[学习记录]NLTK常见操作一(去网页标记,统计词频,去停用词)
Posted trickofjoker
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[学习记录]NLTK常见操作一(去网页标记,统计词频,去停用词)相关的知识,希望对你有一定的参考价值。
NLTK是python环境中的一个非常流行的NLP库,这篇记录主要记录NLTK的一些常见操作
1.去除网页html标记
我们常常通过爬虫获取网页信息,然后需要去除网页的html标签。为此我们可以这么做:
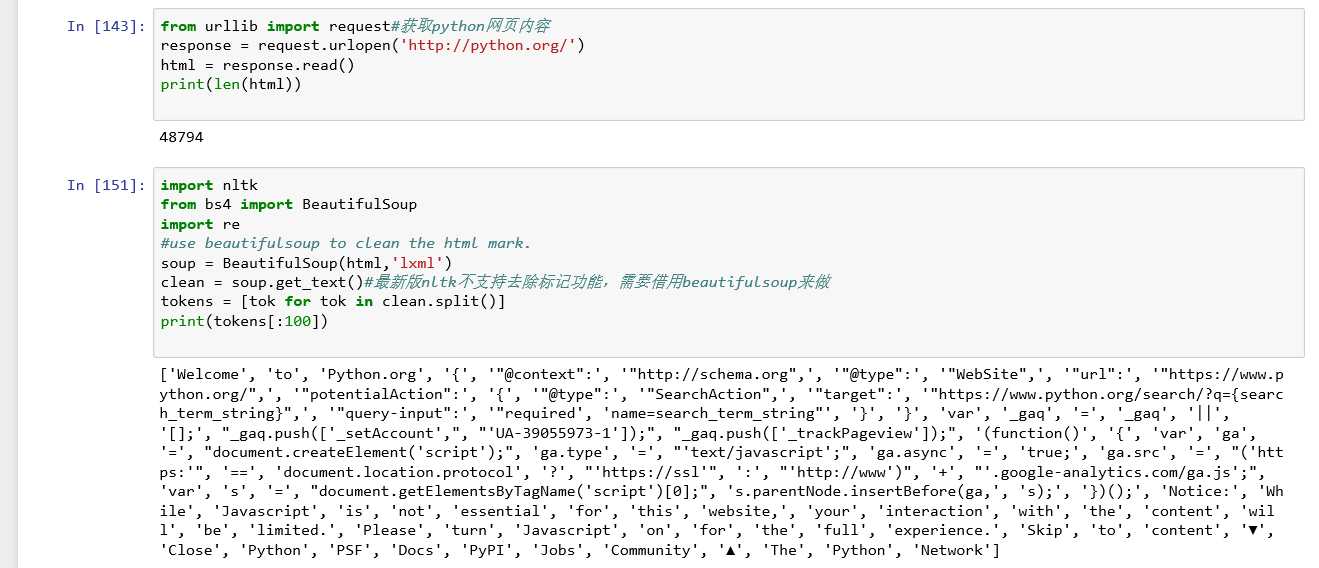
