字符集和字符编码的区别
Posted maidongdong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字符集和字符编码的区别相关的知识,希望对你有一定的参考价值。
转自:https://www.cnblogs.com/xdyixia/p/9114145.html
1、字符,字符集,字符编码概念
字符:在计算机和电信技术中,一个字符是一个单位的字形、类字形单位或符号的基本信息。即一个字符可以是一个中文汉字、一个英文字母、一个阿拉伯数字、一个标点符号等。
字符集:多个字符的集合。例如GB2312是中国国家标准的简体中文字符集,GB2312收录简化汉字(6763个)及一般符号、序号、数字、拉丁字母、日文假名、希腊字母、俄文字母、汉语拼音符号、汉语注音字母,共 7445 个图形字符。
字符编码:把字符集中的字符编码为(映射)指定集合中的某一对象(例如:比特模式、自然数序列、电脉冲),以便文本在计算机中存储和通过通信网络的传递。
字符集和字符编码的关系 :
字符集是书写系统字母与符号的集合,而字符编码则是将字符映射为一特定的字节或字节序列,是一种规则。通常特定的字符集采用特定的编码方式(即一种字符集对应一种字符编码(例如:ASCII、ios-8859-1、GB2312、GBK,都是即表示了字符集又表示了对应的字符编码,但Unicode不是,它采用现代的模型)),因此基本上可以将两者视为同义词。
2、发展过程
(1)单字节
ASCII(American Standard Code for Information Interchange),128个字符,用7位二进制表示(00000000-01111111即0x00-0x7F);
EASCII(Extended ASCII),256个字符,用8位二进制表示(00000000-11111111即0x00-0xFF)。
(3)多字节
当互联网席卷了全球,地域限制被打破了,不同国家和地区的计算机在交换数据的过程中,就会出现乱码的问题,即对同一组二进制数据,不同的编码会解析出不同的字符。
通用字符集UCS(Universal Character Set)
对应两种编码:对每一个字符采用四个8比特字节编码的称为UCS-4,对每一个字符采用两个8比特字节编码的称为UCS-2。
UNICODE字符集
有多个编码方式,分别是UTF-8,UTF-16,UTF-32编码。
UTF-8:被定义为将代码点编码为1至4个字节,具体取决于代码点数值中有效位的数量。
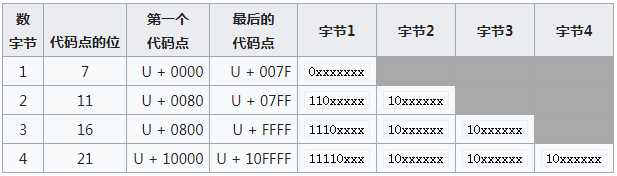
前128个字符(US-ASCII)需要一个字节。接下来的1,920个字符需要两个字节进行编码,其中涵盖了几乎所有拉丁字母字母的其余部分,还包括希腊语,西里尔语,科普特语,亚美尼亚语,希伯来语,阿拉伯语,叙利亚语,塔那那语和N‘Ko字母以及组合变音词马克。剩余基本多语言平面中的字符需要三个字节,其中几乎包含所有常用字符,包括大多数字符中文,日文和韩文字符。Unicode的其他平面中的字符需要四个字节,其中包括不常见的CJK字符,各种历史脚本,数学符号和表情符号(象形符号)。
注意:虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是 最节省的。不过另一方面,值得说明的是,虽然utf编码对汉字使用3个字节,但即使对于汉字网页,utf编码也会比unicode编码节省,因为网页中包 含了很多的英文字符。
UTF-16:2个字节
UTF-32:4个字节
例:“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是

3、什么是BOM
BOM(Byte Order Mark)字节序(字节顺序的标识),其实就是用大端还是小端。
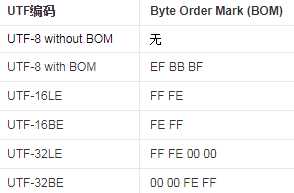
java中,UTF-8缺省不带BOM
UTF-8中有一字节的情况,这种情况,就没有两端的说法了。至于另外的二,三,四字节情况,以三字节为例,如果你一定要弄出端法,也不是说不可以,比如,小端法就是“小-中-大”,大端法就是“大-中-小”。但现实情况是UTF-8仅仅采用了一种端法,就是大端法。
参考:
https://www.jianshu.com/p/bd7a6c508c33
https://www.cnblogs.com/happyday56/p/4135845.html
https://blog.csdn.net/u012268339/article/details/54694310
https://en.wikipedia.org/wiki/Unicode
https://baike.baidu.com/item/Unicode/750500?fr=aladdin
以上是关于字符集和字符编码的区别的主要内容,如果未能解决你的问题,请参考以下文章