[补档计划] 字符串 之 知识点汇总
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[补档计划] 字符串 之 知识点汇总相关的知识,希望对你有一定的参考价值。
学习一个算法, 需要弄清一些地方
① 问题与算法的概念
② 算法以及其思维轨迹
③ 实现以及其思维轨迹
④ 复杂度分析
⑤ 应用
KMP算法
字符串匹配与KMP算法
为了方便弄清问题, 应该从特例入手.
设 A = " ababababb " , B = " ababa " , 我们要研究下面三个递进层次的字符串匹配问题:
① 是否存在 A 的子串等于 B
② 有几个 A 的子串等于 B
③ A 的哪些位置的子串等于 B
KMP算法可以直接在线性复杂度解决问题③, 进而更可以解决问题①和问题②.
KMP算法
最先的想法必然是 Brute Force: 枚举 S 的匹配的开头位置, 将 S 与 T 逐位进行匹配. 虽然在随机数据下优秀, 但是遇上极端数据很不理想.
我们考虑利用匹配的特性进行优化. 如下图所示, 匹配到 S[L:R] = T[1:r] , 发现 S[R+1] != T[r+1] . 考虑另一个匹配位置 B , 如果 B 在 S 内能匹配成功, 则需要满足一个必要条件: S[B:R] = T[1:R-B+1] , 而 S[B:R] = T[r-(R-B+1)+1 : r] , 所以 T[1:r] 的长度为 $len=R-B+1$ 的前缀要等于长度为 $len$ 的后缀. 为了不遗漏所有的情况, B 要尽可能的小, 我们要取最大的 len = ex[r] , 使得 T[1:len] = T[r-len+1 : r] .
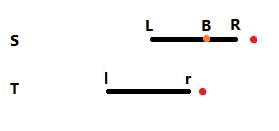
现在问题的焦点在于如何求 ex 数组. 我们发现求 ex 数组的方法可以递推(基底+转移), 和上述方法的流程是一样的.
算法实现
#define F(i,a,b) for (register int i=(a);i<=(b);i++) int nS; char s[S]; int nx[S]; int nT; char t[T]; bool KMP(void) { for (int i=2,j=0;i<=nS;i++) { while (j<=nS && s[i]!=s[j+1]) j=nx[j]; nx[i] = (s[i]==s[j+1] ? ++j : j); } for (int i=1,j=0;i<=nT;i++) { while (j<=nT && t[i]!=s[j+1]) j=nx[j]; if (s[i]==s[j+1]) { j++; if (j==nT) return true; } } return false; }
复杂度分析
由于每次 j 只会往后移一位, 所以往后移的总位数为 O(n) . 每次 j 往前跳, 至少会跳一位, 所以往前跳的总次数为 O(n) . 综上, 均摊时间复杂度为 O(n) .
Manacher 算法
EX 数组
回文串分为两种: 奇回文串, 偶回文串.
从特殊向一般演进, 我们先研究奇回文串的信息如何快速处理. 为了刻画, 我们引入了 ex 数组: 给定一个字符串 S , 对它的每个位置有 ex[i] , ex[i] 为最大的使 S[i-t+1 : i+t-1] 为回文串的 t 的值. 举个例子, S = "ababaab" ,则有: ex[1]=1, ex[2]=2, ex[3]=3, ex[4]=2, ex[5]=1, ex[6]=1, ex[7]=1, ex[8]=1.
Manacher算法, 可以在线性复杂度求出 ex 数组.
Manacher算法
与KMP类似, 首先考虑 Brute Force, 然后使用匹配的连续性进行优化. 网上资料很多, 这里不赘述.
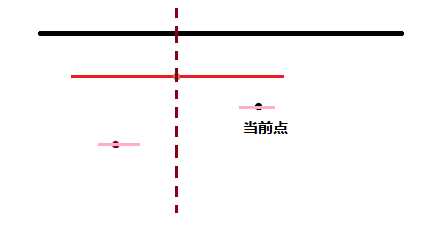
实现
void Manacher(void) { len=n+n+1, t[0]=‘<‘, t[1]=‘+‘, t[len+1]=‘>‘; F(i,1,n) t[2*i]=s[i], t[2*i+1]=‘+‘; for (int i=1, k=0; i<=len; i++) { int j = (k+ex[k]-1<=i ? 0 : min(k+ex[k]-i, ex[k+k-i])); while (t[i+j]==t[i-j]) j++; ex[i]=j; if (i+ex[i] > k+ex[k]) k=i; } }
复杂度分析
每次都是最远点往后拓展, 每个点不会拓展两次, 所以时间复杂度均摊 $O(n)$ .
