猫眼的数字解密
Posted 542684416-qq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了猫眼的数字解密相关的知识,希望对你有一定的参考价值。
话不多说,直接干货走起:
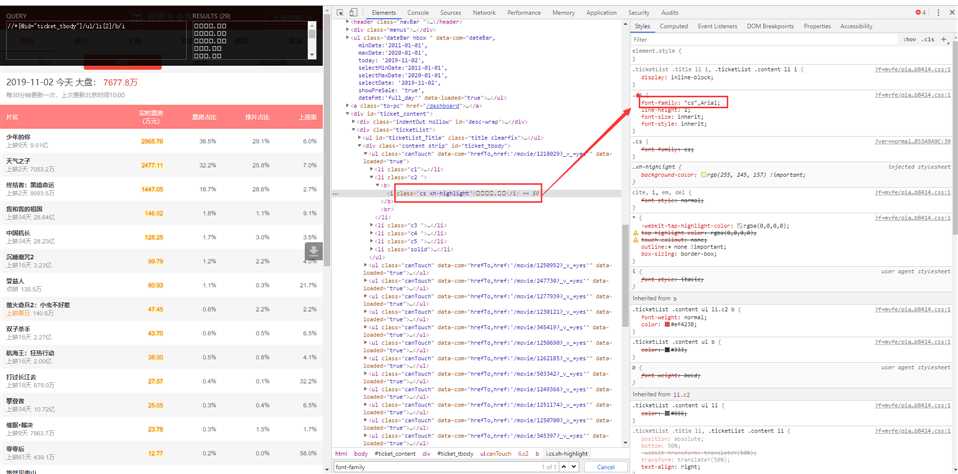
看到了吗?字体加密了。那就找。。定位到加密字体的地方,然后看右边的styles,你是不是看到了与字体相关的名字—font-family,就是他,复制他然后源码里面全局搜索,你会看到如下东西:
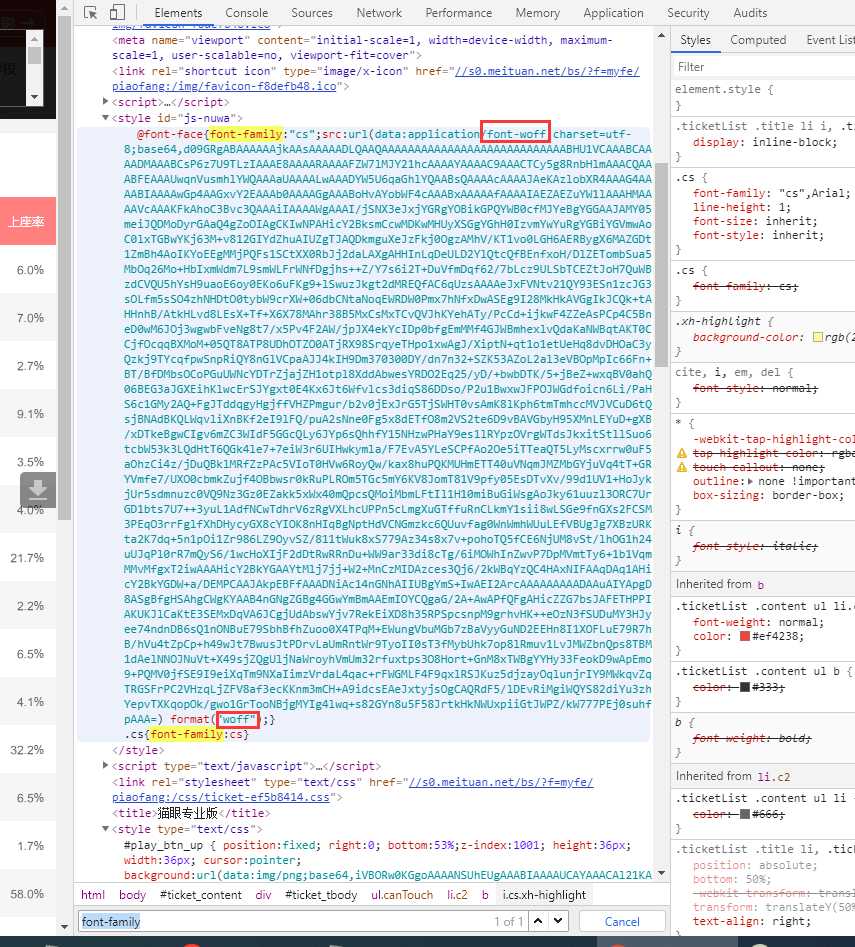
woff?就是这个字体文件。正则拿下来,接下来是正题
# 获取源码里面的字体加密源码 base_str = re.findall(r"base64,(.*?))",response.text)[0]
将base64编码的字体字符串解码成为二进制格式,写成.woff文件,再通过BytesIO把一个二进制内存块当成一个文件来操作
def make_font_file(base64_string: str): #将base64编码的字体字符串解码成为二进制格式 bin_data = base64.decodebytes(base64_string.encode()) with open(‘testotf.woff‘,‘wb‘) as f: f.write(bin_data) return bin_data def convert_font_to_xml(bin_data): #BytesIO把一个二进制内存块当成一个文件来操作 font = TTFont(BytesIO(bin_data)) #将解码字体保存为xml font.saveXML(‘test1.xml‘)
再用画笔把他画出来,顺便使用pytesseract库把他识别出来
def draw(path): #接下来就是画字体了 #创建一张空的画板,大小为80*30,默认填充为白色 im = Image.new(‘RGB‘,(90,30),(255,255,255)) #获取绘制的上下文环境(绘制的起始地址) dr = ImageDraw.Draw(im) #创建要绘制的字体 font = ImageFont.truetype(BytesIO(make_font_file(base_str)),18) #开始绘制(10,5)是起始绘制坐标,fill指明字体的填充色为黑色 dr.text((10,5),text,font=font,fill="#000000") im.save(‘hh.jpg‘) result = pytesseract.image_to_string(path).replace(‘ ‘,‘.‘) return result
这样就可以得到解码后的数字了。。
不过毕竟识别肯定不是百分之百能成功的。另外还有一种可以完全实现,但是他的对应关系还没找到,搞了一半,半成品(我发现这个可以https://www.jianshu.com/p/5aa978e9823d)不过又验证了一下,发现他的字体库是在变化的,所以说这个好像不可以用了。
