浅谈二维线段树的几种不同的写法
Posted zhangjianjunab
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈二维线段树的几种不同的写法相关的知识,希望对你有一定的参考价值。
参考文献
四叉树
树套树
以及和zhoufangyuan巨佬的激烈♂讨论
参考文献
大家好我口糊大师又回来了。
给你一个(n*n)矩阵,然后让你支持两种操作,对子矩阵加值和对子矩阵查和。
暴力写法
对于每一行开一个线段树,然后跑,时间复杂度(n^2logn)。
优点:
- 代码较短
- 较为灵活
缺点:
- 常数大
- 容易卡
二叉树
我们对于平面如此处理,一层维护横切,一层竖切。
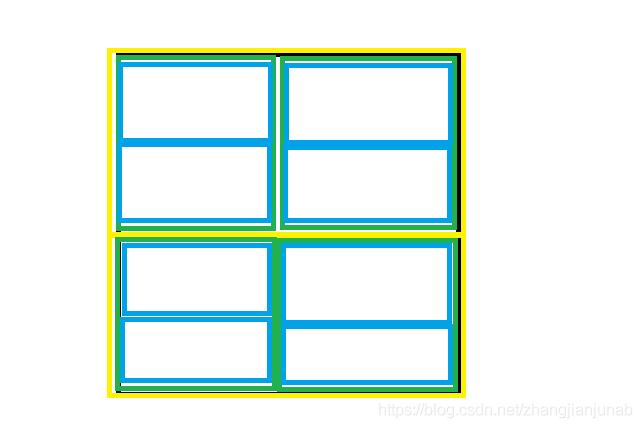
当然,这个做法也是(n^2logn)的,卡法就是任意一行的全加值。
优点:
- 时间复杂度比较平均。
缺点:
- 时间复杂度还是这么垃圾。
四叉树
那么不能两两分就四四分!
即把一个区域分成四份。
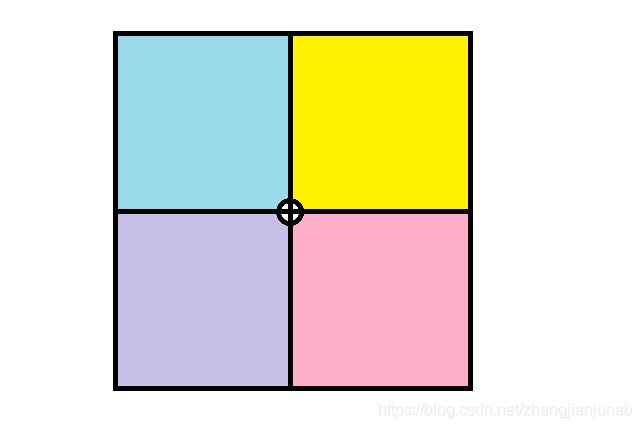
当然还有这两种特殊情况。

很可惜,一样的卡法,还是那个(n^2logn)的味道。
来自参考文献的代码
//神奇的码风,等我哪一天码了一个类似的代码,就把这个换了吧,但是最近没时间。
#include<cstdio>
#include<iostream>
#include<algorithm>
#include<cstring>
#include<map>
#include<cmath>
#define ll long long
#define max(x,y) ((x)>(y)?(x):(y))
#define min(x,y) ((x)<(y)?(x):(y))
#define fur(i,x,y) for(i=x;i<=y;i++)
#define fdr(i,x,y) for(i=x;i>=y;i--)
#define Fur(i,x,y) for(ll i=x;i<=y;i++)
#define Fdr(x,y) for(ll i=x;i>=y;i--)
#define in2(x,y) in(x);in(y)
#define in3(x,y,z) in2(x,y);in(z)
#define in4(a,b,c,d) in2(a,b);in2(c,d)
#define clr(x,y) memset(x,y,sizeof(x))
#define cpy(x,y) memcpy(x,y,sizeof(x))
using namespace std;
/*---------------------------------------*/
namespace fib{char b[300000]= {},*f=b;}
#define gc ((*fib::f)?(*(fib ::f++)):(fgets(fib::b,sizeof(fib::b),stdin)?(fib::f=fib::b,*(fib::f++)):-1))
inline void in(ll &x){x=0;char c;bool f=0;while((c=gc)>'9'||c<'0')if(c=='-')f=!f;x=c-48;while((c=gc)<='9'&&c>='0')x=x*10+c-48;if(f)x=-x;}
namespace fob{char b[300000]= {},*f=b,*g=b+300000-2;}
#define pob (fwrite(fob::b,sizeof(char),fob::f-fob::b,stdout),fob::f=fob::b,0)
#define pc(x) (*(fob::f++)=(x),(fob::f==fob::g)?pob:0)
struct foce{~foce(){pob;fflush(stdout);}} _foce;
namespace ib{char b[100];}
inline void out(ll x){if(x==0){pc(48);return;}if(x<0){pc('-');x=-x;}char *s=ib::b;while(x) *(++s)=x%10,x/=10;while(s!=ib::b) pc((*(s--))+48);}
inline void outn(ll x){out(x);pc('
');}//快速输出
inline ll jdz(ll x){return x>0?x:-x;}//绝对值
/*------------------------------------------------------------------------------------------------*/
