JDK线程池
Posted watertreestar
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK线程池相关的知识,希望对你有一定的参考价值。
简介
多线程技术主要解决处理器单元内多个线程执行的问题,它可以显著减少处理器单元的闲置时间,增加处理器单元的吞吐能力,但频繁的创建线程的开销是很大的,那么如何来减少这部分的开销了,那么就要考虑使用线程池了。线程池就是一个线程的容器,每次只执行额定数量的线程,线程池就是用来管理这些额定数量的线程
线程池相关类结构图
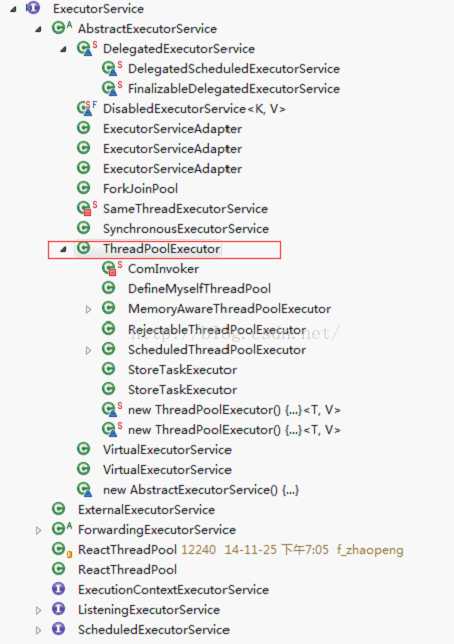
ExecutorService继承了Executor接口
Executor接口中的定义:
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
The {@code Executor} implementations provided in this package
implement {@link ExecutorService}, which is a more extensive
interface. The {@link ThreadPoolExecutor} class provides an
extensible thread pool implementation. The {@link Executors} class
provides convenient factory methods for these Executors.根据JDK源码中的注释:ExecutorService是对Executor扩展的一个接口,ThreadPoolExecutor类提供了对ExecutorService的实现,Executors类提供了方便的工厂方法
如何创建一个线程池
使用Executors工厂类来创建
Executors提供了几种创建线程池的方法:
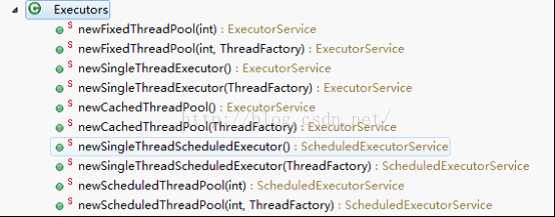
1) 创建固定大小的线程池newFixedThreadPool
@Test
public void test1(){
ExecutorService pool = Executors.newFixedThreadPool(5);
for (int i = 0;i<5;i++) {
Runnable task = new myTask();
pool.submit(task); // submit方法内部会调用execute方法
}
}
class myTask implements Runnable{
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+"正在执行........");
}
}
运行结果:
pool-1-thread-1正在执行........
pool-1-thread-2正在执行........
pool-1-thread-1正在执行........
pool-1-thread-2正在执行........
pool-1-thread-2正在执行........
pool-1-thread-2正在执行........
pool-1-thread-1正在执行........
pool-1-thread-3正在执行........
pool-1-thread-4正在执行........
pool-1-thread-5正在执行........
2) 单线程的线程池newSignleThreadExecutor
@Test
public void test2(){
ExecutorService pool = Executors.newSingleThreadExecutor();
for (int i = 0;i<10;i++) {
Runnable task = new myTask();
pool.submit(task);
}
}运行结果:
pool-1-thread-1正在执行........
pool-1-thread-1正在执行........
pool-1-thread-1正在执行........
pool-1-thread-1正在执行........
pool-1-thread-1正在执行........
pool-1-thread-1正在执行........
pool-1-thread-1正在执行........
pool-1-thread-1正在执行........
pool-1-thread-1正在执行........
pool-1-thread-1正在执行........单线程的线程池:这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行
3)newScheduledThreadPool
@Test
public void test3(){
ScheduledExecutorService pool = Executors.newScheduledThreadPool(5);
pool.schedule(new myTask(), 1000, TimeUnit.MILLISECONDS);
pool.schedule(new myTask(), 2000, TimeUnit.MILLISECONDS);
pool.shutdown();
try{
Thread.currentThread().join(5000);
}catch (Exception e) {
// TODO: handle exception
}
}等待1s后
pool-1-thread-2正在执行........
