深度学习之TCN网络
Posted xym4869
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习之TCN网络相关的知识,希望对你有一定的参考价值。
论文链接:https://arxiv.org/pdf/1803.01271.pdf
TCN(Temporal Convolutional Networks)
TCN特点:
- 可实现接收任意长度的输入序列作为输入,同时将其映射为等长的输出序列,这方面比较像RNN。
- 计算是layer-wise的,即每个时刻被同时计算,而非时序上串行。
- 其卷积网络层层之间是有因果关系的,意味着不会有“漏接”的历史信息或是未来数据的情况发生,即便 LSTM 它有记忆门,也无法完完全全的记得所有的历史信息,更何况要是该信息无用了就会逐渐被遗忘。
TCN组成:
[TCN = 1D FCN + causal convolutions]
TCN结构图:
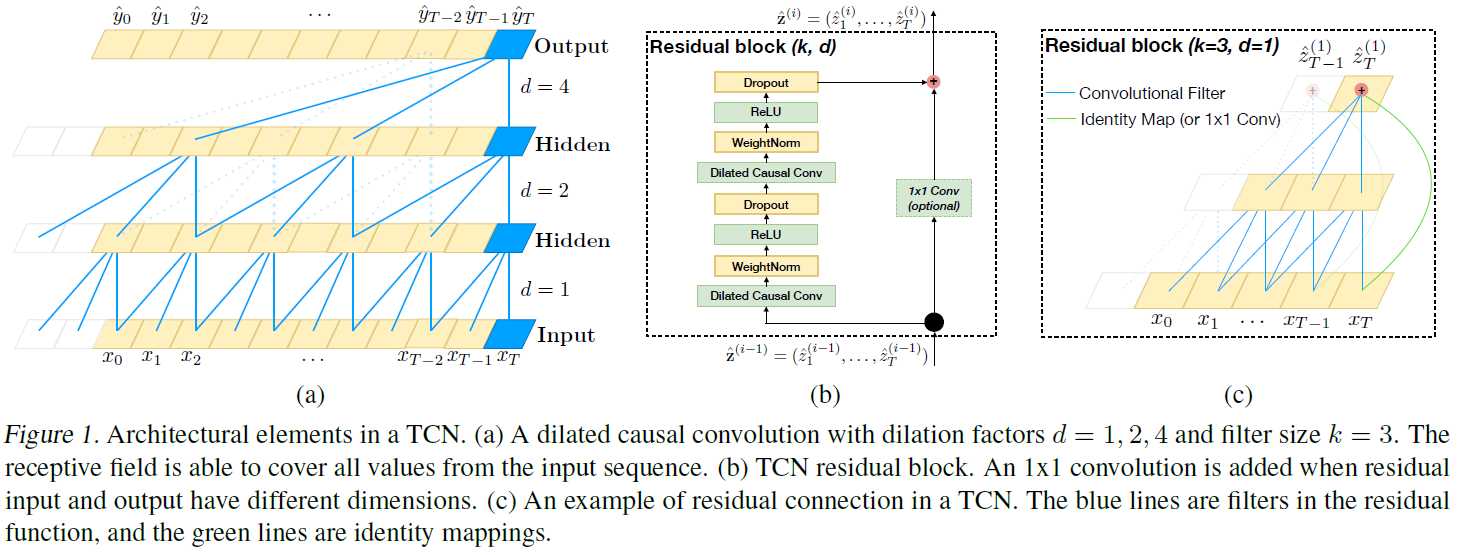
因果卷积(Causal Convolution)
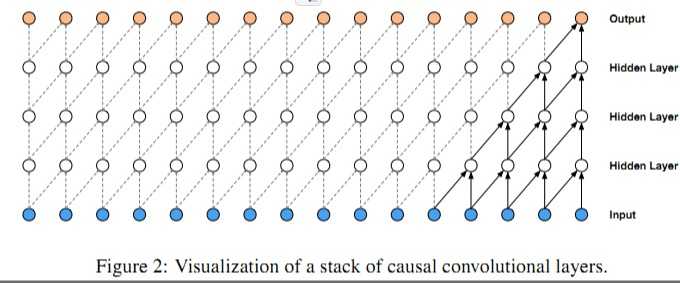
因果卷积可以用上图直观表示。 即对于上一层t时刻的值,只依赖于下一层t时刻及其之前的值。和传统的卷积神经网络的不同之处在于,因果卷积不能看到未来的数据,它是单向的结构,不是双向的。也就是说只有有了前面的因才有后面的果,是一种严格的时间约束模型,因此被成为因果卷积。
膨胀卷积(Dilated Convolution)
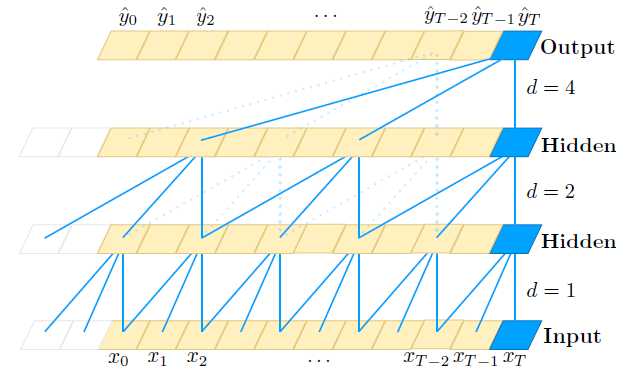
如图TCN结构图(a)。单纯的因果卷积还是存在传统卷积神经网络的问题,即对时间的建模长度受限于卷积核大小的,如果要想抓去更长的依赖关系,就需要线性的堆叠很多的层。为了解决这个问题,研究人员提出了膨胀卷积。
膨胀卷积(dilated convolution)是通过跳过部分输入来使filter可以应用于大于filter本身长度的区域。等同于通过增加零来从原始filter中生成更大的filter。
The dilated convolution operation F on element s of the sequence is defined as: [F(s)=(x*_df)(s)=overset{k-1}{underset{i=0}sum}f(i) cdot x_{s-d cdot i}]
where d is the dilation factor, k is the filter size, and (s-dcdot i) accounts for the direction of the past.
