决策树——Decision Tree
Posted terieqin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树——Decision Tree相关的知识,希望对你有一定的参考价值。
前言
生活中有很多利用决策树的例子。西瓜书上给的例子是西瓜问题(讲到这突然想到书中不少西瓜的例子,难道这就是它西瓜封面的由来?)。大致意思是,已经有一堆已知好瓜坏瓜的西瓜,每次挑取西瓜的一条属性,将西瓜进行分类。然后在分类的西瓜中,继续挑取下一条属性进行更加细致的划分,直到所有的属性被用完。
这个例子有一个隐含的前提,就是给出所有的属性,它唯一地决定西瓜的好坏。意思是,不存在两个都是好瓜的瓜,或者都是坏瓜的瓜,它们的所有属性都相同。这有点类似数据库中的实体完整性。这样,你才能通过构建的决策树,按照它的用来分类的属性的顺序,每次前进一个分支,直到最后一层就能知道待测西瓜是否是好瓜。
但是如果由许多瓜,有好瓜也有坏瓜,他们的属性都相同的时候,就意味着你沿决策树到达叶子节点的时候,面临多种选择。这时候,可以选择出现次数最多的瓜种作为结果返回。
(这是用手机从西瓜书上拍下来的。结果上传的时候才发现忘记设置照片大小了,2M)
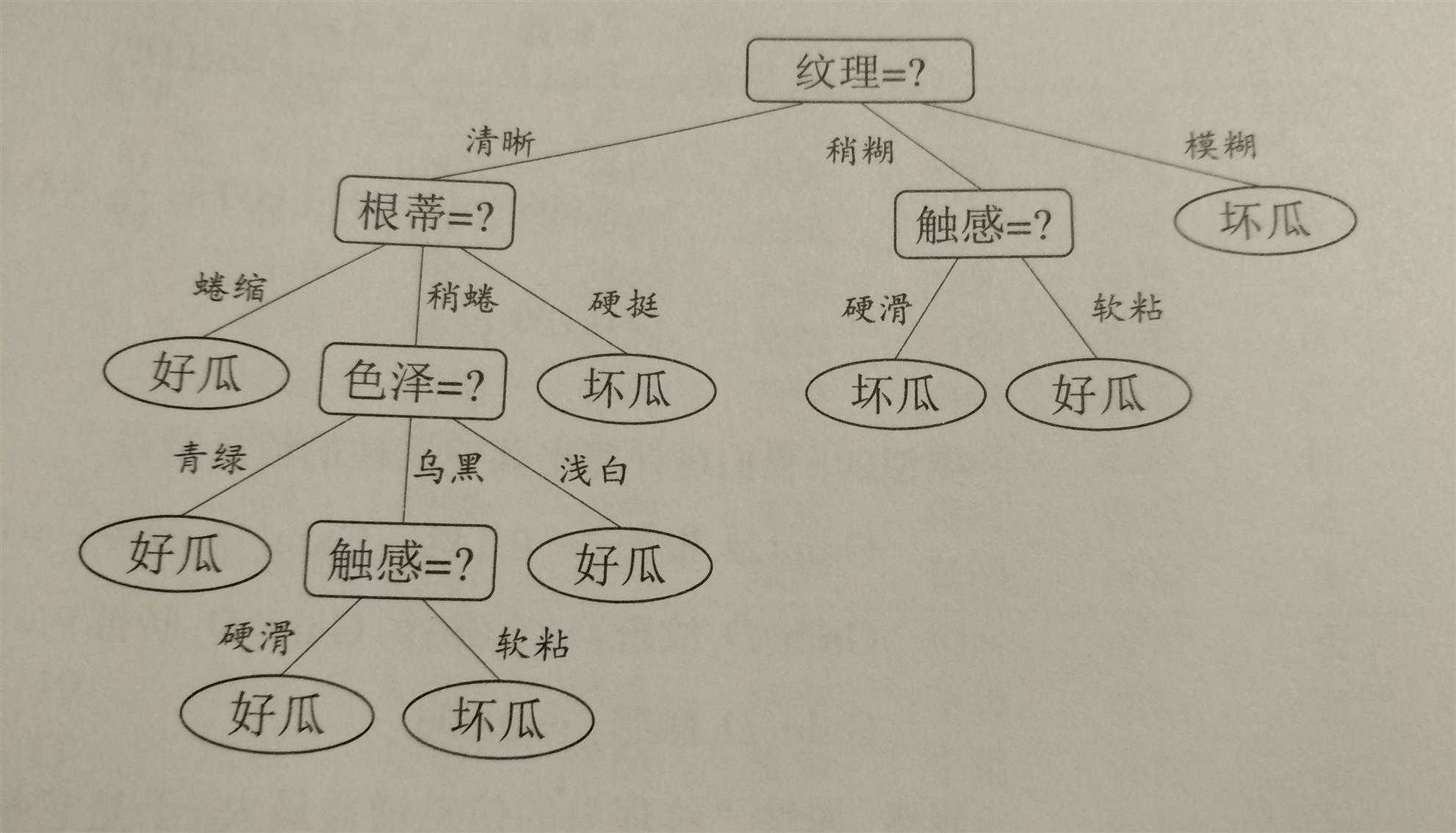
决策树的最关键的问题是,如何选择划分属性的顺序才能使得决策树的平均性能最好(即平均在树上走最少的路径就可以知道结果)。比如说,如果触感就能够唯一决定一个瓜是否是好坏,但是触感确实放在最后进行划分的,那么前面走的所有步骤都是多余的。如果一开始就用触感来进行划分,那么只需要走一步,就能够知道西瓜是否是好瓜。
下面来解释一个概念,它能够决定用何种属性进行划分。
熵
划分数据集最大的原则就是:将无序的数据变得更加有序。我们选取的是,能够将数据划分得“最有序”的属性。换句话说,选取能够给出最多信息的属性进行划分。打个比方,我要判断一个蚊子是否是母蚊子,你首先告诉我它有翅膀。可是所有的蚊子都有翅膀,这对我进行分类毫无意义,就称“有无翅膀”这一属性完全没有给出任何信息。如果你告诉我它经常在你身边上下腾飞骚扰你,那么我能够给出八成的可能说它是母蚊子,就说它给出了部分信息。你如果告诉我它会吸血,那母蚊子没跑了。“会不会吸血”这一属性给出了决定性的信息。
熵(Entropy)定义为信息的期望值,它在物理学上表示物质的混乱程度。在信息学上可以作类比。熵增加,表示信息更加混乱,熵减,表示信息更加有序。假设划分之前,这堆西瓜的熵是$Ent(D)$,按照某种属性划分之后这堆西瓜的熵是$Ent(D‘)$,注意后者一定小于等于前者。否则划分就没有任何意义。这两者的差,就是这个属性对于这堆西瓜有序化的贡献。下面说明熵的计算方法:
假设样本集$D$中,第$k$类样本所占的比例为$p_k$,那么$D$的熵:
$Ent(D) = - Sigma p_klog_2p_k$
这里约定$p_k = 0$时,$p_klog_2p_k = 0$。当这样本集被某个属性划分成$v$份之后,熵就是所有子集的熵的和:
$Ent(D‘) = -Sigma Ent(D^i) ,i = [1,...,v]$
但是,每个样本子集中划分到的样本数量不一样,需要对每个子集的熵进行加权:
$Ent(D‘) = -Sigma frac{|D^i|}{|D|}Ent(D^i) ,i = [1,...,v]$
于是熵增就定义为
$Gain(D,a) = Ent(D) - Ent(D‘) = Ent(D) - Sigma frac{|D^i|}{|D|}Ent(D^i) ,i = [1,...,v]$
表示,按照属性a对D进行划分熵的增益。显然,增益越大,表示越应该提前使用该属性进行划分。
下面给出计算熵增的python2.x 代码