偶回文串
以某个字符为对称轴的所有回文串, 即奇回文串的信息, 可以通过 Manacher 求出来. 现在将偶回文串的坑也给填了.
我们考虑化归, 将 S 变为 T, T 与 S 有一定的联系, 对 T 用 Manacher, 就可以转化回来.
具体的, T[0] = ‘<‘ , T[1] = ‘+‘ , T[2n] = S[n], T[2n+1] = ‘+‘ , T[2n+2] = ‘>‘ , 对 T 用 Manacher, 得到 ex[1..2n+1] .
位置上的转化关系:
从 S 到 T : T[2n] = S[n].
从 T 到 S : 当 n 为偶数时, S[n/2] = T[n].
T 的 ex 数组:
当 i 为偶数时, $ex_S[i/2]=ex_T[i]/2$ ;
当 i 为奇数时, 以 S[(i-1)/2] 和 S[(i+1)/2] 的中心的 $ex = (ex_T[i]-1)/2$ ;
这个不能死记硬背, 关键明白位置上的转化关系, 举一个例子看看就好了.
回文自动机
PAM : Palindrome Automaton, 回文自动机.
对一种自动机的学习, 我们要弄清: 概念, 构建, 实现, 复杂度分析, 应用, 例题.
有两篇写得很好的资料.
http://blog.csdn.net/maticsl/article/details/43651169
http://blog.csdn.net/u013368721/article/details/42100363
PAM 的概念
对于一个字符串 S, 可以构建一个唯一的 PAM. PAM 可以刻画字符串 S 的回文子串的信息.
PAM 由 点 和 边 组成.
点 PAM 的每个点, 对应一个本质不同的回文子串, 用回文子串的长度 len 和一个虚拟的编号来刻画.
对于一个字符串 S , 有这样一个性质: 它的回文子串最多只有 $|S|$ 个. 来一个简单的无字证明:
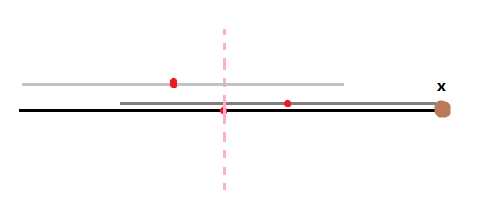
边 边分为两类: 后继边 和 Suffix Link.
后继边 如果 u 通过标记字符为 c 的后继边连向 v , 则 v = cuc
Suffix Link 最长后缀回文串对应的编号.
PAM 的构建
我们考虑递归构建, 在线末端插入: 构建 S[1:1] 的 PAM, 构建 S[1:2] 的 PAM, ..., 构建 S[1:n] 的 PAM.
为了构建的顺利, 我们需要引入辅助变量 last: 当前前缀的最长后缀回文串对应的虚拟编号, tot: 结点个数.
初始化 构建两个点, len[0] = 0, len[1] = -1, suf[0] = -1 ;
末端插入字符 c 沿 last 往前跳, 直到找到第一个 s[n] = s[n-len-1] 的位置 cur, 顺便把这个过程叫做 Find.
如果 cur 没有 c 后继, 则建立点 now.
len[now] = len[cur] + 2.
suf 怎么处理呢? 宏观上, 继续 t=Find(suf[cur]) , 然后 suf[now] = next[t][c] . 微观上, 发现 0, 1, 或者找不到等若干情况都能满足.
连接 next[cur][c] = now.
PAM 的实现
TIPS 对于长度为 $n$ 的字符串, PAM 需要用到的空间上限为 $n+1$ .
#include <cstdio> #include <cstring> #include <cstdlib> const int N = 100005; char s[N]; int nS; int tot, last; int suf[N], son[N][30]; int len[N]; int Find(int n, int cur) { while (s[n-len[cur]-1] != s[n]) cur = suf[cur]; return cur; } void Expand(int n, int c) { int cur = Find(n, last); if (!son[cur][c]) { int now = ++tot; len[now] = len[cur]+2; suf[now] = son[Find(n, suf[cur])][c]; son[cur][c] = now; } last = son[cur][c]; } int main(void) { #ifndef ONLINE_JUDGE freopen("A.in", "r", stdin); freopen("A.out", "w", stdout); #endif scanf("%s", s+1); nS = strlen(s+1); tot = 1, last = 0; suf[0] = 1; len[0] = 0, len[1] = -1; for (int i = 1; i <= nS; i++) Expand(i, s[i]-‘a‘); printf("%d\\n", tot-1); return 0; }
PAM 的复杂度
时间复杂度: $O(n)$
空间复杂度: $O(nA)$
PAM 的应用
由此可见, PAM 确乎地可以求出回文子串的一些信息, 那具体可以处理那些问题呢?