base_str1 = ‘d09GRgABAAAAAAjoAAsAAAAADMAAAQAAAAAAAAAAAAAAAAAAAAAAAAAAAABHU1VCAAABCAAAADMAAABCsP6z7U9TLzIAAAE8AAAARAAAAFZW7lgXY21hcAAAAYAAAAC8AAACTG3tR1lnbHlmAAACPAAABFsAAAU8N3aJFmhlYWQAAAaYAAAALwAAADYW4w2KaGhlYQAABsgAAAAcAAAAJAeKAzlobXR4AAAG5AAAABIAAAAwGp4AAGxvY2EAAAb4AAAAGgAAABoIkgcwbWF4cAAABxQAAAAfAAAAIAEZAEZuYW1lAAAHNAAAAVcAAAKFkAhoC3Bvc3QAAAiMAAAAWgAAAI/VTcOReJxjYGRgYOBikGPQYWB0cfMJYeBgYGGAAJAMY05meiJQDMoDyrGAaQ4gZoOIAgCKIwNPAHicY2BksmCcwMDKwMHUyXSGgYGhH0IzvmYwYuRgYGBiYGVmwAoC0lxTGBwYKn5MZdb5r8MQw6zDcAUozAiSAwDmCAuqeJzFksEJg0AQRf9Gs4maQ44BO5AUYQuCVViBDZgKYiM5BavxLoIK4t7MX8dLQK/JLG9h/iwzw8wCOAJwyJ24gHpDwdqLqlp0B/6iu3jQv+FK5Yy8rpq4jTrdZ0M4FlNiUlPOM1/sR7ZMMePWsRHN7hzWPSHAgTV9eJT1TqYfmPpf6W+7LPdz9QKSr7DFuhI4PzSxYPfcRoLdd6cFu/M+EzhnDKFgc46FwNljSgRuASYV7L8wpQDvA79tPsh4nE2US2/jVBTH73ViO86rDXHstEmTxklsx07cvHydJnUebSbptJO+J606LW1pNUPpFDqPBbNgpIEZDSA0mh18ANjwWhUkNgioEBukQUi8xAJYsOMrkOHm0RHXkqV7ZN/z+//PORdAAJ7+A7KABQQARs7HhlgZ4GXB8e8JF/EdGAEJMAmAV9TzBsplec7H0iGIX5RESTiIDI7nclkDGXkxStEUb2FxgC9DA+UlUaCpz16enNxbmisd1xu1uavHC2hWpYQIysSCZD2HxgW3GhWjyrjuU1T1XqAAbyWOV4qZQrF1lOBemNmttFx00zxo7n1kaM9Fwpl0nR5XQp1P5SbLWq0cKz/QYgrqMne1/Eo4MbOOtQyodAxBC7RB8bksMjQYxUS0hPpSeA7LoLmuJioqiJLxwB+MGdWkKitmIO61WKjiFYapVlJRwbHpKZbaU5l8IDDCoVos9s7Rzj1m87QlCDGzUJZTVvsGA6caSjXMLQxvpbMBb7bYFiNBG5qY3Xl4a8nV4/uN8BBfgPiAD/X5pB6TN0KTNOIxGHfurvSWXZzQaqlUMnkhOaL6Vi/AY2vnTzkiROM79/OtOzczVfKThiC4o/mNaU2Fw3zYD48uur6NQuf9w/1W2+Eo1NawN0Qvtxt7EwM5bJUoiT0n3NCHIXjEczSLN1EBl1QcmAPZEOyaNvgWvu/k/NNqRHe5XBFtIne5MmsZC12budGqDm3Xb68bhrPzWG5KxirDyAlTKyYIRufFkVAxtFbQPAJD16YPa5VSZWX5659215DS7pyl1pNbi/PpRDI5qN9fuH5nwI/7zSB9XTzM2K/X4CFTFvi7EBMaYZ931LYNSfeYxwxFIkLnPWJ/l2nGM+m789LC1g2rhFD54X5JKOvu/tl/EyTWnwEgTkdwLxvis1N1JEbF//VF1//z3Lg/aJKwwk7QYR+DibFEYEpOuxVi0axJEtxiyvrN6yXT457gZjKJUW7IyVA8vDbV5uTRqCs9zkUyohiazOlzbj3etB/qSK+ua4ZfC9YSAs878XKRfb6f4V3iCRgCgKS93bx9tgr0wlfm7XJBL3AzRZ4fI/NUjCJaYS7LXvWXw5Tss/3rB89qzGCNPMBD7O393m9zHzsE8ZHd8ko5vDfwZEgIb3DQp5K+mFqav20GPcMUG0wXll4yZ4m2TRm7ZCqq3a4mKpW4Bhffbl7MqtvqtHlSRsvPy+qlzR8+nGnQ2cbpqVlimHz9y3OG7r0hAtTvcpwNXwZlaMK80ZWlQXxp5LLdOwQ3HG4uyYD9IaV4tju0SH/kDIUzaigsuyka10opXHnt9YPGq+bUnfqBbjjaMKAok6aWJBSUKy+/2/By5JDgrabHC34HSamBUZvtjesnb7YeP3j0wYYNCet22KhqGWtmYmlWSW7O9zl/wV6dAUfPcYOUIO/J0RIv6R6LAcu+zld2uGKe2LaHX/zjx9HPmT34xNXJrlq/sT2FlzsfM+A/GuL2mQB4nGNgZGBgAOLNnQdmxvPbfGXgZmEAgZsPn/xE0P/PsDAwnQdyORiYQKIAi1MOHgB4nGNgZGBg1vmvwxDDwgACQJKRARXwAAAzYgHNeJxjYQCCFAYGJkviMABCNgK3AAAAAAAAAAwAZgC2APQBRgF0AcQB5gIoAnwCngAAeJxjYGRgYOBhsGJgZgABJiDmAkIGhv9gPgMAD30BYAB4nGWRu27CQBRExzzyAClCiZQmirRN0hDMQ6lQOiQoI1HQG7MGI7+0XpBIlw/Id+UT0qXLJ6TPYK4bxyvvnjszd30lA7jGNxycnnu+J3ZwwerENZzjQbhO/Um4QX4WbqKNF+Ez6jPhFrp4FW7jBm+8wWlcshrjQ9hBB5/CNVzhS7hO/Ue4Qf4VbuLWaQqfoePcCbewcLrCbTw67y2lJkZ7Vq/U8qCCNLE93zMm1IZO6KfJUZrr9S7yTFmW50KbPEwTNXQHpTTTiTblbfl+PbI2UIFJYzWlq6MoVZlJt9q37sbabNzvB6K7fhpzPMU1gYGGB8t9xXqJA/cAKRJqPfj0DFdI30hPSPXol6k5vTV2iIps1a3Wi+KmnPqxVhjCxeBfasZUUiSrs+XY82sjqpbp46yGPTFpKr2ak0RkhazwtlR86i42RVfGn93nCip5t5gh/gPYnXLBAHicbcg7DoAgEIThHV8o4l2AsIilRL2LjZ2JxzcurX/zZYYqKmn6z6BCjQYtOij0GKAxwmAiPOq+zoMTf+6bX2VbG2XnYEWby+9icWYnpoWLHETvMtELFxwXaAAA‘ baseFont = TTFont(BytesIO(make_font_file(base_str))) def decode_font_advance(font_str): match_font = TTFont(BytesIO(make_font_file(font_str))) numDic = {} uniList = match_font[‘cmap‘].tables[0].ttFont.getGlyphOrder()[1:] baseNumList = [‘.‘, ‘4‘, ‘7‘, ‘8‘, ‘9‘, ‘0‘, ‘6‘, ‘2‘, ‘1‘, ‘5‘, ‘3‘] baseUnicode = [‘x‘,‘uniEBDD‘,‘uniECB5‘,‘uniEBC9‘,‘uniF0D3‘,‘uniECCE‘,‘uniEE54‘,‘uniE90C‘,‘uniE027‘,‘uniE4BF‘,‘uniE791‘] for i in range(11): #找到相应字形对应绘制图元的对象 matchGlyph = match_font[‘glyf‘][baseUnicode[i]] for j in range(11): baseGlyph = baseFont[‘glyf‘][baseUnicode[j]] #如果相应绘制图元相等,认为两个字形相等 if matchGlyph == baseGlyph: #从已知对应关系列表中查出对应文字 numDic[uniList[i]] = baseNumList[j] print(numDic[uniList[i]],baseNumList[j]) break result = ‘‘ j = 0 # 标记小数点位置 for i in range(len(text)): if text[i] != ‘.‘: num = ‘uni‘ + text[i].encode(‘unicode-escape‘).decode()[2:].upper() if num in numDic: result += numDic[num] else: j = i result = result[0:j] + ‘.‘ + result[j:] return result
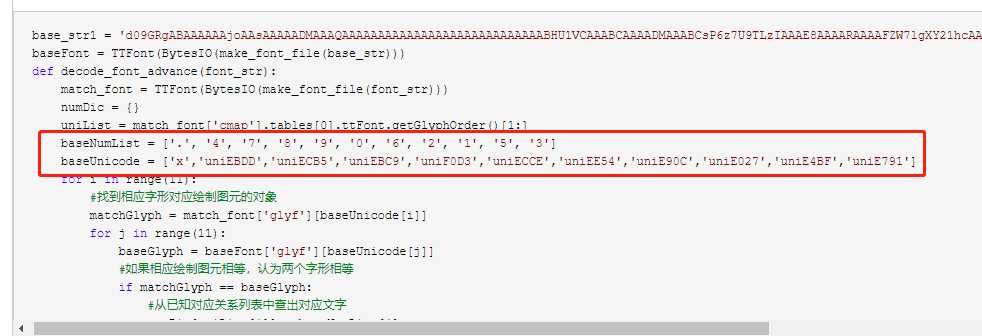
这一块的对应关系不对,所以这个暂时可以不用!!
