浏览器对HTTP请求的编码行为
Posted xurongjian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浏览器对HTTP请求的编码行为相关的知识,希望对你有一定的参考价值。
浏览器对请求的URL编码行为
浏览器会对请求的URL中非ASCII码字符进行编码。这里并非是整个URL进行编码,而是对非ASCII码字符进行编码,详情请看下面的实验记录。
- 实验一:在URL参数Name中输入中文“哈哈”,在Fiddler中抓取的请求中“哈哈”被编码成了“%e5%93%88%e5%93%88” 。
http://localhost:27713/MyIndex.aspx?Name=哈哈
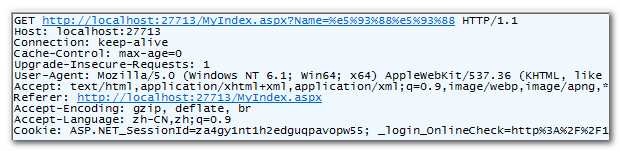
- 实验二:将URL中的“MyIndex”替换成中文“哈哈”,参数Name中输替换成刚才被编码过的中文“哈哈”。从Fiddler抓到的请求中可以看到中文“哈哈”被编码了,但“%e5%93%88%e5%93%88”仍保持不变。如果它被编码了(即中文“哈哈”被编码两次),它应该长这样“%25e5%2593%2588%25e5%2593%2588” 。由此可以得出,浏览器仅对URL中的非ASCII码字符进行编码而已。
http://localhost:27713/哈哈.aspx?Name=%e5%93%88%e5%93%88

HTTP服务器在接收到这样的请求时,会对URL中转义的字符进行解码,请看下面实验三。
- 实验三:抓的请求Name=%e5%93%88%e5%93%88,但在程序里获取参数Name时是已被解码还原成中文“哈哈”。

但是,HTTP协议中并没有指定使用何种编码和字符集来解释URL中的非ASCII字符,因此,是否能成功解析就完全取决于URL中非ASCII内容的编码是否与 HTTP服务器的解析编码一致。
浏览器对POST请求相关的编码行为
对于POST请求,表单中的参数值是通过request body发送给服务器,此时浏览器会根据页面 Content-Type 指定的字符集对表单数据进行编码,然后再将表单数据发送给服务器。服务器收到请求后会对表单数据进行解码。因为编码、解码是由浏览器和服务器完成的,所以开发人员一般是感觉不到这个过程的。但你可以通过下面的实验截图,直观的感受这个编解码过程。
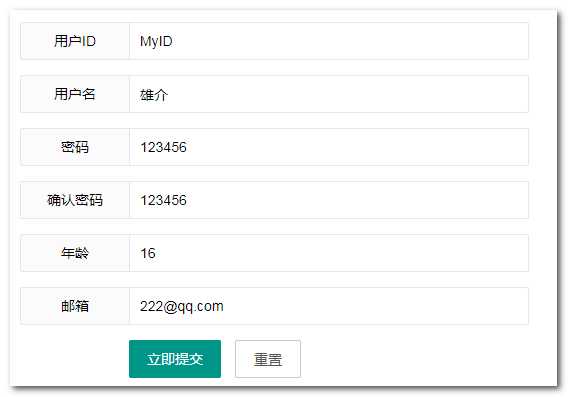
- 步骤一:填写表单,提交请求。
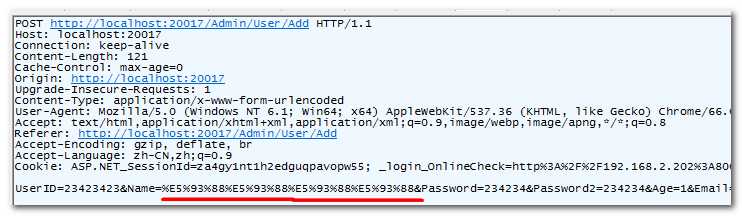
- 步骤二:抓取请求,确认用户名被编码。
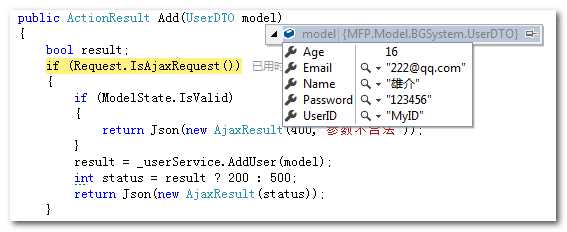
- 步骤三:在程序后台获取被服务器解码后的用户名。
参考引用:
https://blog.csdn.net/happy_wuyuqing/article/details/8144830
https://www.cnblogs.com/haitao-fan/p/3399018.html
以上是关于浏览器对HTTP请求的编码行为的主要内容,如果未能解决你的问题,请参考以下文章
HTTP 冷知识 | HTTP 请求中,空格应该被编码为 %20 还是 + ?