非平衡数据的处理(SMOTE算法)
Posted huangyj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了非平衡数据的处理(SMOTE算法)相关的知识,希望对你有一定的参考价值。
主要内容:
非平衡数据的特征
SMOTE算法的思想及步骤
SMOTE算法的手工案例
SMOTE算法的函数介绍
1.非平衡数据的特征
在实际应用中,类别型的因变量可能存在严重的偏倚,即类别之间的比例严重失调。如欺诈问题中,欺诈类观测在样本集中毕竟占少数;客户流失问题中,忠实的客户往往也是占很少一部分;在某营销活动的响应问题中,真正参与活动的客户也同样只是少部分。
如果数据存在严重的不平衡,预测得出的结论往往也是有偏的,即分类结果会偏向于较多观测的类。为了解决数据的非平衡问题,2002年Chawla提出了SMOTE算法,即合成少数过采样技术,它是基于随机过采样算法的一种改进方案。
2.SMOTE算法的思想及步骤
SMOTE算法的基本思想就是对少数类别样本进行分析和模拟,并将人工模拟的新样本添加到数据集中,进而使原始数据中的类别不再严重失衡。
算法步骤为:
- 采样最邻近算法,计算出每个少数类样本的K个近邻。
- 从K个近邻中随机挑选N个样本进行随机线性插值。
- 构造新的少数类样本。
- 将新样本与原数据合成,产生新的训练集。
3.SMOTE算法的手工案例
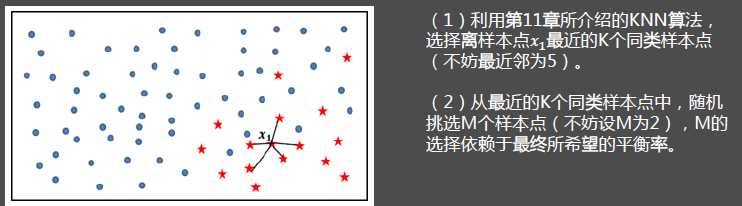


(4)重复步骤(1)、(2)和(3),通过迭代少数类别中的每一个样本????,最终将原始的少数类别样本量扩大为理想的比例。
4.SMOTE算法的函数介绍

以上是关于非平衡数据的处理(SMOTE算法)的主要内容,如果未能解决你的问题,请参考以下文章