等待1s后
pool-1-thread-1正在执行........
4) 可以缓存的线程池newCachedThreadPool
@Test
public void test4(){
ExecutorService pool = Executors.newCachedThreadPool();
for (int i = 0;i<100;i++) {
Runnable task = new myTask();
pool.submit(task);
}
}
运行结果
pool-1-thread-3正在执行........
pool-1-thread-2正在执行........
pool-1-thread-1正在执行........
pool-1-thread-5正在执行........
pool-1-thread-3正在执行........
pool-1-thread-2正在执行........
pool-1-thread-7正在执行........
pool-1-thread-8正在执行........
pool-1-thread-10正在执行........
pool-1-thread-9正在执行........
pool-1-thread-13正在执行........
pool-1-thread-14正在执行........
pool-1-thread-16正在执行........
pool-1-thread-12正在执行........
pool-1-thread-17正在执行........
pool-1-thread-15正在执行........newCachedThreadPool内部调用的方法:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
可缓存的线程池:如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制
官方建议程序员使用较为方便的Executors工厂方法Executors.newCachedThreadPool()(无界线程池,可以进行自动线程回收)、Executors.newFixedThreadPool(int)(固定大小线程池)Executors.newSingleThreadExecutor()(单个后台线程),这几种线程池均为大多数使用场景预定义了默认配置。
继承ThreadPoolExecutor类,并复写父类的构造方法
ThreadPoolExecutor的构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}前面的Executors工厂类中创建线程池的几个工厂方法内部都是调用了此构造方法
先看看这个构造方法的参数的含义:
corePoolSize--池中所保存的线程数,包括空闲线程。
maximumPoolSize--池中允许的最大线程数。
keepAliveTime--当线程数大于corePoolSize时,此为终止空闲线程等待新任务的最长时间。
Unit--keepAliveTime 参数的时间单位。
workQueue--执行前用于保持任务的队列。此队列仅保持由 execute方法提交的 Runnable任务。
threadFactory--执行程序创建新线程时使用的工厂。
Handler--由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序。这几个参数之间的关系
接下来,咋们来说下这几个参数之间的关系。当线程池刚创建的时候,线程池里面是没有任何线程的(注意,并不是线程池一创建,里面就创建了一定数量的线程),当调用execute()方法添加一个任务时,线程池会做如下的判断:
- 如果当前正在运行的线程数量小于corePoolSize,那么立刻创建一个新的线程,执行这个任务。
- 如果当前正在运行的线程数量大于或等于corePoolSize,那么这个任务将会放入队列中。
- 如果线程池的队列已经满了,但是正在运行的线程数量小于maximumPoolSize,那么还是会创建新的线程,执行这个任务。
- 如果队列已经满了,且当前正在运行的线程数量大于或等于maximumPoolSize,那么线程池会根据拒绝执行策略来处理当前的任务。
- 当一个任务执行完后,线程会从队列中取下一个任务来执行,如果队列中没有需要执行的任务,那么这个线程就会处于空闲状态,如果超过了keepAliveTime存活时间,则这个线程会被线程池回收(注:回收线程是有条件的,如果当前运行的线程数量大于corePoolSize的话,这个线程就会被销毁,如果不大于corePoolSize,是不会销毁这个线程的,线程的数量必须保持在corePoolSize数量内).为什么不是线程一空闲就回收,而是需要等到超过keepAliveTime才进行线程的回收了,原因很简单:因为线程的创建和销毁消耗很大,更不能频繁的进行创建和销毁,当超过keepAliveTime后,发现确实用不到这个线程了,才会进行销毁。这其中unit表示keepAliveTime的时间单位,unit的定义如下:
线程池队列BlockingQueue
类结构图
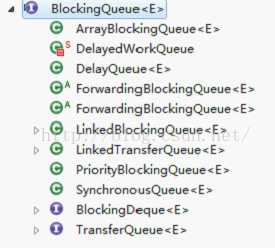
SynchronousQueue
该队列对应的就是上面所说的直接提交,首先SynchronousQueue是无界的,也就是说他存数任务的能力是没有限制的,但是由于该Queue本身的特性,在某次添加元素后必须等待其他线程取走后才能继续添加
LinkedBlockingQueue
有界队列
构造方法
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
/**
* Creates a {@code LinkedBlockingQueue} with the given (fixed) capacity.
