spark集成kerberos
Posted yjt1993
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark集成kerberos相关的知识,希望对你有一定的参考价值。
1、生成票据
1.1、创建认证用户
登陆到kdc服务器,使用root或者可以使用root权限的普通用户操作:
# kadmin.local -q “addprinc -randkey spark/yjt”
1.2、生成密钥文件
生成spark密钥文件
# kadmin.local -q “xst -norankey -k /etc/spark.keytab spark/yjt”
拷贝sparkkeytab到所有的spark集群节点的conf目录下
1.3、修改权限
# chmod 404 /data1/hadoop/spark/conf/spark.keytab
# chown hduser:hduser /data1/hadoop/spark/conf/spark.keytab
2、集群内部测试
2.1、获取票据
# klint -it /data1/hadoop/spark/conf/spark.keytab spark/yjt
(1)、本地机器测试
# spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.4.0.jar 10
(2) 、提交到yarn, 模式是client
spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.11-2.4.0.jar 10
查看8088信息:
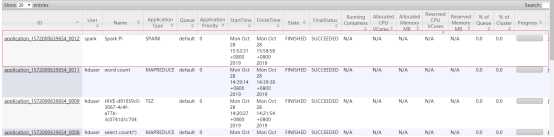
(3) 、提交到yarn集群,模式是cluster
# spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.4.0.jar 10
查看8088信息:
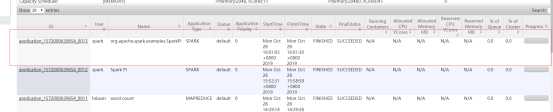
3、客户端测试
3.1、hduser用户测试
安装spark或者从集群拷贝一份到客户端
客户端测试用户使用hduser
获取票据
# kinit -kt /data1/hadoop/spark/conf/spark.keytab spark/yjt

(1) 、提交到本地集群
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master spark://192.168.0.230:7077 examples/jars/spark-examples_2.11-2.4.0.jar 10
注意:使用这种方式提交需要在集群里面的hosts文件配置客户端的主机域名映射关系。
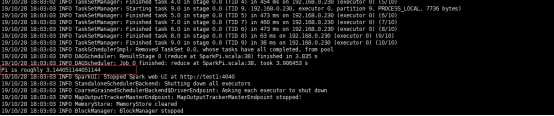
(2) 、提交到yarn,模式client
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.11-2.4.0.jar 10
注:这种方式也需要在集群内部设置客户端主机名映射关系
(3) 、提交到yarn,模式cluster
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster examples/jars/spark-examples_2.11-2.4.0.jar 10

3.2、其他用户测试
(1)、创建用户yujt
# useradd -s /bin/bash -m -d /home/yujt -G hduser yujt
# echo “Your Password” | passwd --stdin yujt
(2)、修改spark.keytab权限
# chmod 404 /data1/hadoop/spark/conf/spark.keytab
注: 以上操作root或者sudo,需要root权限
# su - yujt
(3)、修改yujt这个用户的环境变量
修改用户的~/.bashrc文件,添加如下信息:(当然最好是直接修改/etc/profile,这样在创建用户的时候就不需要为每个用户添加环境变量信息)
export JAVA_HOME=/data1/hadoop/jdk
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/data1/hadoop/hadoop
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
(4) 、测试本地standlone模式
# ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master spark://192.168.0.230:7077 examples/jars/spark-examples_2.11-2.4.0.jar 10
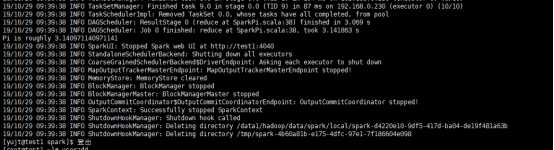
如上述,执行成功。
(5) 、测试yarn, 部署模式client
# $ ./bin/spark-submit --principal spark/yjt --keytab /data1/hadoop/spark/conf/spark.keytab --class org.apache.spark.examples.SparkPi --master yarn examples/jars/spark-examples_2.11-2.4.0.jar 10
执行结果如下:

Web界面如下:

(6) 、测试yarn, 部署模式cluster

注:上述在执行任务的时候,我们使用了--principal 和--keytab参数,其实,如果使用kinit -kt /data1/hadoop/spark/conf/spark.keytab spark/yjt获取了票据以后,可以省略这两个参数。
以上是关于spark集成kerberos的主要内容,如果未能解决你的问题,请参考以下文章