2.统计词频
这里使用的tokens就是上面图中的tokens
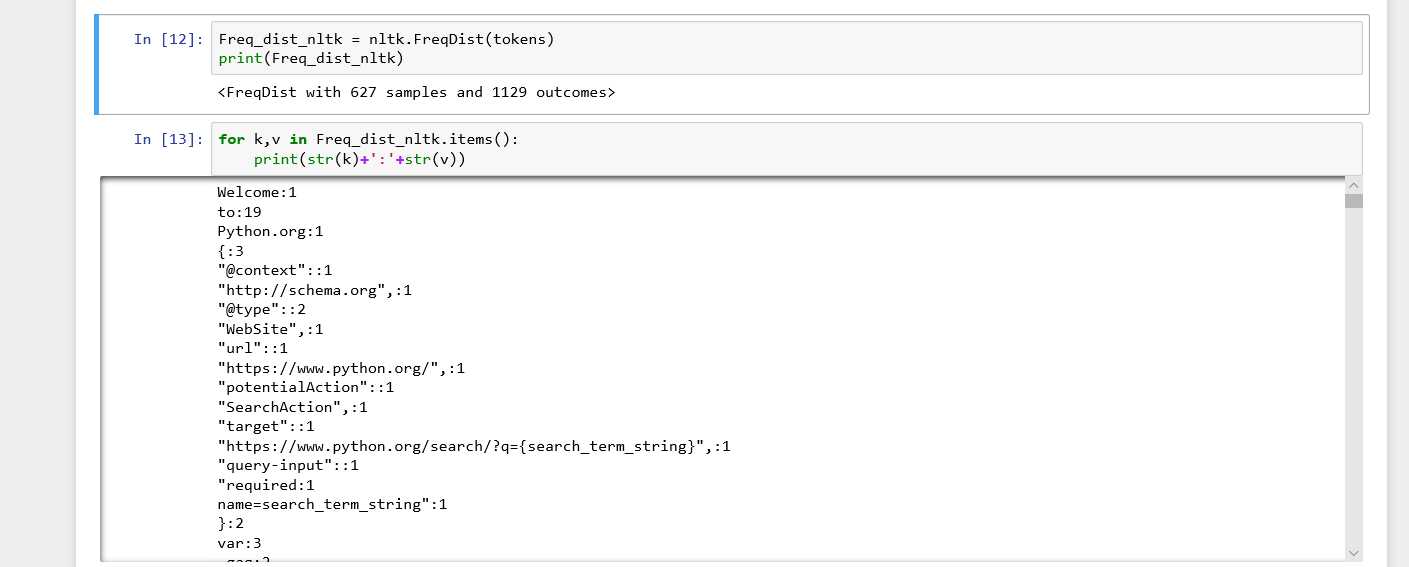
3.去除停用词
停用词就是类似the,a,of这种语义无价值的词,取出后我们还可以把统计图画出来
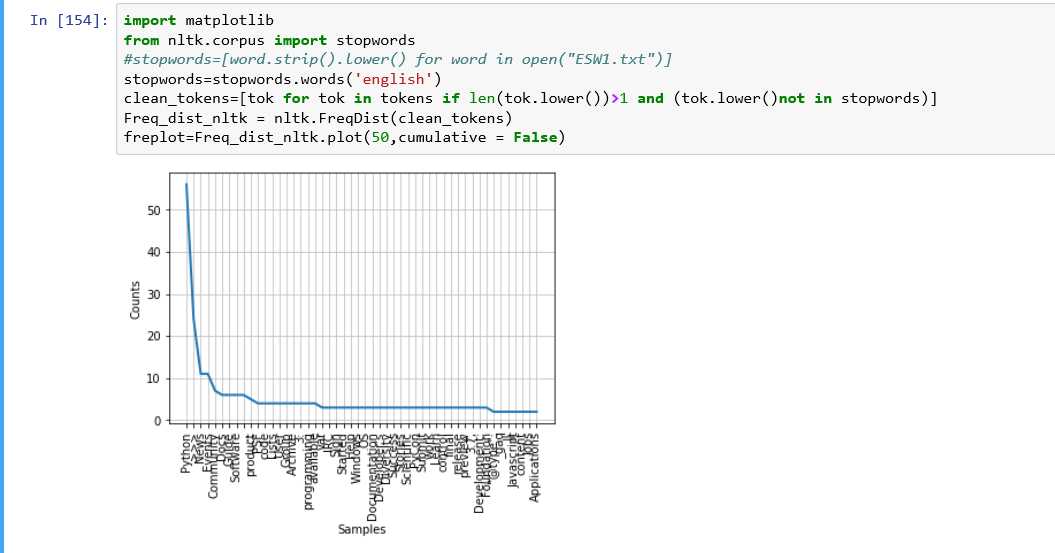
4.绘制词云图
对于词云图的使用原理还不太清楚,只是找了一个可运行的公式
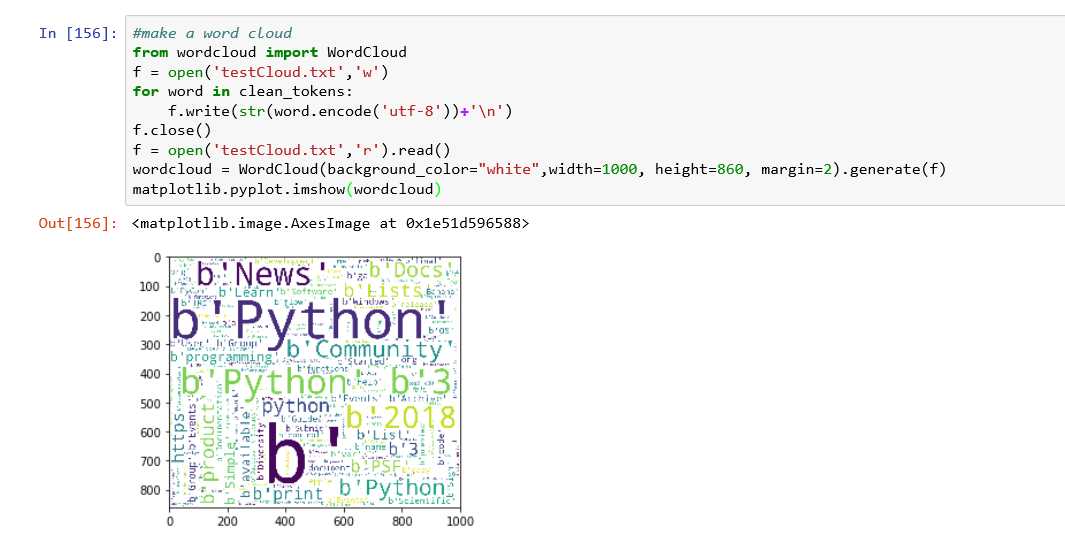
以上是关于[学习记录]NLTK常见操作一(去网页标记,统计词频,去停用词)的主要内容,如果未能解决你的问题,请参考以下文章