/*------------------------------------------------------------------------------------------------*/
#define N 2334
#define c1 (rt*4-2)
#define c2 (rt*4-1)
#define c3 (rt*4)
#define c4 (rt*4+1)
#define z1 x1,y1,mx,my
#define z2 x1,my+1,mx,y2
#define z3 mx+1,y1,x2,my
#define z4 mx+1,my+1,x2,y2
#define Z ll mx=(x1+x2)>>1,my=(y1+y2)>>1
#define U ll x1,ll y1,ll x2,ll y2,ll rt
#define pu s[rt]=s[c1]+s[c2]+s[c3]+s[c4]//push_up
ll s[N*N*4],laz[N*N*4],a[N][N],n,m,q,g[N*N*4];
bool b[N*N*4];
inline ll gs(ll x1,ll y1,ll x2,ll y2){return (jdz(x1-x2)+1)*(jdz(y1-y2)+1);}
inline void pd(ll rt,ll n1,ll n2,ll n3,ll n4){
if(laz[rt]){ll &t=laz[rt];
s[c1]+=n1*t;s[c2]+=n2*t;s[c3]+=n3*t;s[c4]+=n4*t;
laz[c1]+=t;laz[c2]+=t;laz[c3]+=t;laz[c4]+=t;
t=0;
}
}
inline void build(U){
g[rt]=gs(x1,y1,x2,y2);
if(x1==x2&&y1==y2){s[rt]=a[x1][y1];return;}
Z;
build(z1,c1);if(y1!=y2)build(z2,c2);else b[c2]=1;
if(x1!=x2)build(z3,c3);else b[c3]=1;if(x1!=x2&&y1!=y2)build(z4,c4);else b[c4]=1;
pu;
}
inline void upd(ll X1,ll Y1,ll X2,ll Y2,ll v,U){
if(b[rt])return;
if(X1<=x1&&Y1<=y1&&x2<=X2&&y2<=Y2){s[rt]+=gs(x1,y1,x2,y2)*v;laz[rt]+=v;return;}
Z;pd(rt,g[c1],g[c2],g[c3],g[c4]);
if(X1<=mx&&Y1<=my)upd(X1,Y1,X2,Y2,v,z1,c1);
if(X1<=mx&&Y2>my)upd(X1,Y1,X2,Y2,v,z2,c2);
if(X2>mx&&Y1<=my)upd(X1,Y1,X2,Y2,v,z3,c3);
if(X2>mx&&Y2>my)upd(X1,Y1,X2,Y2,v,z4,c4);
pu;
}
inline ll qh(ll X1,ll Y1,ll X2,ll Y2,U){
if(b[rt])return 0;
if(X1<=x1&&Y1<=y1&&x2<=X2&&y2<=Y2)return s[rt];
Z,ans=0;pd(rt,g[c1],g[c2],g[c3],g[c4]);
if(X1<=mx&&Y1<=my)ans+=qh(X1,Y1,X2,Y2,z1,c1);
if(X1<=mx&&Y2>my)ans+=qh(X1,Y1,X2,Y2,z2,c2);
if(X2>mx&&Y1<=my)ans+=qh(X1,Y1,X2,Y2,z3,c3);
if(X2>mx&&Y2>my)ans+=qh(X1,Y1,X2,Y2,z4,c4);
return ans;
}
int main(){
in3(n,m,q);
Fur(i,1,n)Fur(j,1,m)in(a[i][j]);
build(1,1,n,m,1);
ll p,x1,y1,x2,y2,v;
while(q--){
in(p);in4(x1,y1,x2,y2);
if(p==1)outn(qh(x1,y1,x2,y2,1,1,n,m,1));
else{in(v);upd(x1,y1,x2,y2,v,1,1,n,m,1);}
}
}优点:
- 常数更小了。
缺点:
- 代码更长了。
- 时间复杂度吃屎般的大。
当然,最后被吐槽说上面两种都是KDT,其实个人也觉得挺像的。
树套树写法1
这才是重头戏。
论如何树套树搞?