到这里,肯定都是想要源码的,这里直接贴上
import re import base64 import requests import lxml.html from io import BytesIO from fontTools.ttLib import TTFont from PIL import Image,ImageDraw,ImageFont from pytesseract import pytesseract #fontTools 对字体进行分析解析及创建 #PIL(pillow)图片处理库 #base64 对base64字符串进行编码和解码 #pytesseract python 提供的一个操作tesseract库的封装 #tesseract 进行文字OCR(将图片的文字转换为文本)识别的机器学习库 tts(将语音转换为文本或文本转换为语音) #字体文件本质是编码到绘制方式的一种映射方式,同时存储了字体的绘制矩阵 #动态获取base_str headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0s",} url = ‘http://piaofang.maoyan.com/?ver=normal&isid_key=3190FDABF3E3F4F3418B832814041F0672068ADD771BC8B0E93C6FD1B53A9A9C‘ # url = ‘http://piaofang.maoyan.com/?ver=normal‘ response = requests.get(url=url,headers=headers) tree = lxml.html.fromstring(response.text) #获取加密字体列表里面的数字是可以自己选择,一次只能走一个 text = tree.xpath(‘//div[@id="ticket_tbody"]/ul[@class="canTouch"]/li/b/i/text()‘)[0].strip() # 获取源码里面的字体加密源码 base_str = re.findall(r"base64,(.*?))",response.text)[0] def make_font_file(base64_string: str): #将base64编码的字体字符串解码成为二进制格式 bin_data = base64.decodebytes(base64_string.encode()) with open(‘testotf.woff‘,‘wb‘) as f: f.write(bin_data) return bin_data def convert_font_to_xml(bin_data): #BytesIO把一个二进制内存块当成一个文件来操作 font = TTFont(BytesIO(bin_data)) #将解码字体保存为xml font.saveXML(‘test1.xml‘) #先把拿到的字体源码生成xml格式的,你可以进去看一下里面是什么 def draw(path): #接下来就是画字体了 #创建一张空的画板,大小为80*30,默认填充为白色 im = Image.new(‘RGB‘,(90,30),(255,255,255)) #获取绘制的上下文环境(绘制的起始地址) dr = ImageDraw.Draw(im) #创建要绘制的字体 font = ImageFont.truetype(BytesIO(make_font_file(base_str)),18) #开始绘制(10,5)是起始绘制坐标,fill指明字体的填充色为黑色 dr.text((10,5),text,font=font,fill="#000000") im.save(‘hh.jpg‘) result = pytesseract.image_to_string(path).replace(‘ ‘,‘.‘) return result if __name__ == ‘__main__‘: convert_font_to_xml(make_font_file(base_str)) print(draw(‘hh.jpg‘))
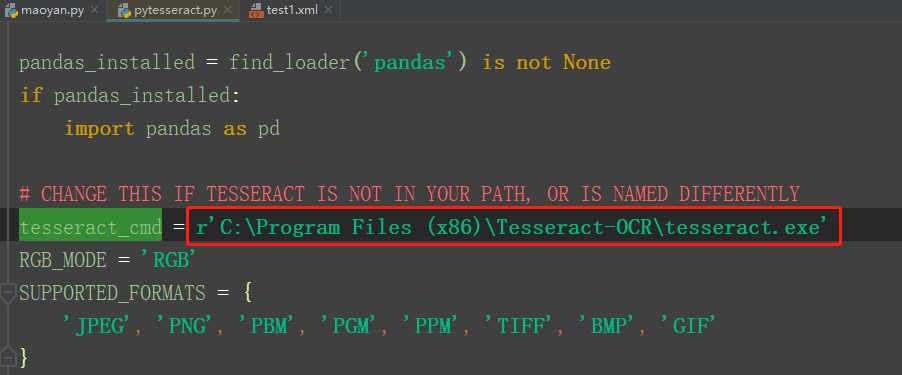
我知道你还缺少pytesseract 库,https://digi.bib.uni-mannheim.de/tesseract/直接下载吧,记得下载完,修改一下pytesseract.py这个文件下的tesseract_cmd,这个后面跟你的路径
以上是关于猫眼的数字解密的主要内容,如果未能解决你的问题,请参考以下文章
Android 高级UI解密 :PathMeasure截取片段 与 切线(新思路实现轨迹变换)