TensorFlowCharCNN文本意图识别学习心得
Posted lemonbo77
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlowCharCNN文本意图识别学习心得相关的知识,希望对你有一定的参考价值。
本文主要阐述了我学习CharCNN过程中的心得体会以及遇到问题的处理和理解。此文基于rasa框架,查阅时需注意。
目录:
一、运用CharCNN的文本意图识别过程
二、参数的调整与对比
三、loss函数的学习
四、bug的处理和学习
一、运用CharCNN的文本意图识别过程
(1)字向量和词向量的差别在于:
①字向量相对来说字典数据条数少,占用内存小;
②不用分词,即不需要分词工具,进一步节约内存;
③需要进行多次卷积,增加了预测训练时间
④以字为单位输入的特征效果不如以词为单位,存在一定影响。
(2)实现流程:
①建立字向量字典。
在实际运用中,根据我们的场景不同对于字向量字典的需求有相应的差别。例如,家电领域和游戏领域常用字就存在一定的差异,所以在语料处理时可以根据需要进行编写。根据mitie库得到字+向量的形式组成我们需要的字向量字典。
②编写字向量生成组件。
对于CharCNN网络的运用来说,需要得到的输入应该是以向量或是矩阵形式的。机器并不能理解文字,只能通过数值计算得到结果。所以在文本意图识别,也就是文本分类的过程中,我们首先需要进行转换,将字符与字典中的key值匹配,得到相应的字向量从而组成相应的句子矩阵,之后输入网络之后进行训练。
③编写tensorflow。
一些tensorflow相关概念可以在此链接查看: https://www.cnblogs.com/lemonbo77/p/11599626.html
Ⅰ.tensorflow的结构:
- 首先需要导入库:
import tensorflow as tf
在train方法中:
- 新建一个图:
graph = tf.Graph() - with graph.as_default():
- 定义占位符 (placeholder):定义形状、数据类型,但是没有填充数据。一般用于训练的时候:训练数据和一些超参数的输入。根据需要定义相应的占位符:
X_in = tf.placeholder(dtype, shape, name)Y_in = tf.placeholder(dtype, shape, name)
is_training = tf.placeholder_with_default(False, shape=()) #此函数用于建立输出未送到时的input的占位符 - 添加CNN相关:调用conv1d、reduce_max等api构建所需要的网络结构,并根据需要进行全连接的构建
- 计算loss函数:借助了
tf.nn.softmax_cross_entropy_with_logits_v2函数(融合了交叉熵和softmax)相关可以参考:本文第四版块
- 定义操作:如初始化,训练操作
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss) #Adam优化算法:是一个寻找全局最优点的优化算法,引入了二次方梯度校正。实际操作中可以根据需要选择训练的操作算法
- 定义会话session(图必须在session中启动)
config_proto = self.get_config_proto(*) #get_config_proto函数用于对session进行参数配置 *代表相应需要填入的名称
self.session = tf.Session(graph=* , config=* ) #定义session的图来源和参数
self.session.run(tf.global_variables_initializer()) #会话进行初始化操作,初始化函数自己进行编写
for i in range(*): #循环训练模型
sess_out = self.session.run( #运行session, 执行相应的操作,不断降低loss
{‘loss‘: *, ‘train_op‘: *},
feed_dict={*} )
- 保存模型:本文是基于rasa进行的编程,所以保存模型部分代码需要写到persist方法中
saver = tf.train.Saver() #定义一个saver用于保存模型,如有多个tensor,可以指定需要保存的tensor,未指定则保存全部
saver.save(self.session, checkpoint) #保存相应的模型,save函数的参数global_step,说明是哪一步保存的模型,可以保存中间步骤模型,保存模型后可以得到四个模块:包含全部graph信息的.meta、包含所有变量和参数值的.data、包含索引文件,变量和图关系的.index、文本文件记录所有中间节点上保存模型的名称的checkpoint,首行记录是最新保存的模型名称
至此,我们便得到了一个完整的tensorflow模型,需要进行预测,就需要在process方法中将模型进行复原应用