当然这个一般只能维护区间赋值和区间加值,或者偶尔某些神奇的维护也可以用这个。
当然一般也可以用二维树状数组来搞,以后再学吧。
我们需要理解一个永久化标记的东西。就是曾经我以为自己是第一个YY出这个的东西,上网一查,啪啪打脸的那玩意。
当一个点赋上了永久化标记,这个标记不会下传,而是在递归的时候,在记录标记。
对于外层线段树,维护的是行,对于内层线段树,维护的是列,不过代码是两棵,一棵是找。
如果一个外层节点维护的是(1,2)行,那么他里面维护的就是([(1,l),(2,r)])的矩阵的信息。
对于外层叶子结点的内层线段树,仅仅维护这一行的和,但是非叶子结点的内层线段树的节点就是非叶子节点的左右儿子节点的内层线段树的相应节点之和。
那么我们来看一个例子:
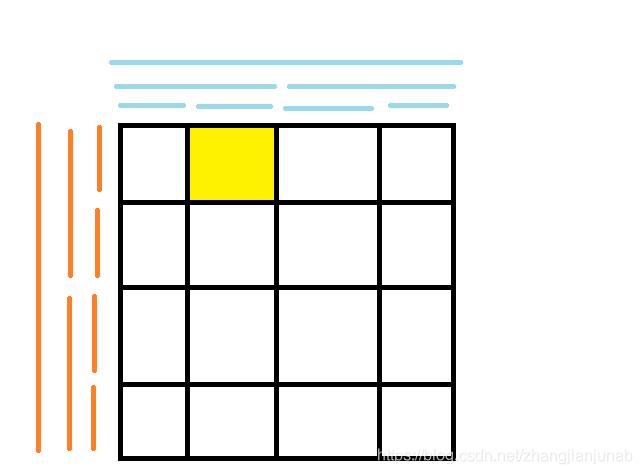
图片解释:对于每个橙色节点,他都维护了一棵绿色的线段树,那么黄色就是我们加值的点,设加(k)
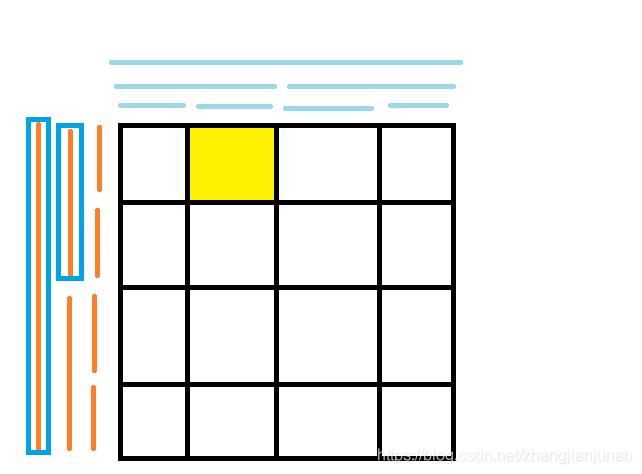
那么因为加值在第(1)行,而蓝色框住的节点维护的行范围包括但不是等于第(1)行,我们就统计他的影响,很明显在第(2)列总共加了(k)(如果是竖着的两格就是(2k),不过第二个蓝色框框是全覆盖了),那么对于维护第(1)行的叶子结点,我们再修改统计和的内层线段树的同时,我们也要对于永久化标记的线段树,给第(2)列打上(k)的永久化标记。
而对于下面的进阶情况:
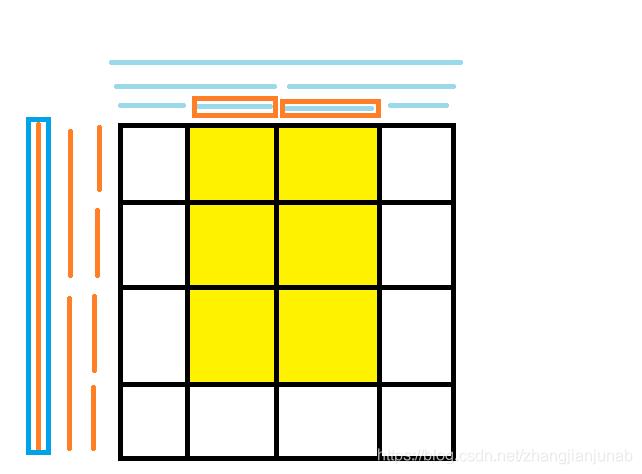
我们需要对于外层根节点的统计和的内层线段树在[2,3]列加上(3k)的值,因为是统计和,所以我们可以统计出修改对于上层节点的内层线段树的影响。(最大值就不能直接统计)
当然,外层节点([3,4])行的([2,3])列的和也是加(k),对于维护([1,2])行的节点,我们需要在([2,3])列打上永久化标记(k),这时候你问了,为什么不是(2k),完全覆盖一列(2k)呀?因为我们以后到了这个节点,我们可以查出在([1,2])行的任意一行的([2,3])列打的标记,然后根据询问的行数,再乘以行数,不然标记会局限于当查询行数完全覆盖才能查标记导致TLE或者WA,打完标记后退出。
内层(log),外层(log),(log^2)时间
查询就是对于沿路经过的外层节点,查询列的标记,乘以查询的行数,并在查询行数覆盖的节点直接查和。
(log^2)
来自参考文献的代码:
//这个代码还算友善
#include<cstdio>
#define gc getchar
int gi(){int x=0,f=0;char c=gc();while(c<'0'||'9'<c){if(c=='-')f=!f;c=gc();}while('0'<=c&&c<='9'){x=x*10+c-48;c=gc();}return f?(-x):x;}
using namespace std;
#define N 2010
int D,S,q;
struct xds{//内层(标记永久化)
