kettle集成开发及源代码分析
Posted dongzhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kettle集成开发及源代码分析相关的知识,希望对你有一定的参考价值。
前段时间因项目需要将kettle集成到我们自己的平台,以下是就整个开发中遇到的问题和开发的过程做一个总计。
本篇文章将从以下几个方面介绍:ETL和ELT,kettle的组成,kettle的原理,源码分析
1.ETL和ELT
ETL和ELT都是数据整合的一种方式。 不同是ELT是先load数据,ETL是先转换数据。
下面是数据处理中ETL和ELT一个简要的流程图
两者都有自己不同的使用场景:
ETL的数据转换在ETL工具中
ELT的数据转换在数据库中。
ELT是针对DB结构一致,ETL没有这一个要求。
2.kettle
kettle是国一款开源ETL工具,纯java开发。数据抽取具有高效稳定,支持范围广的特点。
Kettle在2006年初加入了开源的BI公司Pentaho, 正式命名为:Pentaho Data Integeration,简称“PDI”。目前,kettle的版本已经到10了。
kettle是由4部分组成:
Spoon:图像化界面 ,定义作业,执行作业(网页版,客户端)
Pan:Transformation执行器(命令行方式),Pan用于在终端执行Transformation,没有图形界面
Kitchen:Job执行器(命令行方式),Kitchen用于在终端执行Job,没有图形界面。
Carte:嵌入式Web服务,用于远程执行Job或Transformation,Kettle通过Carte建立集群。
3.kettle的原理
通过在spoon的界面创建作业后,会在r_job添加一条记录,同时产生163项关于这个job的属性。
然后读取kettle目录下的repositories.xml,读取资源库的配置。spoon分为资源库和生产库。
作业的运行结果会在生产库的日志表里生成。etl_job_log,etl_job_item_log,etl_channel_log三个表生成日志。
4.kettle的源码分析
主要针对spoon的源码分析:
spoon的界面是用XUL(XML User Language:xml 用户语言)编写的。分为控制层,对话层,XUL.
spoon的入口代码:Spoon的main()方法
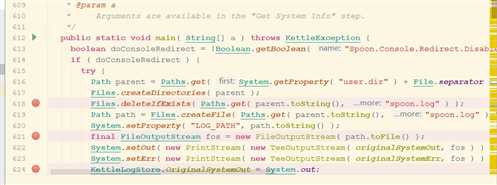
//初始化 --kettle环境的初始化
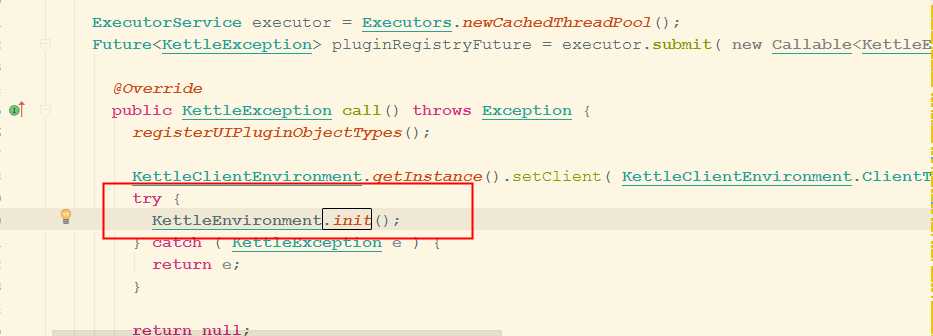
//初始化 --spoon的界面初始化、日志初始化
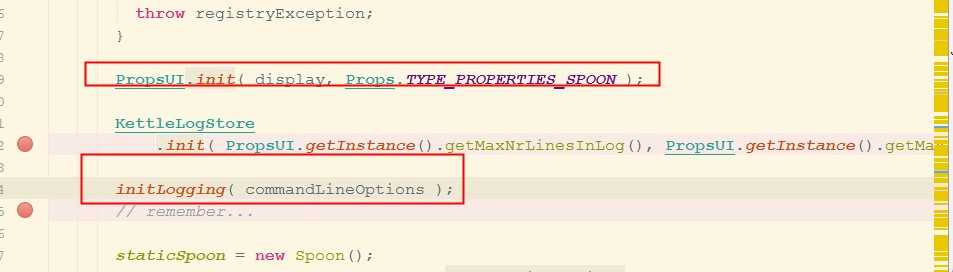
下面对登陆资源库的过程就行分析:
包的结构:
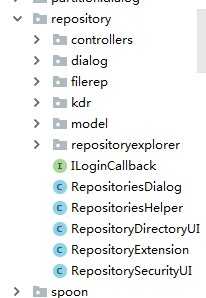
大致分为:控制层、对话层、模型层,其他工具类
先从界面分析: repositories.xul
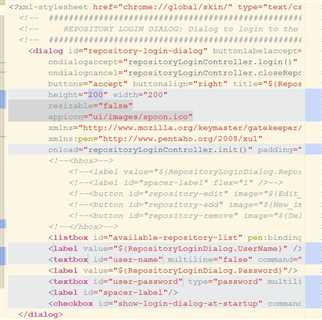
可以看得出来, 界面跟控制层是绑定的。界面的onload方法调用控制层init方法。
为了实现自动登录,我修改了控制的代码,去掉了不需要的项,去掉了异步的方法
1、在构造函数中设置了用户名和密码,不需要前端页面传递值过来
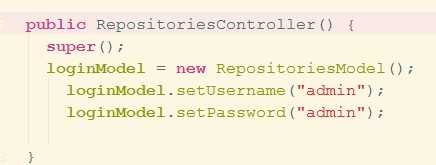
// 在init方法通过document绑定页面的值
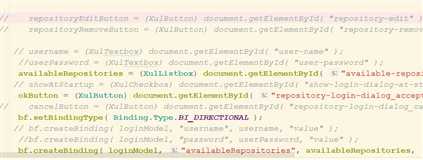
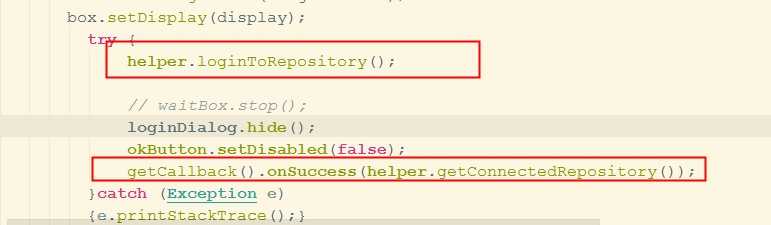
//登录的实现
界面转换成等待的窗口
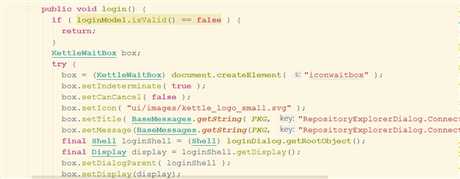
登录注册库、成功之后调用回调函数
以上是关于kettle集成开发及源代码分析的主要内容,如果未能解决你的问题,请参考以下文章