在process方法中:
首先要在load方法中将模型加载进来:
graph = tf.Graph() #新建一个图
with graph.as_default(): #将图设为默认
sess = tf.Session(config=config_proto) #导入图,配置函数中设置了path
saver = tf.train.import_meta_graph(checkpoint + ‘.meta‘) #恢复meta
saver.restore(sess, checkpoint) #恢复图和collection到当前图中
X_in = tf.get_collection(‘message_placeholder‘)[0] #借助函数get_collection获取刚刚恢复的图中所需要的信息
... ...将所需要的信息都进行get_collection
然后在persist方法中进行预测:
- with self.graph.as_default(): #将图设为默认
- y_predict = self.session.run(self.y_predict, #通过session.run发起计算
feed_dict={self.X_in: X, self.Y_in: all_Y, self.drop_out: 0})
Ⅱ.tensorflow的shape理解:
x= tf.placeholder(tf.float32, shape=[1,2,3] )
传入的数据是三维的,那参数shape=[1,2,3]又该怎么理解呢?我们这里举一个例子:
[[1,2,3] , [4,5,6]]表示的是两行三列的矩阵,shape为[2,3]。拿掉最外层括号,得到两个元素,所以是2,对其中一个元素再拿掉一层得到三个元素,所以是3.这样理解就可以得到shape的参数。
同理,shape=[1,1,1],就是接收如[[[a]]] 这样的数据。shape=[1,2,3]接收的就是形如 [[[a,b,c],[d,e,f]]] 这样的数据。
④将语料分为测试集和数据集,进行训练和测试。
测试集和数据集一般没有交叉,若使用一样的数据集不能反应效果,所以可以通过随机取数据,将数据集分开进行测试。在rasa中通过pipeline的管控,先训练得到模型后再进行测试。训练和测试的主函数文件需要自己进行编写。
二、参数的调整与对比
三、loss函数的学习
交叉熵刻画了两个概率分布之间的距离,一个代表正确答案,一个代表的是预测值,交叉熵越小,两个概率的分布约接近。在实际字词分类时就可以运用其进行预测。
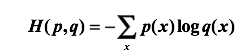
交叉熵常与softmax函数一同出现。这是由于神经网络中需要把前向传播得到的结果变成概率分布,而Softmax回归是一个非常有用的方法。
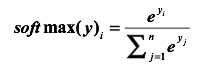
在tensorflow中使用交叉熵:
①tf.reduce_mean()求平均值,参数:tf.reduce_mean(x):求所有元素平均值;(x,0):求维度0(列)的平均值;(x,1):求维度1(列行)的平均值;tf.clip_by_value(v,a,b):把v值限制在a~b的范围内
②tf.nn.softmax_cross_entropy_with_logits(logits,labels)函数,封装了交叉熵和softmax函数
四、bug的处理和学习
(1)ValueError: Cannot feed value of shape (?,32, 271) for Tensor ‘InputData/X:0‘, which has shape ‘(?, 32,270)‘
这种bug的出现是因为数据和模型中的tensor shape不匹配。用于预测的模型所使用的训练数据和测试数据对应的字向量维度不同。
这是由于我在更新了字向量字典维数后,没有进行模型的更新,直接进行了预测。
解决方法:重新进行训练,得到新的模型再进行预测。
(2)Some of the operators in the model are not supported by the standard TensorFlow Lite runtime. ... ...
在存储tflite模型时出现了这种问题。经过排查发现,是tflite中支持的方法少于tensorflow中的方法。例如dropout方法。
查询tflite是否支持可以点击:
https://github.com/tensorflow/tensorflow/blob/6fb83aa0e3a194dcbcf8054cdd576a8d4f1d484b/tensorflow/lite/g3doc/tf_ops_compatibility.md
解决方法:找到tflite不支持的方法部分,换为可用支持方法来实现即可。
以上是关于TensorFlowCharCNN文本意图识别学习心得的主要内容,如果未能解决你的问题,请参考以下文章