问题1 是否存在回文串? 是否存在长度大于 x 的回文串? 是否存在偶回文串?
一个字符串一定存在回文串.
找是否有节点的 len 大于 x.
找是否有节点的 len 为偶数.
问题2 列举所有本质不同的回文串.
在插入的时候, 对每个节点 x, 记录 end[x] 表示 x 节点表示的回文串的末端. 这样可以用 end[x] 和已有的 len[x], 输出回文串 S[ end[x]-len[x]+1 : end[x] ] .
问题3 求串 S 的本质不同的回文串个数. 求串 S 的所有前缀的不同回文串个数.
前缀 S[1:i] 的不同回文串个数, 为当前 PAM 的 tot-1.
问题4 求每个不同回文串出现的次数.
首先, 每个点多记录一个 cnt, 表示在构建的时候, 这个点作为最长后缀回文串的次数.
Suffix-Link 形成了一棵回文树. 每个不同回文串出现的次数, 即其等价节点在回文树上的子树 cnt 之和. 进行 DAG 上的递推.
问题5 求串 S 的回文串的个数. 求偶回文串的总数.
将每个不同的回文串出现的次数相加.
将每个不同的偶回文串出现的次数相加.
问题6 以下标 i 为结尾的回文串的个数.
在线构建 PAM 至 S[1:i] . 求 last 在回文树上对应节点的深度 - 2.
后缀数组
后缀数组的实现
对于一个字符串 S , 有后缀数组 sa[1..n] , 排名数组 rk[1..n], 和辅助数组 height[1..n].
sa[i]: 在 S 的后缀中, 排名第 i 的后缀为 S[sa[i]: n] .
rk[i]: 在 S 的后缀中, S[i:n] 的排名.
height[i]: S[sa[i-1]:n] 与 S[sa[i]:n] 的 LCP.
显然有 rk[sa[i]] = i, sa[rk[i]] = i.
使用倍增的方法快速求 sa[1..n] 和 rk[1..n] .
求 ht[1..n] 的时候, 我们依次处理 S[1:n], S[2:n], ..., S[n:n], 处理 S[i:n] 的时候求 ht[rk[i]] . Brute Force 的复杂度为 $O(n^2)$ , 但是我们可以利用一个性质: $ht[rk[i]] \\ge ht[rk[i-1]]-1$ , 附一个无字证明:
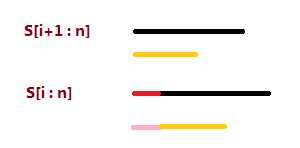
#include <cstdio> #include <cstring> #include <cstdlib> #define F(i, a, b) for (register int i = (a); i <= (b); i++) #define D(i, a, b) for (register int i = (a); i >= (b); i--) const int N = 50005; char s[N]; int n; int rk[N], sa[N], ht[N]; namespace Output { const int S = 1000000; char s[S]; char *t = s; inline void Print(int x) { if (x == 0) *t++ = ‘0‘; else { static int a[65]; int n = 0; for (; x > 0; x /= 10) a[++n] = x%10; while (n > 0) *t++ = ‘0‘+a[n--]; } *t++ = ‘ ‘; } inline void Flush(void) { fwrite(s, 1, t-s, stdout); } } using Output::Print; void Prework(void) { static int sum[N], trk[N], tsa[N]; int m = 500; F(i, 1, n) sum[rk[i] = s[i]]++; F(i, 1, m) sum[i] += sum[i-1]; D(i, n, 1) sa[sum[rk[i]]--] = i; rk[sa[1]] = m = 1; F(i, 2, n) rk[sa[i]] = (s[sa[i]] != s[sa[i-1]] ? ++m : m); for (int j = 1; m != n; j <<= 1) { int p = 0; F(i, n-j+1, n) tsa[++p] = i; F(i, 1, n) if (sa[i] > j) tsa[++p] = sa[i]-j; F(i, 1, n) sum[i] = 0, trk[i] = rk[i]; F(i, 1, n) sum[rk[i]]++; F(i, 1, m) sum[i] += sum[i-1]; D(i, n, 1) sa[sum[trk[tsa[i]]]--] = tsa[i]; rk[sa[1]] = m = 1; F(i, 2, n) { if (trk[sa[i]] != trk[sa[i-1]] || trk[sa[i]+j] != trk[sa[i-1]+j]) m++; rk[sa[i]] = m; } } m = 0; F(i, 1, n) { if (m > 0) m--; while (s[i+m] == s[sa[rk[i]-1]+m]) m++; ht[rk[i]] = m; } } int main(void) { #ifndef ONLINE_JUDGE freopen("xsy1621.in", "r", stdin); freopen("xsy1621.out", "w", stdout); #endif scanf("%s", s+1); n = strlen(s+1); Prework(); F(i, 1, n) Print(rk[i]); *(Output::t++) = ‘\\n‘; F(i, 1, n) Print(ht[i]); *(Output::t++) = ‘\\n‘; Output::Flush(); return 0; }
后缀自动机
http://blog.sina.com.cn/s/blog_70811e1a01014dkz.html
最简状态SAM
SAM, Suffix Automaton, 后缀自动机.
