(biImg[minY:maxY+1,minX:maxX+1])#未经尺寸归一化地分割子图 order=np.argsort(XX)#获取顺序 sortCropImg=[cropImg[order[i]] for i in range(5)]#对图进行排序 ‘‘‘ #————未经归一化的图像显示——————# fig, axes = plt.subplots(1, 5, figsize=(6,2))#准备绘制多个子图 for i in range(5): axes[i].imshow(sortCropImg[i]) fig.tight_layout() plt.show() ‘‘‘ for k in range(5): io.imsave(r‘D:python CodeverificationCodeImg1 estImg{0:0>4.5s}_{1:0>1.5s}_{2:s}.jpg‘.format(str(i+3000),str(k),labelI[k]),sortCropImg[k]) #feat,label=get_feat_label(‘{0:0>4.5s}_{1:0>1.5s}_{2:s}.jpg‘.format(str(i),str(k),labelI[k])) t2=time.time() print(‘所用时间为:%fs‘%(t2-t1))
#svm.y
from numpy import* from sklearn.svm import SVC from sklearn.decomposition import PCA from sklearn.neighbors import KNeighborsClassifier from sklearn.ensemble import AdaBoostClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.linear_model import LogisticRegression from sklearn.cluster import KMeans from skimage import io,color,transform,filters,segmentation,measure,morphology from sklearn import metrics import os from PIL import Image import time def get_table(threshold=128): table = [] for i in range(256): if i < threshold: table.append(0) else: table.append(1) return table def Get_BiImg(img): imgry=img.convert(‘L‘) table=get_table() biImg=imgry.point(table, ‘1‘) return biImg def getFeat(img):#主要用于端对端的验证码识别 featArr=[]#存储特征向量 height=shape(img)[0]#高度 width=shape(img)[1]#宽度 for j in range(height):#获取纵向的特征 count=0#计算黑点个数 for i in range(width): if img[j][i]==0: count+=1#如果为黑点则计数加1 featArr.append(count) for i in range(width):#获取横向的特征 count=0 for j in range(height): if img[j][i]==0: count+=1#如果为黑点则计数加1 featArr.append(count) return array([featArr]) def get_feat_label(imgName):#输入如:‘0005_3_k.jpg‘ img=Image.open(imgName)#读取图片 img=Get_BiImg(img)#转化为2值图片 featArr=[]#存储特征向量 height=img.height#高度 width=img.width#宽度 for j in range(height):#获取纵向的特征 count=0#计算黑点个数 for i in range(width): if img.getpixel((i,j))==0: count+=1#如果为黑点则计数加1 featArr.append(count) for i in range(width):#获取横向的特征 count=0#####重新开始计算count的值 for j in range(height): if img.getpixel((i,j))==0: count+=1#如果为黑点则计数加1 featArr.append(count) str1=imgName.split(‘.‘)#分割路径 label=str1[0][-1]#获取标签 return featArr,label def getFeatsLabels(filePath): featArr=[];labels=[]#存储特征信息和标签 childDir=os.listdir(filePath)#用于存储所有图片的文件名 for allDir in childDir: img_whole_name=os.path.join(‘%s\\%s‘%(filePath,allDir))#图片包含路径的完整名称 rowArr,label=get_feat_label(img_whole_name) featArr.append(rowArr)#featArr添加一个数据 labels.append(label)#labels添加一个数据 return array(featArr),labels def get_label(filename=‘testLabels.txt‘):#获取测试集标签,与verication中稍有不同 #filename=filename#文件名 fr=open(filename) labels=[] for line in fr.readlines(): line=line.strip() line=line.split(‘,‘) labels.append(line[1]) return labels def convertLabel(labels): newLabel=[] for label in labels: newLabel.append(char2intLabel.index(label)) return array(newLabel) #——————读取数据——————# print(‘读取数据‘) char2intLabel=[‘0‘,‘1‘,‘2‘,‘3‘,‘4‘,‘5‘,‘6‘,‘7‘,‘8‘,‘9‘,‘A‘,‘B‘,‘C‘,‘D‘,‘E‘,‘F‘,‘G‘, ‘H‘,‘I‘,‘J‘,‘K‘,‘L‘,‘M‘,‘N‘,‘O‘,‘P‘,‘Q‘,‘R‘,‘S‘,‘T‘,‘U‘,‘V‘,‘W‘,‘X‘,‘Y‘,‘Z‘] trainFeatArr,trainLabels=getFeatsLabels(‘D:python Code\\verificationCodeImg1\\trainImg‘) testFeatArr,testLabels=getFeatsLabels(‘D:python Code\\verificationCodeImg1\\testImg‘) trainLabels=convertLabel(trainLabels)#将数据标签转化为数值型 testLabels=convertLabel(testLabels) #——————支持向量机算法————# t1=time.time() print(‘开始计时‘) #单字符识别 for ga in [0.00002,0.0007,0.001,0.01,0.1]: for c in [10]:#[0.01,0.07,0.3,0.7,1,2,4,6,10,15,20,30]: clf =SVC(C=c, kernel=‘rbf‘, gamma=ga, decision_function_shape=‘ovo‘)#初始化模型 clf.fit(testFeatArr,testLabels)#训练模型 y_hat = clf.predict(trainFeatArr)#预测结果 #print(‘decision_function: ‘, clf.decision_function(trainFeatArr)) #print(‘ predict: ‘, clf.predict(trainFeatArr)) accuracy = metrics.accuracy_score(trainLabels,y_hat) print(‘accuracy: %.2f%%‘ % (100 * accuracy)) t2=time.time() print(‘时间:%2fs‘%(t2-t1))
以上是关于基于SVM的字母验证码识别的主要内容,如果未能解决你的问题,请参考以下文章
验证码识别与生成类API调用的代码示例合集:六位图片验证码生成四位图片验证码生成简单验证码识别等
爬虫遇到头疼的验证码?Python实战讲解弹窗处理和验证码识别