scikit-learn中的机器学习算法封装——kNN
Posted liuyt-61
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scikit-learn中的机器学习算法封装——kNN相关的知识,希望对你有一定的参考价值。
接前面 https://www.cnblogs.com/Liuyt-61/p/11738399.html
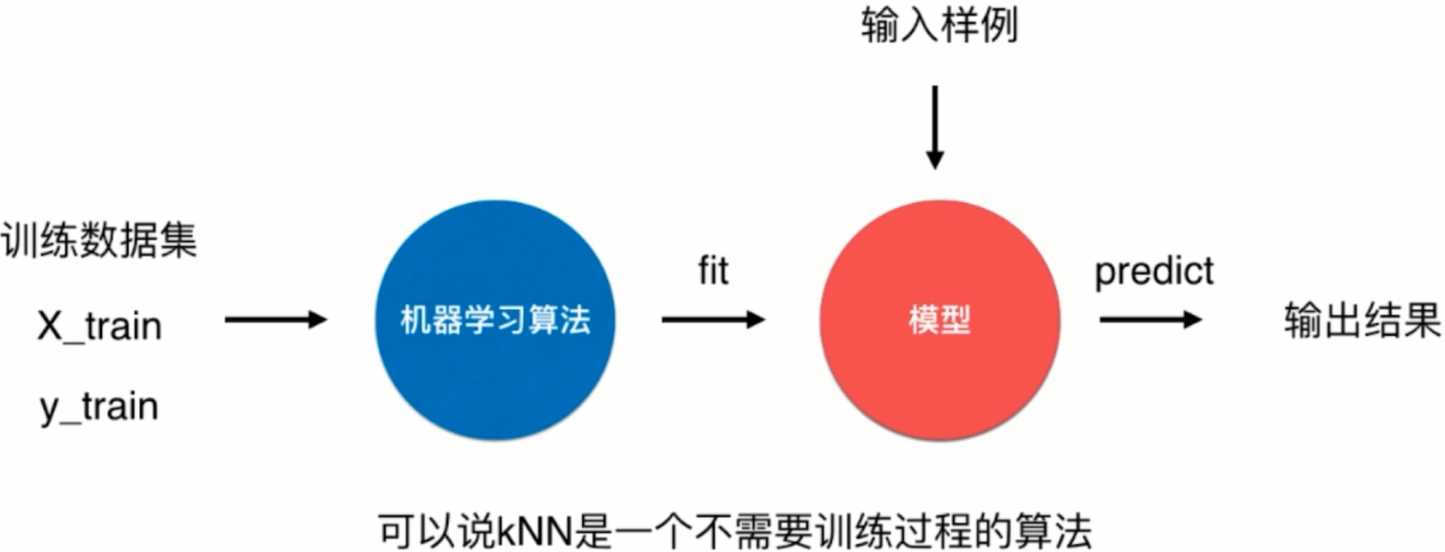
-
-
而对于kNN来说,算法的模型其实就是自身的训练数据集,所以可以说kNN是一个不需要训练过程的算法。
-
k近邻算法是非常特殊的,可以被认为是没有模型的算法
-
使用scikit-learn中的kNN实现
#先导入我们需要的包
from sklearn.neighbors import KNeighborsClassifier
#特征点的集合
raw_data_X = [[3.393533211, 2.331273381],
[3.110073483, 1.781539638],
[1.343808831, 3.368360954],
[3.582294042, 4.679179110],
[2.280362439, 2.866990263],
[7.423436942, 4.696522875],
[5.745051997, 3.533989803],
[9.172168622, 2.511101045],
[7.792783481, 3.424088941],
[7.939820817, 0.791637231]
]
#0就代表良性肿瘤,1就代表恶性肿瘤
raw_data_y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
#我们使用raw_data_X和raw_data_y作为我们的训练集
X_train = np.array(raw_data_X) #训练数据集的特征
Y_train = np.array(raw_data_y) #训练数据集的结果(标签)
#首先我们需要对包中的KNeighborsClassifier进行实例化,其中可以传入k的值作为参数
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
#然后先执行fit方法进行拟合操作得出模型,将训练数据集作为参数传入
kNN_classifier.fit(X_train,Y_train)
#执行predict预测操作,传入样本数据
#因为使用scikit-learn中的kNN算法是对一组矩阵形式的数据进行一条条的预测,所以我们传入的样本数据集参数也应该先转换为矩阵的形式
X_predict = x.reshape(1,-1) #因为我们已知我们传入的数据只有一行
y_predict = kNN_classifier.predict(X_predict)
In[1]: y_predict
Out[1]: array([1])
#所以此时的y_predict即为我们所需要的样本的预测结果
In[2]: y_predict[0]
Out[2]: 1
基于scikit-learn的fit-predict模式,进行重写我们的Python实现,进行简单的自定义fit和predict方法实现kNN
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self, k):
‘‘‘初始化KNN分类器‘‘‘
#使用断言进行判定传入的参数的合法性
assert k >= 1, "k must be valid"
self.k = k;
#此处定义为私有变量,外部成员不可访问进行操作
self._X_train = None
self._Y_train = None
def fit(seld, X_train, Y_train):
‘‘‘根据训练集X_train和Y_train训练kNN分类器‘‘‘
assert X_train.shape[0] == Y_train.shape[0], "the size of X_train must be equal to the size of Y_train"
assert self.k <= X_train.shape[0], "the size of X_train must be at least k"
self._X_train = X_train
self._Y_train = Y_train
return self
#X_predict 为传入的矩阵形式数据
def predict(self, X_predict):
‘‘‘给定待预测数据集X_train,返回表示X_predict的结果向量‘‘‘
assert self._X_train is not None and self._Y_train is not None, "must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], "the feature number of X_predict must equal to X_train"
#使用私有方法_predict(x)进行对x进行预测
#循环遍历X_predict,对其中每一条样本数据集执行私有方法_predict(x),将预测结果存入y_predict中
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
‘‘‘给定单个待预测数据x,返回x的预测结果值‘‘‘
‘‘‘此处的代码逻辑和重写之前的代码逻辑一样‘‘‘
distances = [sqrt(np.sum(x_train - x) ** 2) for x_train in self._X_train]
nearest = np.argsort(distances)
topk_y = [self._Y_train[i] for i in nearest[:self.k]]
votes = Counter(topk_y)
return votes.most_common(1)[0][0]
#重写对象的“自我描述”
def __repr__(self):
return "KNN(k=%d)" % self.k
以上是关于scikit-learn中的机器学习算法封装——kNN的主要内容,如果未能解决你的问题,请参考以下文章