#define Z int m=(l+r)>>1
#define ls rt<<1
#define rs rt<<1|1
int s[N*4],tag[N*4]/*内层也用永久化标记。。。*/;
void build(int l,int r,int rt){//内层建树
if(l==r){s[rt]=gi();return;}
Z;build(l,m,ls);build(m+1,r,rs);
s[rt]=s[ls]+s[rs];
}
void upd(int L,int R,int v,int l,int r,int rt){//内层修改
s[rt]+=v*(R-L+1);
if(L==l&&r==R){
tag[rt]+=v;
return;
}
Z;
if(R<=m)upd(L,R,v,l,m,ls);
else{
if(L>m)upd(L,R,v,m+1,r,rs);
else upd(L,m,v,l,m,ls),upd(m+1,R,v,m+1,r,rs);
}
}
int qh(int L,int R,int l,int r,int rt,int ad){
if(L==l&&r==R)return s[rt]+ad*(r-l+1);
Z;ad+=tag[rt];
if(R<=m)return qh(L,R,l,m,ls,ad);
else{
if(L>m)return qh(L,R,m+1,r,rs,ad);
else return qh(L,m,l,m,ls,ad)+qh(m+1,R,m+1,r,rs,ad);
}
}
}s[N*4]/*维护和*/,tag[N*4]/*维护永久化标记*/;
void mg(xds& o,xds& lc,xds& rc,int l,int r,int rt){//外层节点更新(pushup)
o.s[rt]=lc.s[rt]+rc.s[rt];
if(l==r)return;
Z;mg(o,lc,rc,l,m,ls);mg(o,lc,rc,m+1,r,rs);
}
void build(int l,int r,int rt){//外层建树
if(l==r){
s[rt].build(1,S,1);
return;
}
Z;build(l,m,ls);build(m+1,r,rs);
mg(s[rt],s[ls],s[rs],1,S,1);
}
void upd(int x,int y,int xx,int yy,int v,int l,int r,int rt){//外层修改
s[rt].upd(y,yy,v*(xx-x+1),1,S,1);//沿路改和
if(x==l&&r==xx){
tag[rt].upd(y,yy,v,1,S,1);//改标记
return;
}
Z;
if(xx<=m)upd(x,y,xx,yy,v,l,m,ls);
else{
if(x>m)upd(x,y,xx,yy,v,m+1,r,rs);
else upd(x,y,m,yy,v,l,m,ls),upd(m+1,y,xx,yy,v,m+1,r,rs);
}
}