对于字符串 S , 构建 SAM. SAM 是一张 Trie图 , 能够恰好识别字符串 S 的所有子串.
如下图, 对于 S = ACADD , 构建了一个状态数为 $O(n^2)$ 的 SAM .
我们发现这很不优秀, "可能很难接受".
考虑优化: 发现很多空间是可以共用的. 因此, 我们要构建 最简状态SAM , 一个节点可能有多个父亲 .
具体地, SAM 由每个节点刻画, 而节点由以下三种变量刻画:
son[26]: 转移函数
pre: 如果当前节点可以接受新的后缀, 那么上一个能接受后缀的节点为 pre
step: 从根节点到当前节点的最长距离
SAM 的构建
SAM 的构建过程可以概括为 逐位插入末尾, 在线构建 . 具体地, 先构建 Prefix(1) 的 SAM, 再构建 Prefix(2) 的 SAM, 再构建 Prefix(3) 的SAM, ..., 构建 Prefix(n) 即 S 的 SAM. 因此, SAM 也可以处理 S 的任意一个前缀的信息.
为了方便阐述, 先提出 SAM 的几个显而易见的命题:
① 根据 SAM 的定义, 从 root 到任意节点p 的每条路径上的字符组成的字符串, 都是 S 的子串.
② 对 "接受后缀的节点" 的定义 , 如果当前节点 p 是可以接受后缀的节点, 那么从 root 到当前节点p 的每条路径上的字符组成的字符串, 都是 S 的后缀.
③ 对 pre 的定义, 如果当前节点 p 是可以接受后缀的节点, 那么 pre 也是可以接受后缀的节点.
④ 对 pre 的定义, 从 root 到 pre 的每条路径上的字符组成的字符串, 是从 root 到任意节点 p 的每条路径上的字符组成的字符串的后缀.
现在考虑怎样由 t 的 SAM 构建 tx 的 SAM.
我们需要记录构建 t 时的新增的节点 last, 这个节点一定可以接受后缀; 以及记录当前 SAM 的节点总数 tot , 以方便新增节点.
新建节点 np , 从 p = last 沿着 pre 往前跳, 记 son[t][x] = np, 直到 q = son[t][x] 存在. 这时候分两种情况讨论:
① step[q] = step[p] + 1
这种情况下, 从 root 到 p 的路径上全为 t 的后缀, 且 q 的唯一到达方式是通过 p.
所以从 root 到 q 的路径上亦全为 tx 的后缀, 所以 q 可以当做 np, 将 pre[np] 连向 q.
② step[q] > step[p] + 1
说明 q 的唯一到达方式不是 p , 那么考虑化归到第一种情况.
新建节点 nq, 将 q 的信息复制到 nq 上, p 以及之前连向 q 的节点改连到 nq 上, pre[nq] = pre[q], pre[q] = pre[np] = nq.
SAM 的实现
#include <cstdio> #include <cstring> #include <cstdlib> #define F(i, a, b) for (register int i = (a); i <= (b); i++) #define D(i, a, b) for (register int i = (a); i >= (b); i--) const int N = 200; char s[N]; int n; int tot, last; int son[N][26], suf[N], len[N]; char t[N]; int cnt; inline int Newnode(int L) { return len[++tot] = L, tot; } void Expand(int c) { int p = last, np = Newnode(len[last]+1); for (; p > 0 && !son[p][c]; p = suf[p]) son[p][c] = np; if (p == 0) suf[np] = 1; else { int q = son[p][c]; if (len[p]+1 == len[q]) suf[np] = q; else { int nq = Newnode(len[p]+1); memcpy(son[nq], son[q], sizeof son[q]); suf[nq] = suf[q], suf[q] = suf[np] = nq; for (; p > 0 && son[p][c] == q; p = suf[p]) son[p][c] = nq; } } last = np; } void DFS(int x) { printf("%s\\n", t+1); for (int i = 0; i < 26; i++) if (son[x][i] > 0) { t[++cnt] = ‘A‘+i; DFS(son[x][i]); t[cnt--] = 0; } } int main(void) { #ifndef ONLINE_JUDGE freopen("sam.in", "r", stdin); freopen("sam.out", "w", stdout); #endif scanf("%s", s+1); n = strlen(s+1); tot = last = 1; F(i, 1, n) Expand(s[i]-‘A‘); printf("The substrings of S in alphabetical order are: \\n"); DFS(1); return 0; }
样例输入
ACADD
样例输出
The substrings of S in alphabetical order are:
A
AC
ACA
ACAD
ACADD
AD
ADD
C
CA
CAD
CADD
D
DD
复杂度分析
空间复杂度 由于每次插入最多只会增加2个节点, 所以空间复杂度为 $O(n|\\sum|)$ , 最多有 $2n$ 个节点.