def calcShannonEnt(dataSet): numEntries = len(dataSet) labelCounts = {} for featVec in dataSet: currentLabel = featVec[-1] if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0 labelCounts[currentLabel] += 1 shannonEnt = 0.0 for key in labelCounts: prob = float(labelCounts[key])/numEntries shannonEnt -= prob*log(prob,2) return shannonEnt
这里的dataSet,由多个向量组成,每个向量代表一个样本。这里的向量的最后一个元素代表该样本的类别。这不同于之前的KNN算法。KNN的类别和属性是分开表示的。
第一个for循环计算每个类别的概率。第二个for循环计算熵。
决策树完整算法
输入:样本集D,每个样本包含他们的属性(值)和类别。
输出:决策树
算法描述:
- 选择一个最好的划分属性
- 用最好的属性划分D,并从属性列表中删除该属性。
- 对每个子集,如果属性已经用完,返回类别标签。否则对每个子集,重复1步骤。
python2.x 代码实现
# 使用坐标为axis的属性划分dataSet,将该属性的值等于value的样本返回。并且从样本中删除该属性 def splitDataSet(dataSet,axis,value): retDataSet = [] for featVec in dataSet: if featVec[axis] == value: reducedFeatVec = featVec[:axis] reducedFeatVec.extend(featVec[axis+1:]) retDataSet.append(reducedFeatVec) return retDataSet # 选择最好的划分属性,它返回的是属性在属性向量中的位置(坐标) def chooseBestFeatureToSplit(dataSet): numFeatures = len(dataSet[0]) - 1 baseEntropy = calcShannonEnt(dataSet) bestInfoGain = 0.0 bestFeature = -1 for i in range(numFeatures): featList = [example[i] for example in dataSet] uniqueVals = set(featList) newEntropy = 0.0 for value in uniqueVals: subDataSet = splitDataSet(dataSet,i,value) prob = len(subDataSet)/float(len(dataSet)) newEntropy += prob * calcShannonEnt(subDataSet) infoGain = baseEntropy - newEntropy if(infoGain>bestInfoGain): bestInfoGain = infoGain bestFeature = i return bestFeature # dataSet 中的向量包含了属性和类别 def createTree(dataSet,labels): # 取所有的类别 classList = [example[-1] for example in dataSet] # 如果所有的类别都相同,就返回 if classList.count(classList[0]) == len(classList): return classList[0] # 如果dataSet中已经没有属性了,表示所有的属性已经被遍历完,就返回出现次数最多的属性 if len(dataSet[0] == 1): return majorityCnt(classList) # 选择一个最好的划分属性 bestFeat = chooseBestFeatureToSplit(dataSet) bestFeatLabel = labels[bestFeat] myTree = {bestFeatLabel:{}} del(labels[bestFeat]) featValues = [example[bestFeat] for example in dataSet] uniqueVals = set(featValues) for value in uniqueVals: subLabels = labels[:] myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels) return myTree def majorityCnt(classList): classCount={} for vote in classList: if vote not in classCount.keys():classCount[vote] = 0 classCount[vote]+=1 sortedClassCount = sorted(classCount.iteritems(), key = operator.itemgetter(1),reverse = True) return sortedClassCount[0][0]
这里的决策树用的是python的字典嵌套来表示。字典每一层的key由属性名和属性值交替,如果这一层的key是属性名,表示由该属性名进行划分,下一层的字典就是该属性的所有可能的取值。然后每一个对于每一个取值,再选一个属性名。如果没有属性名可选,最终的字典就是类别。具体的含义可以参考这篇博客:python中字典{}的嵌套。他里面用的例子刚好是这篇机器学习的代码。
最后一个函数是为了解决叶子节点有多种结果情况。选择出现次数最多的结果返回。函数createTree中第二个参数labels是属性的名称,一般类型是字符串,比如‘色泽’,‘外观’,‘触感’之类的。而第一个参数dataSet中的属性是属性的值。
其他
上述代码中构造的决策树是一个嵌套字典。具体如何使用,其实就是下标索引,在上面给出的博客中也有讲。
决策树的构建过程耗时比较长,但是构建好之后测试样本就很快。他不同于上一篇的KNN,KNN每次需要测试样本的时候,都需要重新训练一次,即‘懒惰学习’。决策树只有在拿到新的训练样本的时候才需要训练,以后需要测试样本都可以调用已经构建好的决策树,即‘急切学习’。关于构建出来的用嵌套字典表示的决策树如何绘制出来和存储,在《机器学习实战》里面也有详细提到,分别用matplotlib和pickle库。因为我这两个都不会用,python也是先学不到两周,还需要学习,所以就不搬运了。如果什么时候觉得这非常需要作篇博客以表学习,那到时就另起一篇,放在python分类中。
增益率
西瓜书还提到这个概念。
是想,如果把训练样本的每一个样本都作编号,然后把编号也作为属性参与决策。通过计算,编号产生的信息熵增益达到0.998,远高于其他属性。这很好理解:每一个编号都产生一个分支,每个分支仅仅包含一个样本,这样就完全不需要考虑其他属性了。然而,这样的决策树并不具有泛化能力,无法对新样本做出有效预测。
信息增益准则对取值数目多的属性有偏好。意思是,一个属性的取值越多,越有可能被选为当前最好的划分属性。为了解决这种偏好带来的不利映像,著名的C4.5决策树算法不直接使用信息增益,而是使用“增益率”来选择最优划分属性。增益率定义为:
$Gain\\_ratio(D,a) = frac{Gain(D,a)}{IV(a)}$
其中
$IV(a) = -Sigma frac{|D^v|}{|D|}log_2frac{|D^v|}{|D|}$
$IV(a)$称为属性a的“固有值”。属性a的可能取值越多,固有值越大,增益率越小。可以看到,原本的信息增益使用属性的固有值进行了加权,消除了原本算法对取值数目多的属性的偏好带来的影响。
西瓜书上还有一段:
需要注意的是,增益率准则对可取值数目较少的属性有所偏好,因此,C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
以上是关于决策树——Decision Tree的主要内容,如果未能解决你的问题,请参考以下文章