*
* @param capacity the capacity of this queue
* @throws IllegalArgumentException if {@code capacity} is not greater
* than zero
*/
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}
/**
* Creates a {@code LinkedBlockingQueue} with a capacity of
* {@link Integer#MAX_VALUE}, initially containing the elements of the
* given collection,
* added in traversal order of the collection's iterator.
*
* @param c the collection of elements to initially contain
* @throws NullPointerException if the specified collection or any
* of its elements are null
*/
public LinkedBlockingQueue(Collection<? extends E> c) {
this(Integer.MAX_VALUE);
final ReentrantLock putLock = this.putLock;
putLock.lock(); // Never contended, but necessary for visibility
try {
int n = 0;
for (E e : c) {
if (e == null)
throw new NullPointerException();
if (n == capacity)
throw new IllegalStateException("Queue full");
enqueue(new Node<E>(e));
++n;
}
count.set(n);
} finally {
putLock.unlock();
}
}ArrayBlockingQueue
有界队列
构造方法
public ArrayBlockingQueue(int capacity) {
this(capacity, false);
}
/**
* Creates an {@code ArrayBlockingQueue} with the given (fixed)
* capacity and the specified access policy.
*
* @param capacity the capacity of this queue
* @param fair if {@code true} then queue accesses for threads blocked
* on insertion or removal, are processed in FIFO order;
* if {@code false} the access order is unspecified.
* @throws IllegalArgumentException if {@code capacity < 1}
*/
public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
}
public ArrayBlockingQueue(int capacity, boolean fair,
Collection<? extends E> c) {
this(capacity, fair);
final ReentrantLock lock = this.lock;
lock.lock(); // Lock only for visibility, not mutual exclusion
try {
int i = 0;
try {
for (E e : c) {
checkNotNull(e);
items[i++] = e;
}
} catch (ArrayIndexOutOfBoundsException ex) {
throw new IllegalArgumentException();
}
count = i;
putIndex = (i == capacity) ? 0 : i;
} finally {
lock.unlock();
}
}
fair表示队列获取线程的策略是FIFO还是无序
线程池的拒绝执行策略
当线程的数量达到最大值时,这个时候,任务还在不断的来,这个时候,就只好拒绝接受任务了
ThreadPoolExecutor 允许自定义当添加任务失败后的执行策略。你可以调用线程池的 setRejectedExecutionHandler()方法,用自定义的RejectedExecutionHandler 对象替换现有的策略ThreadPoolExecutor提供的默认的处理策略是直接丢弃,同时抛异常信息,ThreadPoolExecutor 提供 4 个现有的策略,分别是:
ThreadPoolExecutor.AbortPolicy:表示拒绝任务并抛出异常
ThreadPoolExecutor.DiscardPolicy:表示拒绝任务但不做任何动作
ThreadPoolExecutor.CallerRunsPolicy:表示拒绝任务,并在调用者的线程中直接执行该任务
ThreadPoolExecutor.DiscardOldestPolicy:表示先丢弃任务队列中的第一个任务,然后把这个任务加进队列
以上是关于JDK线程池的主要内容,如果未能解决你的问题,请参考以下文章