时间复杂度 $O(n|\\sum|)$ .
后缀树
利用 SAM 的构建方法构建后缀树
我们思考 SAM 的构建过程中, 如果根据 Suffix Link 进行连边, 那么我们会得到一棵树, 考虑这棵树的含义.
由于一棵树由点和边构成, 所以考虑这棵树的点, 以及边的含义.
思考节点的含义需要按照三个层次: ①代表着的节点有那些直观的认识; ②代表的节点的个数; ③具体代表哪些节点. 对此, 我们根据 SAM 的构建过程的理解, 给出的回答是
① 每一个节点代表着若干前缀;
② 每一个节点代表的前缀个数为 len[x] - len[suf[x]];
③ 记从根到 suf[x] 的最长路径的字符组成的字符串为 A, 从根到 x 的最长路径的字符组成的字符串为 T, 则 T = s1s2s3....snA, x代表的字符串是 snA, ..., s1s2s3..snA .
边是一个字符串 s = s1s2s3...sn.
我们发现这棵树其实就是母串 S 的前缀树. 我们知道, 后缀树是很有用的, 那能不能构建后缀树呢? 其实很简单, 只需要将母串 S 进行反序构建 SAM 即可. 但是注意, 这时候的字符串也需要反序.
广义后缀自动机
http://dwjshift.logdown.com/posts/304570
广义后缀自动机的概念
给定一棵 Trie 树, 定义 Trie 树的后缀为从某个节点到叶子节点的路径上的字符组成的字符串, 求能恰好识别 Trie 树的所有后缀的自动机.
根据这个概念, 我们还可以有另外一种定义方式: 给定 n 个字符串 s1, s2, s3, ..., sn, 求能恰好识别任意 si 的后缀的自动机, 因为将 s1, s2, ..., sn 插入到一棵 Trie 树后, 概念恰好等价.
类似的, 我们还有广义后缀数组, 也可以由两种定义方式.
广义后缀自动机的构建
广义后缀自动机的构建, 应该类比后缀自动机的构建.
但由于它是一棵树, 而不是一条链, 我们不难想到两种方法: BFS, 和 DFS.
BFS 构建 Trie 树, 或者利用已有的 Trie 树, 在树上进行 BFS , 由于字符串的长度递增, 所以直接利用 SAM 的代码即可. 时间复杂度为 $O(n|\\Sigma|)$ .
DFS 直接扫描字符串(无需构建 Trie 树), 或者利用已有的 Trie 树, 逐个字符串进行构建. 时间复杂度为 $O(n|\\Sigma|)+G(T)$ . $G(T)$ 为 Trie 树的叶子结点的深度之和.
广义后缀自动机的实现
懒癌晚期, 只写一个在线版的.
inline int Newnode(int L) { return len[++tot] = L, tot; } void Expand(int id, int c) { if (son[last][c] > 0) { int p = last, q = son[last][c]; if (len[p]+1 == len[q]) last = q; else { int nq = Newnode(len[p]+1); son[nq] = son[q]; suf[nq] = suf[q], suf[q] = nq; for (; p > 0 && son[p][c] == q; p = suf[p]) son[p][c] = nq; last = nq; } } else { int np = Newnode(len[last]+1), p = last; for (; p > 0 && !son[p][c]; p = suf[p]) son[p][c] = np; if (!p) suf[np] = 1; else { int q = son[p][c]; if (len[p]+1 == len[q]) suf[np] = q; else { int nq = Newnode(len[p]+1); son[nq] = son[q]; suf[nq] = suf[q], suf[q] = suf[np] = nq; for (; p > 0 && son[p][c] == q; p = suf[p]) son[p][c] = nq; } } last = np; } s[last].insert(id); }
以上是关于[补档计划] 字符串 之 知识点汇总的主要内容,如果未能解决你的问题,请参考以下文章