int qh(int x,int y,int xx,int yy,int l,int r,int rt,int ad){//查询(求和)
if(x==l&&r==xx)return s[rt].qh(y,yy,1,S,1,0)+ad*(r-l+1);
Z;ad+=tag[rt].qh(y,yy,1,S,1,0);//查标记
if(xx<=m)return qh(x,y,xx,yy,l,m,ls,ad);
else{
if(x>m)return qh(x,y,xx,yy,m+1,r,rs,ad);
else return qh(x,y,m,yy,l,m,ls,ad)+qh(m+1,y,xx,yy,m+1,r,rs,ad);
}
}
int main(){
D=gi();S=gi();q=gi();
build(1,D,1);
int p,x,y,xx,yy;
while(q--){
p=gi();x=gi();y=gi();xx=gi();yy=gi();
if(p==1)printf("%d
",qh(x,y,xx,yy,1,D,1,0));
else upd(x,y,xx,yy,gi(),1,D,1);
}
}优点:
- 时间复杂度优秀。
- 因为使用永久化标记,常数较小。
以及用主席树支持可持久化
缺点:
- 不能支持最大值。
- 思想复杂。
空间变大
树套树写法2
如何支持求最大值呢。
比如最近这道题目。
即使这道题目随便用四叉树爆叉。
但是时间复杂度还是太慢了!!!!
于是我就去请教机房巨佬之神,膜拜(1e∞)后,zhoufangyuan巨佬为之撼动,教了我一个做法,继续爆切黑题。
就是一样是对于行完全覆盖的外层节点的内层线段树,我们一样可以打个永久化标记,然后维护最大值,但是不一样的是,我们发现跑每个叶子节点内层线段树所经过的节点都是一样的,且是(logn)个的,我们可以先建个线段树,把列的范围扔进去,然后处理出那么会被访问节点。
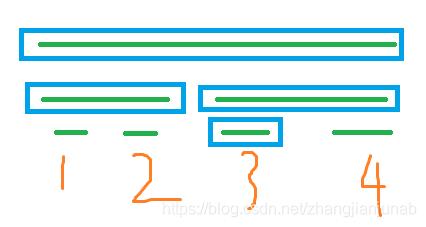
就是蓝色框框中的点。(而且因为每层最多两个节点被访问,所以数量级为(logn))
然后我们一如既往的跑一遍外层修改,然后也是把行完全覆盖的外层节点的内层节点改一下,然后对于行未完全覆盖的外层节点,就是把自己内层线段树中的蓝色框住的点的最大值,去合并左右儿子蓝色框柱的点的最大值就是了,这样就可以用(log^2)代替原本(log^2)就可以计算的部分影响,无伤大雅,果然远哥一想就是一个神仙。
其实就是把部分影响的维护方法给了一下,但是却可以多维护大量的信息。
都是口糊的了,哪有代码。优点:
- 维护信息多。
- 时间复杂度优秀。
缺点:
- 代码打起来有点抽。
- 大部分缺点与写法1类似。
以上是关于浅谈二维线段树的几种不同的写法的主要内容,如果未能解决你的问题,请参考以下文章
iOS之浅谈纯代码控制UIViewController视图控制器跳转界面的几种方法
iOS之浅谈纯代码控制UIViewController视图控制器跳转界面的几种方法
一张图,理顺 Spring Boot应用在启动阶段执行代码的几种方式