FutureTaskFork/Join BlockingQueue
Posted xiangkejin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FutureTaskFork/Join BlockingQueue相关的知识,希望对你有一定的参考价值。
import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Future; @Slf4j public class FutureExample { static class MyCallable implements Callable<String> { @Override public String call() throws Exception { log.info("do something in callable"); Thread.sleep(5000); return "Done"; } } public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); Future<String> future = executorService.submit(new MyCallable()); log.info("do something in main"); //Thread.sleep(10000); log.info("这里不阻塞,可以继续异步执行"); String result = future.get(); //get方法会发生阻塞,如果判断任务是否执行完成使用isDone()方法 log.info("result:{}", result); } }
FutureTask
import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable; import java.util.concurrent.FutureTask; @Slf4j public class FutureTaskExample { public static void main(String[] args) throws Exception { FutureTask<String> futureTask = new FutureTask<String>(new Callable<String>() { @Override public String call() throws Exception { log.info("do something in callable"); Thread.sleep(5000); return "Done"; } }); new Thread(futureTask).start(); log.info("do something in main"); Thread.sleep(1000); String result = futureTask.get(); log.info("result:{}", result); } }
Fork/Join
用于并行执行任务的框架,将大任务分割成小任务,最终将每个小任务的结果汇总得到大任务结果的框架。
思想和map/reduce非常像,Fork就是讲大任务分割成小任务,Join就是合并子任务的结果。
工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
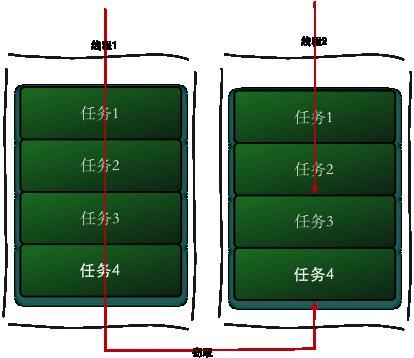
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
Fork/Join使用两个类来完成以上两件事情:
ForkJoinPool :它负责实现,包括我们的工作窃取算法,它管理工作线程和任务状态以及执行信息
ForkJoinTask:主要提供fork和join的机制
import lombok.extern.slf4j.Slf4j; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.Future; import java.util.concurrent.RecursiveTask; @Slf4j public class ForkJoinTaskExample extends RecursiveTask<Integer> { public static final int threshold = 2; private int start; private int end; public ForkJoinTaskExample(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { int sum = 0; //如果任务足够小就计算任务 boolean canCompute = (end - start) <= threshold; if (canCompute) { for (int i = start; i <= end; i++) { sum += i; } } else { // 如果任务大于阈值,就分裂成两个子任务计算 int middle = (start + end) / 2; ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle); ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end); // 执行子任务 leftTask.fork(); rightTask.fork(); // 等待任务执行结束合并其结果 int leftResult = leftTask.join(); int rightResult = rightTask.join(); // 合并子任务 sum = leftResult + rightResult; } return sum; } public static void main(String[] args) { ForkJoinPool forkjoinPool = new ForkJoinPool(); //生成一个计算任务,计算1+2+3+4 ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100); //执行一个任务 Future<Integer> result = forkjoinPool.submit(task); try { log.info("result:{}", result.get()); } catch (Exception e) { log.error("exception", e); } } }
BlockingQueue
认识BlockingQueue
阻塞队列,顾名思义,首先它是一个队列,而一个队列在数据结构中所起的作用大致如下图所示:
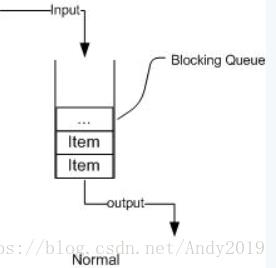
从上图我们可以很清楚看到,通过一个共享的队列,可以使得数据由队列的一端输入,从另外一端输出;
常用的队列主要有以下两种:(当然通过不同的实现方式,还可以延伸出很多不同类型的队列,DelayQueue就是其中的一种)
先进先出(FIFO):先插入的队列的元素也最先出队列,类似于排队的功能。从某种程度上来说这种队列也体现了一种公平性。
后进先出(LIFO):后插入队列的元素最先出队列,这种队列优先处理最近发生的事件。
多线程环境中,通过队列可以很容易实现数据共享,比如经典的“生产者”和“消费者”模型中,通过队列可以很便利地实现两者之间的数据共享。假设我们有若干生产者线程,另外又有若干个消费者线程。如果生产者线程需要把准备好的数据共享给消费者线程,利用队列的方式来传递数据,就可以很方便地解决他们之间的数据共享问题。但如果生产者和消费者在某个时间段内,万一发生数据处理速度不匹配的情况呢?理想情况下,如果生产者产出数据的速度大于消费者消费的速度,并且当生产出来的数据累积到一定程度的时候,那么生产者必须暂停等待一下(阻塞生产者线程),以便等待消费者线程把累积的数据处理完毕,反之亦然。然而,在concurrent包发布以前,在多线程环境下,我们每个程序员都必须去自己控制这些细节,尤其还要兼顾效率和线程安全,而这会给我们的程序带来不小的复杂度。好在此时,强大的concurrent包横空出世了,而他也给我们带来了强大的BlockingQueue。(在多线程领域:所谓阻塞,在某些情况下会挂起线程(即阻塞),一旦条件满足,被挂起的线程又会自动被唤醒)
下面两幅图演示了BlockingQueue的两个常见阻塞场景:
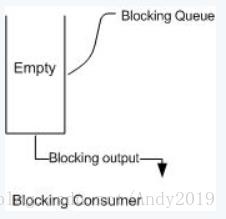
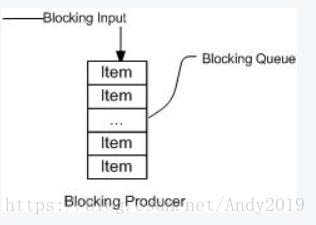
如上图所示:当队列中填满数据的情况下,生产者端的所有线程都会被自动阻塞(挂起),直到队列中有空的位置,线程被自动唤醒。
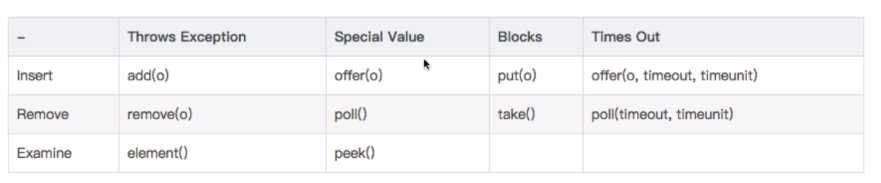
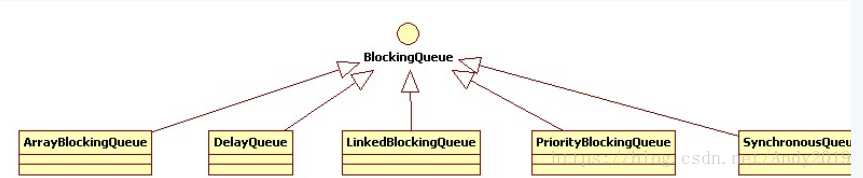
1. ArrayBlockingQueue
基于数组的阻塞队列实现,在ArrayBlockingQueue内部,维护了一个定长数组,以便缓存队列中的数据对象,这是一个常用的阻塞队列,除了一个定长数组外,ArrayBlockingQueue内部还保存着两个整形变量,分别标识着队列的头部和尾部在数组中的位置。
ArrayBlockingQueue在生产者放入数据和消费者获取数据,都是共用同一个锁对象,由此也意味着两者无法真正并行运行,这点尤其不同于LinkedBlockingQueue
2. LinkedBlockingQueue
基于链表的阻塞队列,同ArrayListBlockingQueue类似,其内部也维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
作为开发者,我们需要注意的是,如果构造一个LinkedBlockingQueue对象,而没有指定其容量大小,LinkedBlockingQueue会默认一个类似无限大小的容量(Integer.MAX_VALUE),这样的话,如果生产者的速度一旦大于消费者的速度,也许还没有等到队列满阻塞产生,系统内存就有可能已被消耗殆尽了。
ArrayBlockingQueue和LinkedBlockingQueue是两个最普通也是最常用的阻塞队列,一般情况下,在处理多线程间的生产者消费者问题,使用这两个类足以。
以上是关于FutureTaskFork/Join BlockingQueue的主要内容,如果未能解决你的问题,请参考以下文章
一文带你了解J.U.C的FutureTaskFork/Join框架和BlockingQueue