Lucene初探之索引过程分析
Posted Derrick_gu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Lucene初探之索引过程分析相关的知识,希望对你有一定的参考价值。
Lucene初探之索引过程分析(一)
经过上面的学习,我们对于Lucene的索引文件的存储原理有了初步的了解,不过了解了这些只是为随后的操作Lucene打下了一个很小的基础,我们无法依靠这些知识就去自完成搜索引擎的整个设计。接下来,我们将开始深入Lucene的索引过程,进一步去深入了解Lucene的运行。
对于Lucene的索引过程,除了将词(term)写入倒排表并最终写入索引文件之外,还包括了分词与合并段的过程,后面这两个部分我们将在后面进行单独地讲解。其实有很多文章已经对索引过程有了一个非常好的讲解,比如《Annotated Lucene》。
在编程领域,想要真正地去深入了解一项技术,最好的方法就是深入代码内部,debug跟踪每一步代码的运行,毕竟语言的描述总是因人而异,但是code是不会去骗你的。
本文所分析的是Lucene3.0版本的索引过程。
- 索引过程体系结构
Lucene3.0的搜索过程是一个非常复杂的过程,各种信息数据分散在不同的对象之中进行分析、处理并写入,为了支持多线程,每一个线程都创建了一系列的结构类似的对象集,为了提高效率,需要复用一些对象集,这又使得过程变得更加地复杂。
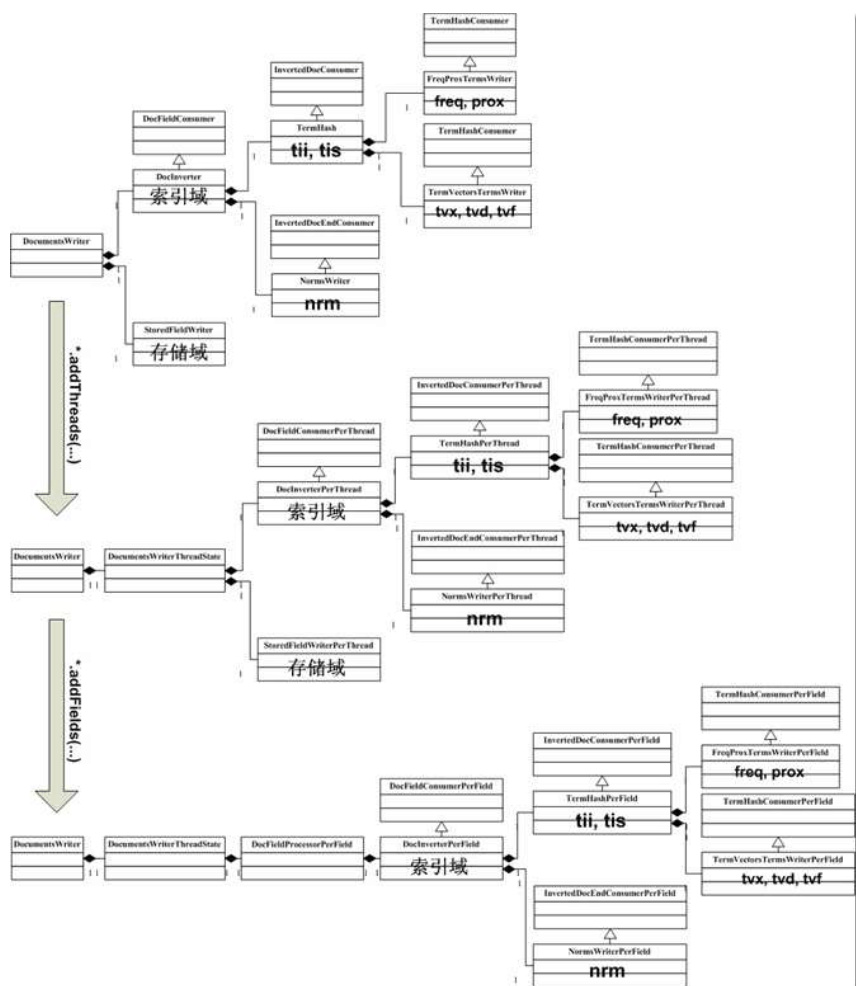
上面这幅图就是Lucene的索引过程,它是由一系列的索引链构成,索引链中的每一个节点分别负责处理索引文档的不同部分,当文档经过所有的索引链之后,就代表文档被处理完毕。最初的索引链,我们称之为基本索引链。
为了支持多线程,使得多个线程可以并发地处理文档,每个线程都需要去建立自己的索引链体系,这个索引链都是基于基本索引链而创建,被称之为线程索引链。线程索引链的每一个节点都可以在基本索引链的中找到对应的节点。事实上线程索引链的节点都是通过这些基本节点的addThreads创建的。
对于文档的域处理也一样,同样为了复用一些对象而创建相应的域索引链,这些索引链上的节点是通过线程索引链的相应节点的addFields方法产生的。
在完成对文档的处理之后,不同的信息会最终沿着基本索引链写入索引文件中,毫无疑问,这一步需要同步操作。
- 详细的索引过程
IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyer(Version.LUCENE_CURRENT), true, IndexWriter.MAXFieldLength.LIMITED);IndexWriter对象主要包含以下几个信息:
- 用于索引文档;
- 用于合并文档;
- 为了保持索引一致性,事务性和完整性;
- 一些配置信息;
以上是关于Lucene初探之索引过程分析的主要内容,如果未能解决你的问题,请参考以下文章