越到上层,卷积窗口越大,而卷积窗口中的“空孔”越多。d是扩展系数(即评价“空孔”的多少)。
残差链接(Residual Connections)
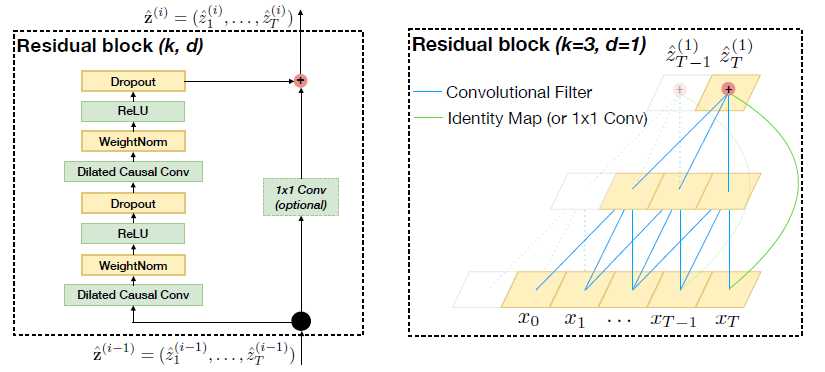
如图TCN结构图(b)。 残差链接被证明是训练深层网络的有效方法,它使得网络可以以跨层的方式传递信息。本文构建了一个残差块来代替一层的卷积。如上图所示,一个残差块包含两层的卷积和非线性映射,在每层中还加入了WeightNorm和Dropout来正则化网络。为什么要1×1卷积呢?1×1卷积是可以用来降维的 。作者直接把较下层的特征图跳层连接到上层,对应的每个Cell的特征图数量(也就是通道数channel)不一致,导致不能直接做类似Resnet的跳层特征图加和操作,于是,为了两个层加和时特征图数量吻合,用1×1卷积做了一个降维的操作。
FCN 全卷积网络
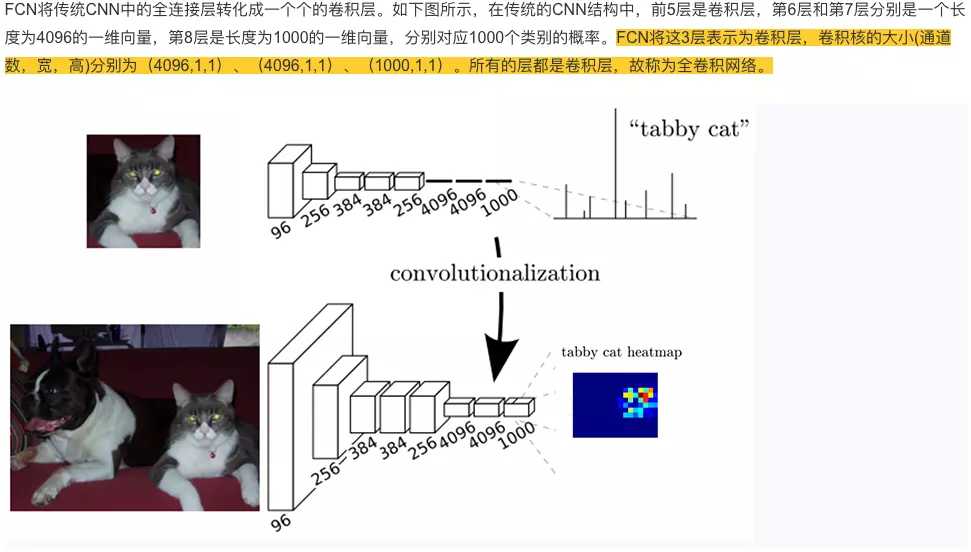
引用:
- https://blog.csdn.net/Kuo_Jun_Lin/article/details/80602776
- https://juejin.im/entry/5b1f90836fb9a01e842b1ae3
- https://www.jianshu.com/p/4280f104ddf7
- https://blog.csdn.net/qq_27586341/article/details/90751794
以上是关于深度学习之TCN网络的主要内容,如果未能解决你的问题,请参考以下文章